机器学习中的Hello World
机器学习中的入门项目
# Load libraries
import pandas as pd
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
%matplotlib inline# Load dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# url = "iris.data"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pd.read_csv(url, names=names)2. 查看数据集的一些基本信息
从以下步骤开始:
- 看数据集的维度
- 看部分的数据,有一个直观的印象
- 数值型属性的统计描述
- 通过不同标签来看数据
2.1 数据的维度
通过这个步骤可以很快了解数据集的样本数量(行)和属性的个数(列)
# shape
dataset.shape(150, 5)也就是说该数据中有150行,也就是150个样本数据,以及5个属性(包括标签列)。
2.2 数据集的部分数据
看数据集的部分数据,可以对数据集中的数据有一个直观的印象。
使用tail看数据集末尾的数据,用head可以看数据开头的数据。
# head
print(dataset.head(5)) sepal-length sepal-width petal-length petal-width class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa2.3 数值型属性的统计描述
通过describe命令查看各个数值型属性的个数、均值、最小最大值以及各分位数。
注意:只有数值型的属性才有,描述性的属性不会出现在下面的列表中。
# descriptions
print(dataset.describe()) sepal-length sepal-width petal-length petal-width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.5000002.4 标签分布
统计一下各个标签有多少个样本数据
# class distribution
print(dataset.groupby('class').size())class
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
dtype: int643. 数据可视化
为了能够更清楚的看数据,我们用图来展示一下。这个部分是可选的,用图只是为了更好的看。
两类图:
- 单变量的图用来看单独的变量有什么特点
- 多变量的图用来看各个变量之间的关系
3.1 单变量图
给各个变量画一个箱线图,通过该图可以看单个变量的区间和数据的一些分布情况。
# box and whisker plots
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
plt.show()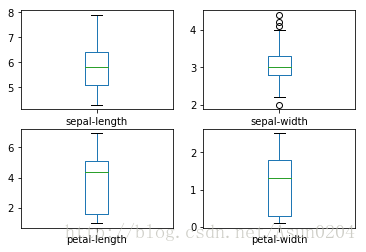
给各个变量画一个直方图,用来观察各个数值区间的数据分布情况,可以看到大致成一个中间多两边小的高斯分布,有些算法是需要高斯分布假设的。
# histograms
dataset.hist()
plt.show()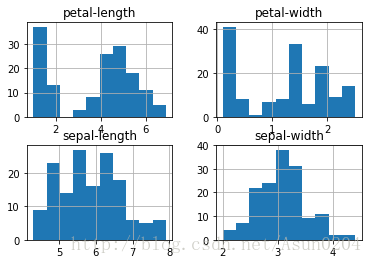
3.2 多变量图
先画两两变量的散点图。
注意一些一些属性对的对角线分组,这表明高相关性和可预测的关系。
# scatter plot matrix
scatter_matrix(dataset)
plt.show()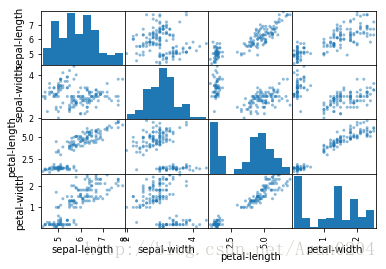
4. 评估一些算法
用一些算法来构建分类模型,并评价各个算法的性能。
下面是处理的步骤:
- 拆分出验证集
- 用十折交叉验证计算算法性能
- 用了5个算法来分类
- 挑选一个最好的模型
4.1 构造验证集
我们需要知道我们建的模型是不是任何情况下都是好用的。
之后,我们将使用统计方法来估计没有拿来训练过的的数据上创建的模型的准确性。我们还希望通过对没有拿来训练过的数据进行评估,对未知数据的最佳模型的准确性进行更具体的估计。
也就是说,我们将保留一些数据不用来训练算法,用独立的数据来衡量模型预测的准确性。
把原来的数据集80%作为训练集,20%作为验证集。
# Split-out validation dataset
array = dataset.values
X = array[:,0:4]
Y = array[:,4]
validation_size = 0.20
seed = 7
X_train, X_validation, Y_train, Y_validation = model_selection.train_test_split(X, Y, test_size=validation_size, random_state=seed)4.2 测试方法
使用十折交叉验证来计算模型的准确性。
把训练集分成10份,用其中9份来训练模型,然后在剩下的1份来计算模型性能得分,重复十次取平均即是模型的最后得分。
使用准确率来作为模型的度量分数指标,准确率是指分类正确的个数占所有需分类样本的比率。
# Test options and evaluation metric
seed = 7
scoring = 'accuracy'4.3 构建模型
从多变量图中可以看到一些属性是部分线性的关系,所以我们想要得到一个通常意义上好的结果。
使用如下几种算法:
- 逻辑回归(LR)
- 线性判别分析(LDA)
- 最近邻(KNN)
- 分类回归树 (CART)
- 高斯朴素贝叶斯 (NB)
- 支持向量机(SVM)
其中LR和LDA是线性的,其他是非线性的,这是一个比较好的组合。固定了采样的随机数种子,能够保证每次采样的样本都是相同的,计算出来的分数也不会有随机性。
# Spot Check Algorithms
models = []
models.append(('LR', LogisticRegression()))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC()))
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = model_selection.KFold(n_splits=10, random_state=seed)
cv_results = model_selection.cross_val_score(model, X_train, Y_train, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg)LR: 0.966667 (0.040825)
LDA: 0.975000 (0.038188)
KNN: 0.983333 (0.033333)
CART: 0.975000 (0.038188)
NB: 0.975000 (0.053359)
SVM: 0.991667 (0.025000)4.4 挑选一个最好的模型
从准确率得分中可以看到KNN的性能最好。因为是十折交叉验证,所以可以计算均值,即准确率,和方差来比较模型的好坏。
# Compare Algorithms
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()
5. 模型预测
在验证集上运行该模型。
在一个独立的数据集上做一个最后的检验,这是很有必要的,可以防止过拟合和数据泄漏。
在验证集上运行,计算准确率、混淆矩阵和一个分类报告。
可以看到准确率是0.9,或者90%,混淆矩阵是TP、FP等,分类报告给出了3类花分别的精度、召回率、F1值以及样本个数。最后一行是用support加权平均计算出来的。
# Make predictions on validation dataset
knn = KNeighborsClassifier()
knn.fit(X_train, Y_train)
predictions = knn.predict(X_validation)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))0.9
[[ 7 0 0]
[ 0 11 1]
[ 0 2 9]]
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 7
Iris-versicolor 0.85 0.92 0.88 12
Iris-virginica 0.90 0.82 0.86 11
avg / total 0.90 0.90 0.90 30一些问题
- 关于训练集、验证集和测试集,本教程的例子中作用区分不明显有点混乱,参考文献[2]是维基百科上关于这三个集作用的划分
- 一般把标签也量化成数值型的,而不是直接用字符型
- 导包中的%matplotlib inline用于jupyter notebook的显示图片,如果单独在python运行请删除
学习方向
- 数据预处理,例如缺失值、描述变量的转化、编码等
- 特征工程,选择特征、构造特征等
- 模型学习和参数选择,学习算法原理,调整算法参数
- 集成方法,如bagging、stacking等用来组合多个模型的结果
- …
参考资料:
[1] https://machinelearningmastery.com/machine-learning-in-python-step-by-step/
[2] https://en.wikipedia.org/wiki/Training,_test_and_validation_sets#Training_set