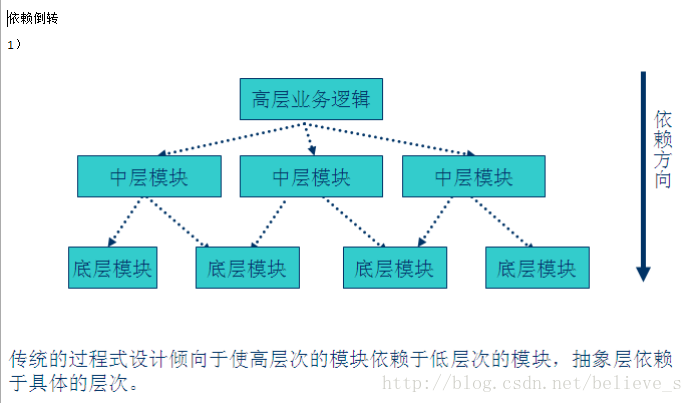
在传统的过程式中,上层依赖于底层,当底层变化,上层也得跟着做出相应的变化。这就是面向过程的思想,弊端就是导致程序的复用性降低并且提高了开发的成本。
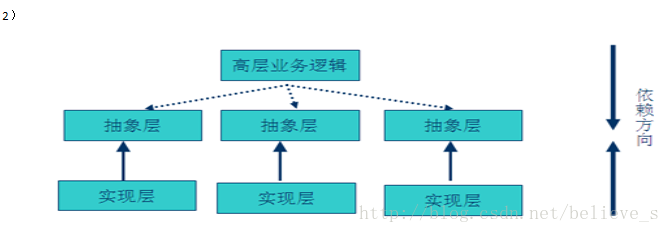
而面向对象的开发则很好的解决了这个问题,让用户程序依赖于抽象层,实现层也依赖于抽象层,而抽象层一般不会轻易变化。即使实现变化,只要抽象不变,客户程序就不用变化,这大大降低了客户程序与实现细节的耦合度。
就好比实例中电脑由硬盘、CPU、内存组成,而这些硬件又有很多种类和品牌,组装电脑时,我们只管装抽象的硬件如硬盘而不管具体是什么牌子的硬盘,这要即使你硬盘的品牌变化了,也不会影响将硬盘这种硬件装进电脑中。这里硬盘就是一个抽象类,如果没有这个抽象层,直接将电脑和具体的硬盘品牌或者类型进行连接,一旦你换成其他类型或者品牌的硬盘,你电脑的接口也得相应调整,增加了成本。
依赖倒置原则实例:
#include <iostream>
// 硬盘的抽象类
class HardDisk
{
public:
virtual void work() = 0;
};
// 三星
class SanHardDisk : public HardDisk
{
public:
void work()
{
printf ("三星硬盘正常工作....\n");
}
};
// CPU的抽象类
class CPU
{
public:
virtual void work() = 0;
};
//因特尔
class IntelCPU : public CPU
{
public:
void work()
{
printf ("Intel CPU正常工作....\n");
}
};
// 内存的抽象类
class Memory
{
public:
virtual void work() = 0;
};
//金士顿
class JsdMemory : public Memory
{
public:
void work()
{
printf ("金士顿 内存正常工作....\n");
}
};
class Computer
{
public:
Computer(HardDisk *hd, CPU *cpu, Memory *my) // 组装电脑
{
this->hd = hd; // 组装硬盘
this->cpu = cpu; // 组装CPU
this->my = my; // 组装内存
}
void work()
{
hd->work(); // 硬盘正常工作
cpu->work(); // CPU正常工作
my->work(); // 内存正常工作
}
private:
// 要有硬盘
HardDisk *hd;
// 要有CPU
CPU *cpu;
// 要有内存
Memory *my;
};
int main()
{
HardDisk *hd = NULL;
CPU *cpu = NULL;
Memory *my = NULL;
// 生产一个电脑,定义一个电脑的对象
hd = new SanHardDisk;
cpu = new IntelCPU;
my = new JsdMemory;
Computer cp(hd, cpu, my);
// Computer cp(new SanHardDisk, new IntelCPU, new JsdMemory);
cp.work();
delete hd;
delete cpu;
delete my;
return 0;
}
class A
{
public:
void func();
// 增加新功能
void func2();
};
// 通过继承增加新功能
class B: public A
{
public:
void func2();
};
// 通过组合的办法
class C
{
public:
void func()
{
a->func();
// 增加新功能
}
private:
A *a;
};