3.函数重载
函数名可以看做是一个操作的名字。通过这些名字,可以写出易于人们理解和修改的程序。但是有的编程语言规定每个函数只能有唯一的标识符。如果想打印三种不同类型的数据:
整型、字符型和实型,则不得不用三个不同的函数名,如Print_int()、Print_char()和Print_float(),这样显然增加了编程的工作量。针对这类问题,也就是当函数实现的是同一类功能,只是部分细节不同(如参数的个数或参数类型不同)时,C++提供了函数重载机制,即将这些函数取成相同的名字,从而使程序易于阅读和理解,方便记忆和使用。
函数重载是指两个或两个以上的函数具有相同的函数名,但参数类型不一致或参数个数不同。编译器根据实参和形参的类型及个数进行相应地匹配,自动确定调用哪一个函数。使得重载的函数虽然函数名相同,但功能却不完成相同。函数重载是C++对C语言的扩展,包括非成员函数的重载和成员函数重载。
3.1 非成员函数重载
非成员函数重载是指对用户所编写的那些功能相同或类似、参数个数或类型不同的用户自定义函数,在C语言中必须采用不同的函数名加以区分,而在C++中可以采用相同的函数名,从而提高程序的可读性。
#include <iostream>
using namespace std;
class Complex
{
private:
double real;
double imag;
public:
Complex(double r, double i);
Complex(double r);
Complex();
~Complex(){
cout << "destructor" <<endl;
}
void Print();
Complex add(Complex a);
};
Complex::Complex(double r, double i)
{
real = r;
imag = i;
cout << "Constructor:Two" <<endl;
}
Complex::Complex(double r)
{
real = r;
imag = 0;
cout << "Constructor:One" <<endl;
}
Complex::Complex()
{
real = 0;
imag = 0;
cout << "Constructor:Zero" <<endl;
}
Complex Complex::add(Complex a)
{
Complex temp;
temp.real = this->real + a.real;
temp.imag = this->imag + a.imag;
return temp;
}
void Complex::Print()
{
cout <<real;
if(imag > 0)
cout << "+";
if(imag != 0)
cout << imag << "i" <<endl;
}
int main()
{
Complex com1(1.1, 2.2),com2(3.3, 4.4),com3(4.4),total;
total = com1.add(com2);
total.Print();
total = com1.add(com3);
total.Print();
return 0;
}注意:(1)重载函数必须具有不同的参数个数或不同的参数类型,若只是返回值的类型不同或形参名不同是不行的。
(2)重载函数应满足:函数名相同,函数的返回值类型可以相同也可以不同,但各函数的参数表中的参数个数或类型必须有所不同。这样才能进行区分,从而正确的调用函数。
(3)不要将不同功能的函数定义为重载函数,以免产生误解。
如:int f(int a, int b)
{
return a+b;
}
double f(double a, double b)
{
return a*b;
}创建重载函数时,必须让编译器能区分两个(或更多)的重载函数,当创建的多个重载函数,编译器不能区分时,编译器就认为这些函数具有多义性,这些函数调用是错误,编译器不会编译该程序。
#include <iostream>
using namespace std;
float mul(float x)
{
return 2*x;
}
double mul(double x);
{
return 2*x;
}
int main()
{
cout << mul(10.4) <<endl;
cout << mul(10) <<endl; //产生二义性,编译器不知道该怎么处理10
return 0;
}3.2 成员函数重载
成员函数的重载主要是为了适应相同成员函数的参数多样性。成员函数重载的一个很重要的应用就是重载构造函数。创建一个对象时,有可能需要带参数,也有可能不需要带参数,或是带的参数的个数不一样。通过对构造函数进行重载,可以实现定义对象时初始化赋值的多样性。
#include <iostream>
using namespace std;
int mul(int x, int y)
{
return x*y;
}
double mul(double x, double y)
{
return x*y;
}
int main()
{
int x,y;
double a,b;
cout << "Input x,y:" <<endl;
cin >> x >> y;
cout << "x*y = " << mul(x,y) <<endl;
cout << "Input a,b:" <<endl;
cin >> a >> b;
cout << "a*b = " << mul(a,b) <<endl;
return 0;
}3.3 函数的默认参数
在C++中,提供了默认参数的做法,也就是允许在函数的声明或定义时给一个或多个参数指定默认值。这样在函数调用时,如果不给出实际参数,则可以按指定的默认值进行工作。
如:Complex(double r = 0, double i = 0)当进行调用时,编译器会按从左到右顺序将实参与形参结合,若未指定足够的实参,则编译器按顺序用函数原型中的默认值来补足所缺少的实参。
Complex(3.5, 9.6); // r = 3.5 i = 9.6
Complex(3.5); // r = 3.5 i = 0
Complex(); // r = 0 i = 0(1)当函数既有原型声明又有定义时,默认参数只能在原型声明中指定,而不能在函数定义中指定。例如:
Complex (double r = 0, double i = 0);
Complex (double r = 0, double i = 0) //错误情况
{
...
}(2)在函数原型中,所有取默认值的参数都必须出现在不取默认值的参数的右边。也就是一旦开始定义默认值得参数,在其后面就不能再说明不取默认值得参数了。
void fun(int i, int j = 5, int k); //错误
void fun(int i, int k, int j = 5);(3)在函数调用时,若某个参数省略,则其后的参数皆应该省略而采用默认值。不允许某个参数省略后,在给其后的参数指定参数值。如:Complex( , 9.6) //错误形式
(4)当函数的重载带有默认参数时,要注意避免二义性。
如:Complex(double r, double i = 0);
Complex(double r); 是错误的。因为如果函数调用Complex(3.5),编译器将无法确定调用哪一个函数。函数的带默认参数值的功能可以在一定程度上简化程序的编写。
3.4 内联函数
在程序设计中,效率是一个重要的指标。在C中,提高效率的一个方法是使用宏。宏可以不用函数调用,但看起来像函数调用。宏的实现是用预处理器。预处理器直接用宏代码代替宏调用,因此就不需要函数调用所需的保存调用时的现场状态和返回地址、进行参数传递等时间花费。然而,C++的预处理器不允许存取私有数据。这意味着预处理器宏在用作成员函数时变得非常无用。为了既保证预处理器宏的效率有增加安全性,而且还能像一般成员函数一样可以在类里访问自如,因此C++引入了内联函数。内联函数是一个函数,它与一般函数的区别是在使用时可以像宏一样展开,所以没有函数调用的开销。通过内联函数,它把函数体的代码直接插入到调用处,将调用函数的方式改为顺序执行直接插入的程序代码,减少了程序的执行时间(但也增加了代码的实际长度)。因此,使用内联函数可以提高系统的执行效率。但在内联函数体中,不能含有复杂的结构控制语句,如switch和while语句等。内联函数实际上是一种空间换时间的方案,因此其缺点是增大了系统空间方面的开销。在类内给出函数体定义的成员函数被默认为内联函数。
内联函数的定义格式:
inline 返回值类型 函数名(形参表)
{
//函数体
}#include <iostream>
using namespace std;
inline char trans(char ch)
{
if(ch >='a' && ch <='z')
return ch-32;
else
return ch+32;
}
int main()
{
char ch;
while((ch = getchar()) != '\n')
cout <<trans(ch);
cout <<endl;
return 0;
}(1)内联函数代码不宜太长,而且不能含有复杂的分支或循环等语句。
(2)在类内定义的成员函数默认为内联函数。
(3)在类外定义时,则必须加上关键字inlin。否则,编译器会将它作为普通成员函数对待。
(4)递归调用的函数不能定义为内联函数。
4.常量与引用
4.1 const的最初动机
for(int i = 0; i <= 100; i++)
{
...
}这段代码存在一个可读性问题。100作为循环范围的目的是什么?另一个问题是维护性问题,假设程序代码中有很多地方要用到100这个数字,如果发生改动,则要明白每个100的具体作用,哪些需要修改,哪些不需要修改。解决的办法是帮它取一个名字,即值替代的方式,做到见名知义。可以使用C语言中的:#define MAX 100。
4.1.1 由define引发的问题
首先看define会引发的错误:
#define fun(a) a*5
...
int s = fun(3+5)设计的目的是要得到结果(3+5)*5=40,然而结果是28!
在define预处理机制中,编译器仅把fun(a)当做是一个名字来对待,它替代的是数字(或公式)a*5。预处理过程中,编译器既不对其做类型检查,也不对其分配存储空间,当调用fun(a)时,仅仅对fun(a)中的符号做简单的替换处理,转换成:fun(a) = 3+5*5。编译器永远也看不到fun(a)这个符号,因为在预处理过程中被替换掉了。
4.1.2 const使用方法
使用const的好处是它允许指定一种语意上的约束:某种对象不能被修改,而由编译器具体来实施这种约束。通过const,可以通知编译器和其他程序员某个值要保持不变。只要是这种情况,应明确的使用const,因为这样做可以借助编译器的帮助确保这种约束不被破坏。
声明格式:const 类型名 对象名; 如:const int MAX = 100;
表明可以在编译器知道的任何地方使用MAX。
注意:(1)尽量把const定义放进头文件里,由此通过包含头文件,把const定义放在一个需要放置的地方,并由编译器分配给它一个编译单元。C++中const为内部连接,即由const定义的常量仅在被定义的文件才能看到,而不会被其他文件看到,除非使用extern!一般情况下,编译器不为const分配空间(而extern则强制分配空间)。
(2)当定义一个const常量时,必须初始化,除非用extern做了清楚的说明:
extern const int bufsize;
常量的使用一是消除不安全因素,二是消除存储和读操作,使代码的执行效率更高。
const int Datalist[] = {5,8,11,14};
Struct Mystruct {int i; int j;}
const struct Mystruct sList[] = {{1,2},{3,4}};
char cList[Datalist[1]]; //错误
float fList[sList[0].i]; //错误错误的原因在于,在编译时编译器必须为数组分配固定大小的内存空间。而使用const修饰的数组意味着“不能被改变”的一块存储区,其值在编译期间不能被使用。
4.2 const与指针
const与指针的结合使用,有两种情况:一是用const修饰指针,即修饰存储在指针里的地址;二是修饰指针指向的对象。为了防止混淆使用,采用“靠近”原则,即const离哪个量近则修饰哪个量。如果const修饰符离变量近,则表达的意思为指向常量的指针;如果离指针近,则表示指向变量的常指针。
指向常量的指针定义格式:
const 类型名 *指针变量名;
const int *p;表明p是一个指针,是一个指向const int的指针。即p指向一个整型常量,这个常量当然不能被改变,但是p可以“被改变”。
常指针定义格式:
类型名 *const 指针名;
int i = 4;
int *const q = &i;表明q是一个常指针,一个指向int类型的变量i的const指针,q必须有一个初始值,它只能指向这个初始值对象i,不能“被改变”而指向其他对象,但所指向的对象的值可以被改变。
i= 5;
*q = 6;可以使用一个常指针指向一个变量,也可以把非const对象变为const对象。
int i = 4;
int *const p = &i; //可以用const指针指向一个非const对象
const int *const q = &i; //可以把非const对象地址赋给const对象指针也可以用指向字符的指针来指向字符串,例如:
char *p = “hello!”;此处,p为非const指针,指向非const数据(虽然”hello”为常量),但编译器把它当成非常量来处理,指针指向它在内存中的首地址。虽然没有语法错误,但是不建议这样使用。如果想用指针指向字符串常量,可以这样:
const char *q = “hello!”; //非const指针,const数据
const char *const p = “hello!”; //const指针,const数据注意:可以把非const数据对象地址赋给const指针,但是不能把const对象的地址赋给指向非const对象的指针。
int i = 5;
const int j = 3;
int *p = &i;
//int *q = &i; //错误,把const对象的地址赋给指向非const对象的指针
int *s = (int *)&j; //强制转换,合法4.3 const与函数
4.3.1 const类型参数
定义格式: 返回值类型 函数名称(const 类型 参数名, ...)
void f(const int j)
{
i++; //错误
}
void f(const int *p)
{
(*p)++; //错误
}表示参数i的初始值在函数f()中不能被改变。对于传递地址类型的参数,而又不想让使用者在函数中改变参数值时,要用const修饰。
4.3.2 const类型返回值
可以用const修饰符修饰函数的返回值,即函数返回一个常量,此常量既可以赋给常量,也可以赋给变量。
int res()
{
return 5;
}
const int conres()
{
return 5;
}
int main()
{
int j = res();
j++;
const int i = res(); //正确,函数返回值赋值给常量
int k = conres(); //正确,把常量的值赋给变量
k--; //正确,变量变化
const int f = conres(); //正确,常量赋值给常量
return 0;
}常对象的使用
#include <iostream>
using namespace std;
class Tcons
{
int iData;
public:
Tcons(int i = 0):iData(i){}
void Seti(int i)
{
iData = i;
cout << "iData:" << iData <<endl;
}
};
Tcons test1()//返回普通对象
{
return Tcons();
}
const Tcons test2()//返回常对象
{
return Tcons();
}
int main()
{
test1() = Tcons(10);
//正确,test1函数返回一个Tcons对象,并把对象Tcons(10)的值赋给它
test1().Seti(20);
//正确,调用test1(),得到一个返回对象,并调用此对象的成员函数
//test2() = Tcons(10); //错误,常对象不能被修改
//test2().Seti(20); //错误,常对象内容不能被修改
return 0;
}4.3.3 const在传递地址中的应用
在函数的实参与形参结合时的传递地址的过程中,对于在被调用的函数中不需要修改的指针或对象,用const修饰是合适的。
#include <iostream>
using namespace std;
void test(int *p){}
void testpointer(const int *p)
{
//(*p)++; //错误,不允许修改常量内容
int i = *p; //正确,常量赋值给变量
//int *q = p; //错误,不能把一个指向常量的指针赋值给一个指向非常量的指针
}
const char *teststring()
{
return "hello!";
}
const int *const testint()
{
static int i = 100;
return &i;
}
int main()
{
int m = 0;
int *im = &m;
const int *cim = &m; //正确,可以把非常量的地址赋给一个指向常量的指针
test(im);
//test(cim); //错误,不能把指向常对象的指针赋值给指向非常对象的指针
testpointer(im);
testpointer(cim);
//char *p = teststring();//错误,不能把指向常对象的指针赋值给指向非>常对象的指针
const char *q = teststring();
cout << *q <<endl;
//int *ip = testint(); //错误,不能把指向常对象的指针赋值给指向非>常对象的指针
const int *const ipm = testint();
cout << *ipm <<endl;
const int *iqm = testint();
cout << *iqm <<endl;
//*testint() = 10; //错误,因为testint()返回值指向常量的指针,其内容不能被修改
return 0;
}Test()是一个有普通指针参数的函数,而testpointer()是一个带有指向常量指针参数的函数,因此testpointer()函数中试图修改const内容时会发生错误。
函数teststring()返回值为地址,表明编译器为字符串常量分配的地址。此时const修饰显得很重要;否则,如果允许执行语句char *p = teststring();,将会导致通过指针p来修改“常量”的内容而发生错误。
而函数testint()返回的指针不仅是常量,而且指向的空间为静态的,函数不随着调用的结束而释放指针所指向的空间,调用结束后仍然有效。需要注意的是,函数testint()的返回值类型为const int*const,它可以赋值给const int* const类型的,也可以赋值给const int*类型的(编译器不报错,因为返回值是拷贝方式),第二个const的含义仅当返回量出现在赋值号左边时(*testint()=10),const才显示它的含义,编译器才会报错。
4.4 const与类
const在类里有两种应用:一是在类里建立类内局部常量,可用在常量表达式中,而常量表达式在编译期间被求值;二是const和类成员函数的结合使用。
4.4.1 类内const局部常量
在一个类里使用const修饰的意思是“在这个对象寿命期内,这是一个常量”。然而,对这个常量来说,每个不同的对象可以含一个不同的值。
在类里建立一个const成员时不能赋初值,只能在构造函数里对其赋初值,而且要放在构造函数特殊的地方。因为const必须在创建它的地方被初始化,所以在构造函数的主体里,const成员必须已被初始化。
如:
class conClass
{
const int NUM; //不能赋初值
public:
conClass();
};
conClass::conClass():NUM(100){}常用的一个场合就是在类内声明一个常量,用这个常量来定义数组的大小,从而把数组的大小隐藏在类里。
错误示例:
class conClass
{
const int NUM = 100;
int iData[NUM];
public:
conClass();
};以上为错误情形。因为在类中进行存储空间分配,编译器不能知道const的内容是什么,所以不能把它用做编译期间的常量。在类里const的意思是“在这个特定对象的寿命期内,而不是对于整个类来说,这个值是不变的(const)”。
两种解决办法
静态常量。为了提高效率,保证所有的类对象最多只有一份拷贝值,通常需要声明为静态的。
class Student
{
static const int NUM = 30;
int iScorelist[NUM];
...
};程序中的NUM,不是定义,而是一个声明,所以在类外还需要加上定义:
const int Student::NUM;老版本的编辑器不会接受上面的语法,因为它认为类的静态成员在声明时定义初始值是非法的;而且类内只允许初始化整数类型(如int、bool、char等),且只能是常量。
enum(枚举)
class Student
{
enum{NUM = 30};
int iData[NUM];
public:
conClass();
};4.4.2 常对象与常成员函数
像声明一个普通的常量一样,可以声明一个复杂的对象为常量。
const int i = 10;
const conClass cTest(10);因为声明cTest为const类型,所以必须要保证在对象cTest的整个生命周期内不能被改变。对于公有数据很容易做到,然而对于私有数据,如何保证每个成员函数的调用也不改变?需要声明成员函数为const类型,等同于告诉编译器此类的一个const对象可以调用这个成员函数,而const对象调用非const成员函数则不行。
const成员函数定义格式:
class 类名
{
...
返回值类型 成员函数名称(参数列表)const;
...
};如在函数的前面加上const,表明函数返回值为const,为了防止混淆,把const放在函数的后面。在一个const成员函数里,试图改变任何数据成员或调用非const成员函数,编译器都将给出出错信息。
#include <iostream>
#include <string.h>
using namespace std;
class Student
{
int no;
char name[20];
public:
Student();
int Getno()const;
const char* Getname();
void Print()const;
};
Student::Student()
{
no = 1;
strcpy(name, "wang");
}
int Student::Getno()const
{
return no;
}
const char* Student::Getname()
{
return name;
}
void Student::Print()const
{
cout << "No:" << no << " Name:" << name <<endl;
}
int main()
{
Student s1;
s1.Getno();
s1.Getname();
const Student s2;
s2.Getno();
//s2.Getname(); //错误,常对象调用非const成员函数
s2.Print();
return 0;
}如果真的想改变常对象的某些数据成员怎么办?有两种方法:一是强制转换;二是使用mutable。
#include <iostream>
using namespace std;
class Test
{
int i,j;
public:
Test():i(0),j(0){}
void f()const;
};
void Test::f()const
{
//i = 1; //错误,在常成员函数中修改类成员
((Test*)this)->j = 5;//强制转换
cout << "I:" << i << " J:" << j <<endl;
}
int main()
{
const Test t;
t.f();
return 0;
}#include <iostream>
using namespace std;
class Test
{
int i;
mutable int j;
public:
Test():i(0),j(0){}
void f()const;
};
void Test::f()const
{
//i = 1; //错误,在常成员函数中修改类成员
j = 5;
cout << "I:" << i << " J:" << j <<endl;
}
int main()
{
const Test t;
t.f();
return 0;
}4.5 引用(&)
在C++中,当函数参数采用传值方式传送时,除非明确指定,否则函数的形参总是通过对“实参的拷贝”来初始化的,函数的调用者得到的也是函数返回值的拷贝。传值方式采用位拷贝方式,使得运行效率低下。虽然通过指针传递地址的方式提高了运行效率,但是相比引用而言,代码不够简洁明了。引用是C++的一大特点,是支持C++运算符重载的语法基础,也为函数参数的传入与传出提供了便利。如果不想改变参数,则可通过常量引用传递。(位拷贝拷贝的是地址,而值拷贝则拷贝的是内容。)
4.5.1 引用的概念
引用被认为是某个变量或对象的别名,引用定义格式:
类型名 & 引用名 = 被引用的对象名称;
引用就像给原来的对象起了一个“绰号”,访问引用时,实际访问的就是被引用的变量或对象的存储单元。
#include <iostream>
using namespace std;
int main()
{
int i = 0;
int &j = i;
cout << "i=" << i << ",j=" << j <<endl;
i++;
cout <<"i=" << i << ",j=" << j <<endl;
j++;
cout <<"i=" << i << ",j=" << j <<endl;
return 0;
}引用就像一个自动能被编译器逆向引用的常量型指针。它通常用于修饰函数的参数和函数的返回值,但也可以独立使用。
(1)当引用被创建时,它必须被初始化(指针则可以在任何时候被初始化)。
(2)没有NULL引用。必须确保引用是和一个合法的存储单元关联。
(3)一旦一个引用被初始化为指向一个对象,它就不能被改变为对另一个对象的引用(指针可以在任何时候指向另一个对象)。
#include <iostream>
using namespace std;
int main()
{
int one;
int &r = one;
one = 5;
cout << "One:\t" << one <<endl;
cout << "R:\t" << r <<endl;
cout << "&One:\t" << &one <<endl;
cout << "&R:\t" << &r <<endl;
int two = 64;
r = two;
cout << "\nOne:\t" << one <<endl;
cout << "Two:\t" << two <<endl;
cout << "R:\t" << r <<endl;
cout << "&One:\t" << &one <<endl;
cout << "&R:\t" << &r <<endl;
cout << "&Two:\t" << &two <<endl;
return 0;
}当我看到这个代码的时候,我以为r = two;是改变为对另一个对象的引用,其实不是这样的,r = two;只是赋值而已,可以看到&One和&R一直没变。
当定义一个引用时,必须被初始化指向一个存在的对象。
int n;
int &m = n;
//int &j; //错误,没有初始化
int x= 5;
int &y = x;
int &z = y;使用引用的时候要注意:
(1)不能建立引用数组。
(2)不能建立引用的引用。
int iData[5];
//int &icData[5] = iData; //错误
int i;
//int &&j = i;4.5.2 引用与指针
引用与指针有着本质的区别,指针通过变量的地址来间接访问变量,而引用通过变量的别名来直接访问变量。
#include <iostream>
using namespace std;
int main()
{
int i = 0;
int *p = &i;
int &c = i;
cout << "i=" << i << ",*p=" << *p << ",c=" << c <<endl;
(*p)++;
cout << "i=" << i << ",*p=" << *p << ",c=" << c <<endl;
c++;
cout << "i=" << i << ",*p=" << *p << ",c=" << c <<endl;
return 0;
}#include <iostream>
using namespace std;
void changpointer1(int **x)
{
(*x)++;
**x = 1;
}
void changpointer2(int*& x)
{
x++;
*x = 2;
}
int main()
{
int idata[3] = {0};
int *p = idata;
int i;
for(i = 0; i < 3; i++)
cout << "idata [" << i << "]=" << idata[i] << " ";
cout <<endl;
changpointer1(&p);
for(i = 0; i < 3; i++)
cout << "idata [" << i << "]=" << idata[i] << " ";
cout <<endl;
p = idata;
changpointer2(p);
for(i = 0; i < 3; i++)
cout << "idata [" << i << "]=" << idata[i] << " ";
cout <<endl;
return 0;
}4.5.3 引用与函数
采用引用的主要用途之一就是做函数的参数使用。
#include <iostream>
using namespace std;
void swappointer(int *x, int *y)
{
int z;
z = *x;
*x = *y;
*y = z;
}
void swapcite(int &x, int &y)
{
int z;
z = x;
x = y;
y = z;
}
int main()
{
int i = 10,j = 20;
int m = 10,n = 20;
swappointer(&i, &j);
swapcite(m, n);
cout << "i=" << i << ",j=" << j <<endl;
cout << "m=" << i << ",n=" << j <<endl;
return 0;
}当函数的返回值为引用方式时,需要特别注意的是,不要返回一个不存在的或已经销毁的变量的引用。
int& tcite2()
{
int m = 2;
//return m; //错误,调用完函数tcite2()后,临时对象m将被释放,返回值为一个空引用
static int x = 5;
return x;
}
int* tpointer(int *p)
{
(*p)++;
return p;
}
int& tcite(int &c)
{
c++;
return c;
}
int main()
{
int i;
tpointer(&i);
tcite(i);
return 0;
}
对常量引用的例子
void t1(int &){}
void t2(const int&){}
int main()
{
//t1(1); //错误,在函数t1()中,可以修改参数内容,而1为常量
t2(1); //正确,在函数t2()中,参数声明为常量
}C语言中,如果设计者想改变指针本身,而不是改变指针指向的内容,则使用指向指针的指针;而在C++中可以使用简洁的引用来实现。
4.6 复制构造函数
复制构造函数:是一种特殊的构造函数,其形参是本类的对象的引用,其作用是使用一个已经存在的对象,去初始化一个新的同类对象,在以下三种情况下会被调用:①当用一个已经存在的对象,去初始化该类的另一个对象时。②如果函数的形参是类对象,调用函数进行形参和实参结合时。③如果函数的返回值是类对象,函数调用完成返回时。
在编程过程中可以根据情况定义复制构造函数,以实现同类对象之间数据成员的传递。如果没有定义类的复制构造函数,系统会在必要时自动生成一个隐含的复制构造函数。这个隐含的复制构造函数的功能是,把初始值对象的每个数据成员值都复制到新建的对象中。
#include <iostream>
using namespace std;
/*
class 类名
{
public:
类名(形参表);
类名(类名&对象名);
...
};
类名::类名(类名&对象名);
{
函数体
}
*/
class Point
{
public:
Point(int xx = 0, int yy = 0)
{
x = xx;
y = yy;
}
Point(Point &p);
int getx()
{
return x;
}
int gety()
{
return y;
}
private:
int x, y;
};
Point::Point(Point &p)
{
x = p.x;
y = p.y;
cout << "Calling the copy constructor"<<endl;
}
void fun1(Point p)
{
cout << p.getx() <<endl;
}
Point fun2()
{
Point a(1,2);
return a;
}
int main()
{
Point a(4,5); //第一个对象a
Point b = a; //情况1,用a初始化b
cout << b.getx() <<endl;
fun1(b); //情况2,对象b作为fun1的实参
b = fun2(); //情况3,函数返回值是类对象
cout << b.getx() <<endl;
return 0;
}
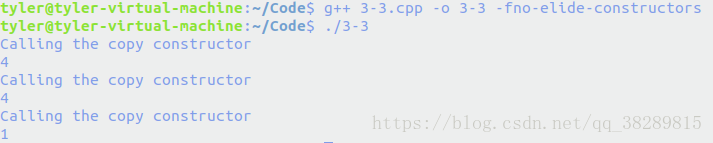
怎么少了一次?什么鬼?查阅资料后发现原因是:RVO(return value optimization),被C++进行值返回的优化了。我们可以将RVO优化关闭,可以对g++增加选项-fno-elide-constructors,重新编绎之后,执行结果如下:
统计类声明对象个数
#include <iostream>
using namespace std;
class Student
{
private:
static int number;
public:
Student()
{
number++;
show("Student");
}
~Student()
{
number--;
show("Student");
}
static void show(const char* str = NULL)//指向常量的指针
{
if(str)
{
cout << str << ":";
}
cout << "number=" << number <<endl;
}
};
int Student::number = 0;//静态数据成员赋值
Student f(Student x)
{
x.show("x inside f()");
return x;
}
int main()
{
Student h1;
Student h2 = f(h1);
Student::show("after call f()");
return 0;
}结果可能不是预期的效果。在函数f()调用时,原来的对象h1在函数之外,函数内要增加一个新对象,参数x采用的值是原来对象h1的拷贝。而参数传递采用的是“位拷贝”方式,所以达不到预期效果。当局部对象在函数f()调用结束时,析构函数被调用,从而number减少。同理,h2的值也是采用位拷贝方式传递,构造函数也没有被调用。所以结果是主函数运行结束后,对象数目为负值。
在这种情况下,C++需要真正的初始化操作,这项工作是由复制构造函数完成。当使用复制构造函数时,编译器将不再使用位拷贝。
复制构造函数定义格式:
构造函数名(const 类名&);
class A
{
...
public:
A();
A(const A&);
}上个例子修改后的程序:
#include <iostream>
using namespace std;
class Student
{
private:
static int number;
public:
Student()
{
number++;
show("Student");
}
Student(const Student&)
{
number++;
show("Student");
}
~Student()
{
number--;
show("Student");
}
static void show(const char* str = NULL)//指向常量的指针
{
if(str)
{
cout << str << ":";
}
cout << "number=" << number <<endl;
}
};
int Student::number = 0;//静态数据成员赋值
Student f(Student x)
{
x.show("x inside f()");
return x;
}
int main()
{
Student h1;
Student h2 = f(h1);
Student::show("after call f()");
return 0;
}构造函数与复制构造函数使用情况
#include <iostream>
#include <math.h>
using namespace std;
class Point
{
private:
double x,y;
public:
Point(double a, double b);
Point()
{
cout << "NO.2 constructor..." <<endl;
}
Point(Point &p)
{
cout << "\nNO.3 constructor..." <<endl;
}
~Point();
double Distance(Point p);
};
Point::Point(double a, double b)
{
cout << "NO.1 constructor..." <<endl;
x = a;
y = b;
}
Point::~Point()
{
cout << "destructor..." <<endl;
}
double Point::Distance(Point p)
{
double d;
d = sqrt((x-p.x)*(x-p.x)+(y-p.y)*(y-p.y));
return d;
}
int main()
{
Point p1(3,4), p2;
cout << "The distance is " << p1.Distance(p2) <<endl;
return 0;
}跟踪程序,得到当前Point类对象的个数。
#include <iostream>
#include <iomanip>
using namespace std;
class Point
{
private:
static int number;
int x,y;
public:
Point(int xx = 0, int yy = 0)
{
x = xx;
y = yy;
number++;
show("normal construction");
}
Point(const Point &p);
~Point()
{
number--;
show("~Point");
}
void show(const char* p = NULL);
};
int Point::number = 0;
Point::Point(const Point &p)
{
x = p.x;
y = p.y;
number++;
show("copy construction");
}
void Point::show(const char* p)
{
if(p)
cout << p <<":";
cout << number <<endl;
}
void fun1(Point p)
{
p.show("inside fun1()");
}
int main()
{
Point A(1,2);
Point B(A);
fun1(A);
return 0;
}使用复制构造函数时要注意:
(1)并不是所有的类声明中都需要复制构造函数。仅当准备用传值的方式传递类对象时,才需要复制构造函数。
(2)为了防止一个对象不被通过传值方式传递,需要声明一个私有复制构造函数。因为复制构造函数设置为私有,已显示的声明接管了这项工作,所以编译器不再创建默认的复制构造函数。
#include <iostream>
#include <iomanip>
using namespace std;
class Point
{
private:
static int number;
int x,y;
Point(const Point& p);
public:
Point(int xx = 0, int yy = 0)
{
x = xx;
y = yy;
number++;
show("normal construction");
}
~Point()
{
number--;
show("~Point");
}
void show(const char* p = NULL);
};
int Point::number = 0;
Point::Point(const Point &p)
{
x = p.x;
y = p.y;
number++;
show("copy construction");
}
void Point::show(const char* p)
{
if(p)
cout << p <<":";
cout << number <<endl;
}
void fun1(Point p)
{
p.show("inside fun1()");
}
int main()
{
Point A(1,2);
//Point B(A); //错误,拷贝构造函数为私有,不能被调用
//fun1(A); //错误,同上
return 0;
}