1.内联函数:
内联函数的作用是为了提高程序运行速率的一种改进,而这种改进是在于编译器如何将程序内部的函数组合在一起的。
我们应该在VS编译器下调试过代码,也看过反汇编语言。我们发现当程序在涉及到跳转函数时,它的汇编指令是call:
//函数名——>f2(4);
01268D7E push 4
01268D80 call f2 (012611CCh)
01268D85 add esp,4
我们先分析这个流程:首先代码运行到调用函数指令的时候,我们首先会存储下当前的指令地址,然后将调用函数的参数压入栈中,然后跳转到调用函数的地址处,执行代码(有可能会将返回值存储到寄存器中),之后再根据之前保存的调用函数的指令地址回到开始的地方,再次向后执行。
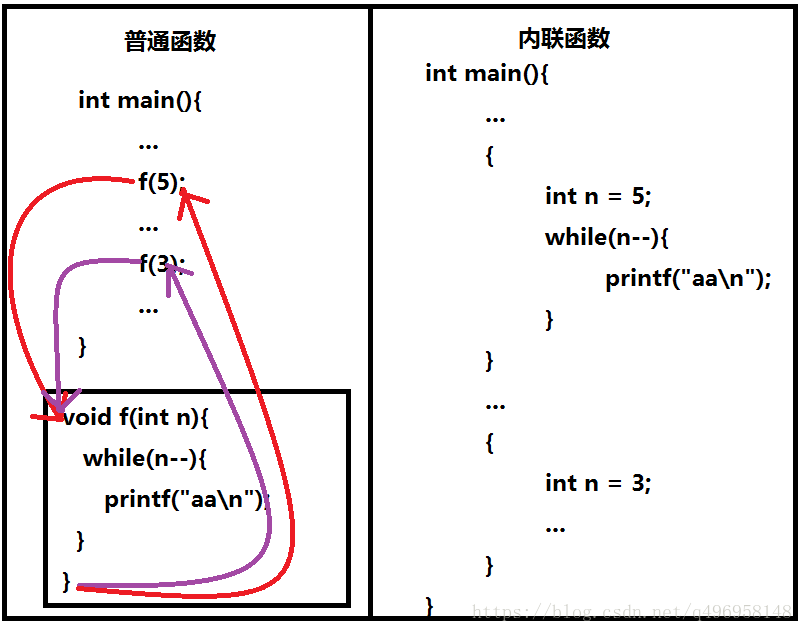
我们发现:来回跳跃并记录跳跃时的位置,这些都是需要开销的。
而可不可以解决这个问题呢?这时候就引入了内联函数。
内联函数就是:将跳转函数的指令换为整个函数的实体,当我们执行到内联函数时,就不是跳转到另一个地方执行函数了,而是函数直接在当前函数内部展开,直接运行,省去了跳转另一个地方的过程,这样下来函数运行速率会变快,但是却占用了更多的内存。
关键词:inline
内联函数和普通函数的区别流程:
要使用内联函数,必须规定以下:
1. 声明前加上关键字inline
2. 定义前加上关键词inline
备注:inline只是相当于你告诉编译器这段代码我建议你内联,最终是否内联,则是有编译器自己决定(循环次数太多和递归的代码,则不建议内联)。
2.引用变量:
C++中有个和C语言不同的东西,叫引用(又称别名),而C语言中只有指针。
1.创建引用变量
//C++对&(取地址符)赋予另一个定义,那就是声明引用。
int a = 10;
int& b = a;//引用变量的创建
int* p = &a;//创建指针而上述代码表示的含义就是:
b是a的一个小名,也可以认为a就是b,b就是a。b只是a的另一个名字。
我们直接从指针和引用的区别来谈吧:
| 指针 | 引用 |
|---|---|
| 可以指向NULL | 一个NULL对象则不可以有引用 |
| 指针是一个实体,有内存空间 | 引用则是没有实体 |
| sizeof(指针)是指针的大小 | sizeof(引用)则是类型的大小 |
| 指针可以多次赋值 | 引用只能初始化(从一至终) |
| 有二级,三级指针 | 引用只有一个,不能有引用的引用 |
| ++指针是指向下一个地址 | ++引用就是增加对象 |
以上就是引用和指针的区别。
2.将引用作为函数参数
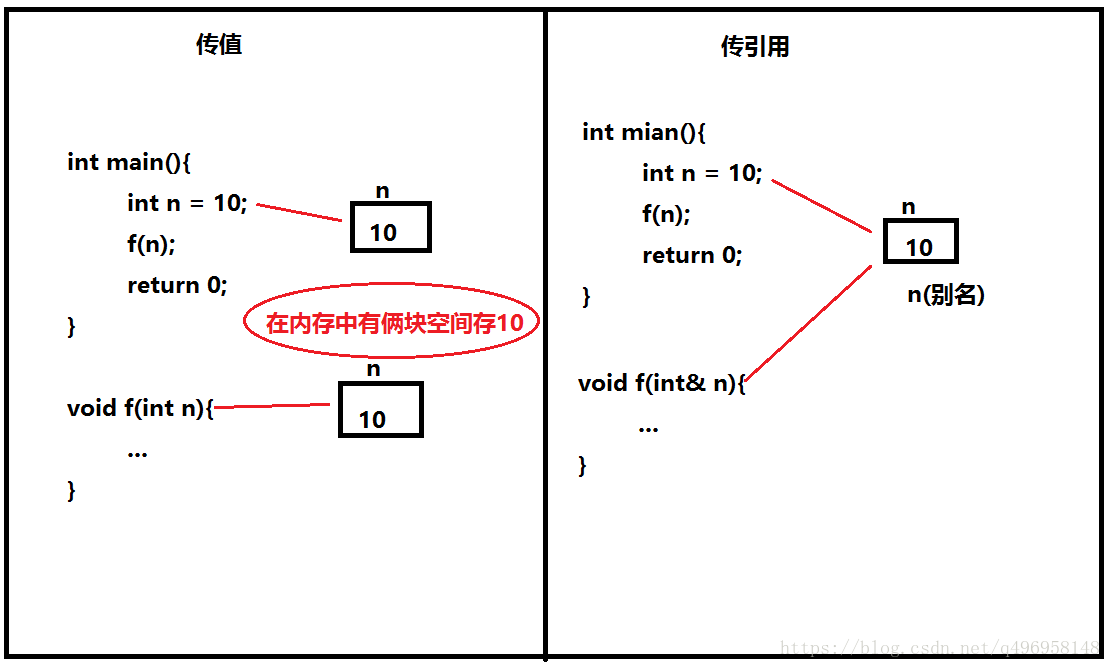
我们可以发现如果传引用的时候,可以省去重新开辟参数的空间开销,当参数是内置类型的时候(反倒引用不好,容易在调用函数中对其修改),但是如果我们参数是自定义类型(结构体、类等),如果我们采用引用这样就会节省大量的资源。
举个反例(内置类型传值比传引用好):
//求一个数的三次方
#include <iostream>
double cube(double n);
double refcube(double& n);
int main(){
using namespace std;
double n = 3.0;
cout<<cube(n);
cout<<" = cube of "<<n<<endl;
cout<<refcube(n);
cout<<" = refcube of "<<n<<endl;
system("pause");
return 0;
}
double cube(double n){
n = n * n * n;
return n;
}
double refcube(double& n){
n = n * n * n;
return n;
}
运行结果:
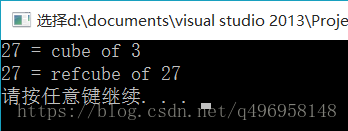
看到结果了吧,我们本质上不想改变原来的值,但是你如果传引用的话,就会出现这种情况。
那么,是不是我们使用了引用变量就一定不会创建临时变量?
答案当然是:不是!
比如:
#include <iostream>
using namespace std;
void Fun(const int& a){
cout << a << endl;
}
int main(){
int b = 1;
double a = 10;
Fun(b);//没有生成临时变量
Fun(a);//生成了临时变量
Fun(3);//生成了临时变量
Fun(b+1);//生成了临时变量
system("pause");
return 0;
}在上述代码中,就是会创建临时变量。
有概念为:如果实参和引用参数不匹配,C++将会生成临时变量。当且仅当参数为const引用时,C++才允许这样做,否则就会报错。
如果引用参数是const,那么在什么情况下会产生临时变量呢?
- 实参的类型正确,但不是左值(第3、4个例子)
- 实参的类型不正确,但是可以转化成正确的(第二个例子)
备注:引用变量尽可能使用const
- 使用const可以避免在函数中修改引用变量
- 使用const可以是函数处理const变量和非const变量,否则只能处理非const变量
- 使用const引用函数能正确生成和使用零时变量
3.返回引用
为什么要返回引用?
这个问题和我们之前谈的为什么要传引用参数一样,与按值传递函数参数类似,计算return的表达式,并将其结果返回给调用函数。从概念上来说,这个值还是被复制到一个临时变量中。
返回引用的问题:
返回引用的一个前提就是,你一定要确保你返回的引用的作用域是合法的。
实例如下:
#include <iostream>
#include <string>
using namespace std;
const string& fun(const string& s1){
string ret = s1 + s1;
return ret;
}
int main(){
string s1 = "hello world";
const string& s = fun(s1);
cout << s << endl;
system("pause");
return 0;
}我们上面的程序会直接崩掉。
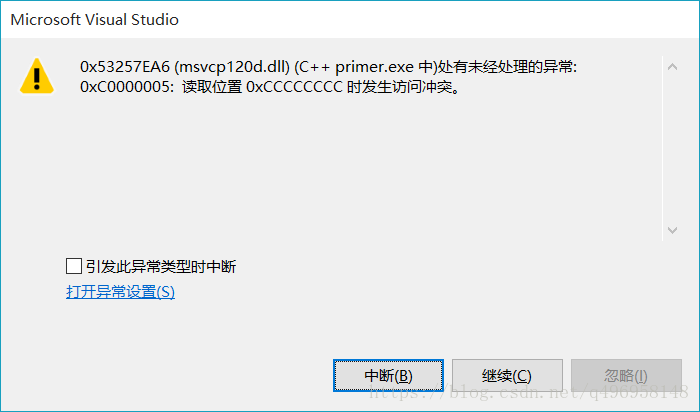
这个问题就是,程序试图访问已经释放的内存。
解决办法就是,我们最好返回一个作为参数传递给函数的引用,这样就不会出现访问非法内存的错误了。
最后说明一下合适使用引用参数的主要原因:
- 程序员能够修改调用函数的对象
- 通过传递引用可以提高程序运行效率
对于只使用参数的值,而不修改参数的函数:
- 如果数据对象很小,比如内置类型,那么建议用值传递
- 如果对象是数组,则使用指针(这是唯一的选择),只需加上const即可
- 如果对象是较大的结构,则建议使用const指针或const引用。
- 如果对象是类,则使用const引用,
对于修改参数的函数:
- 如果数据对象是内置数据类型,则使用指针
- 如果是数组,则使用指针
- 如果对象是结构,则使用指针或引用
- 如果对象是类,则使用引用
3.默认参数:
默认参数指:当函数调用时,省略了某项实参,会自动采用的值。
还是举个例子说明一下:
#include <iostream>
using namespace std;
class AA{
public:
AA(int a1 = 0, int a2 = 0,int a3 = 0)
:_a1(a1)
,_a2(a2)
,_a3(a3)
{}
private:
int _a1;
int _a2;
int _a3;
};
int main(){
AA a1;
AA a2(1);
AA a3(1, 2);
AA a4(1, 2, 3);
return 0;
}结果:
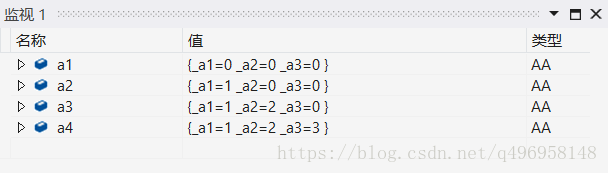
备注:缺省参数,必须从右往左依次缺省,我们传参也必须从左往右依次赋值。
4.函数重载:
说道函数重载就不得不提多态了。
我们知道面向对象的三大特性:继承,封装,多态。
而多态又分为:静态多态、动态多态。
静态多态(编译期多态):宏、函数重载、运算符重载、模板等
动态多态(运行期多态):继承和虚函数机制
函数重载:一句话,就是在相同作用域内,函数名相同,参数不同(顺序,个数,类型等),返回值无所谓。
举个例子:
#include <iostream>
#include <string>
using namespace std;
class AA{
public:
void fun(int a){
cout << "int:" << a << endl;
}
void fun(char a){
cout << "char:" << a << endl;
}
void fun(string a){
cout << "string:" << a << endl;
}
};
int main(){
AA a;
a.fun(1);
a.fun('a');
a.fun("hello");
system("pause");
return 0;
}结果:
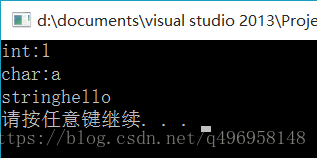
为什么C++语言支持重载?
那是因为编译器会执行一个神奇的操作:函数重命名,而C语言也有这个机制,但是C语言的重命名则是在函数名前加上“_”即可,但是C++就不是了,比如这个函数long fun(int,float);他经过重命名之后变为
?fun@@YAXH@Z,所以说C++语言支持重载的根源就在这。
C语言重命名:
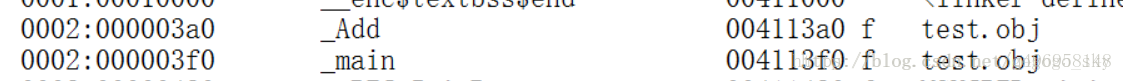
C++重命名
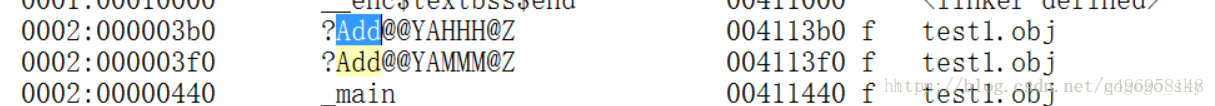
5.函数模板:
函数模板:我的理解就是,咱们平时做月饼的那个模子,我们只需要提供面就行,模子一压,一个月饼就好了。
现在有这么一个场景:我在这个程序中,要实现整形,浮点型,字符型,字符串…等等的类型交换函数怎么办?
我们之前学习过函数的重载,那么我们可以每个类型写一个swap函数。但是我们发现,随着类型的增多,这个程序的代码量太冗余了。这样就我们就可以使用函数模板了。
如下:
#include <iostream>
#include <string>
using namespace std;
template<typename T>
void Swap(T& a, T& b){
cout << "交换前 " << "参数1:" << a << " " << "参数2:" << b << endl;
T tmp = a;
a = b;
b = tmp;
cout << "交换后 " << "参数1:" << a << " " << "参数2:" << b << endl;
cout << endl;
}
int main(){
int a1 = 10, a2 = 20;
char c1 = 'a', c2 = 'b';
string s1 = "hello", s2 = "world";
float f1 = 1.1, f2 = 2.2;
Swap(a1, a2);
Swap(c1, c2);
Swap(s1, s2);
Swap(f1, f2);
system("pause");
return 0;
}结果:
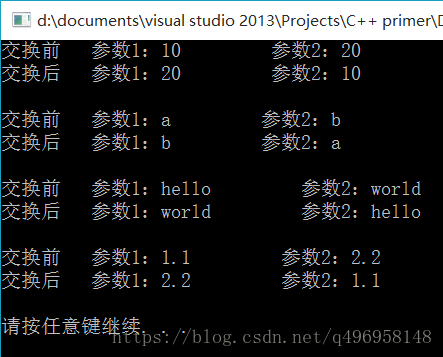
总之,函数模板也是提高了代码的复用率,减少了代码的冗余程度。