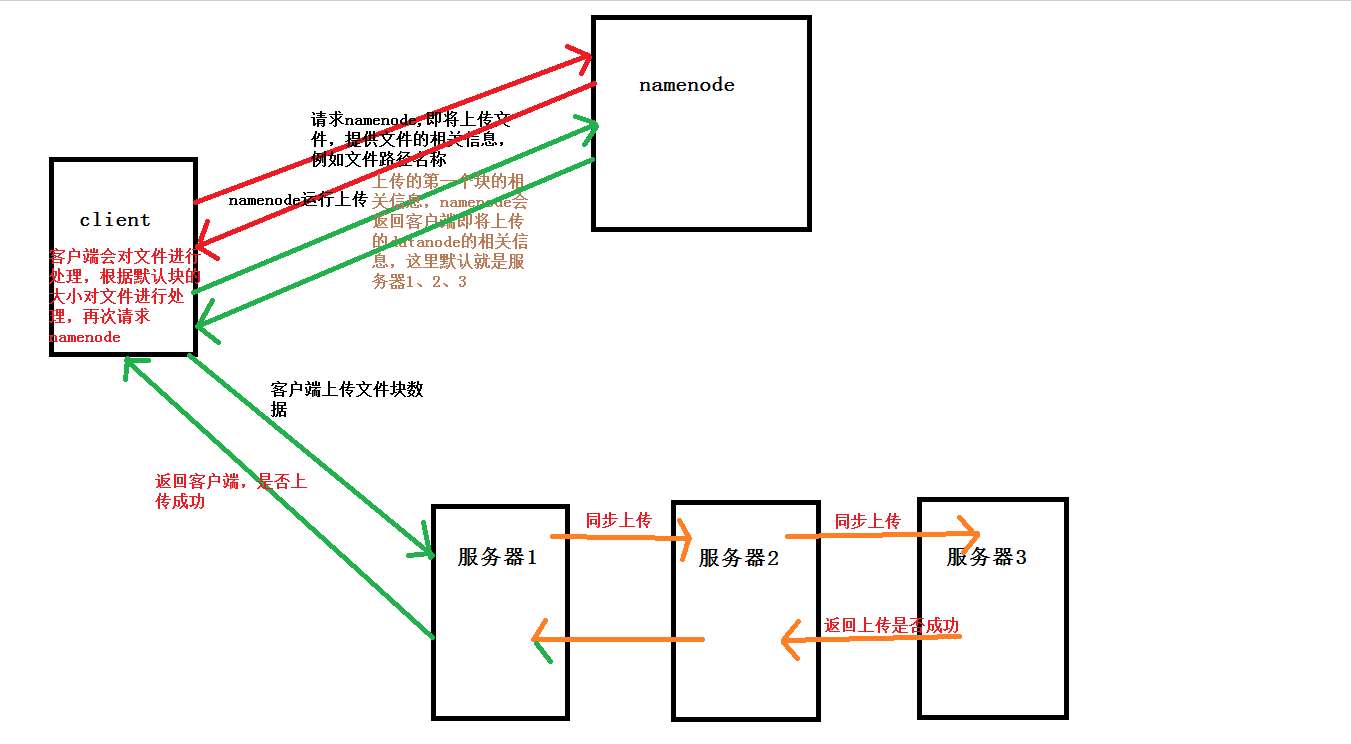
一、要了解HDFS客户端写数据的过程,首先需要明白namenode和datanode
namenode:主要保存数据的元数据,它维护着文件系统树及整棵树内所有的文件和目录,说的直白点就是文件目录的管理以及Block的管理,体现的是一个管理者的身份;
datanode:存储并检索数据块的作用,也就是说数据的存储是有datanode来直接操作的,在这体现的是一个工作者的身份,并且会定期的向namenode汇报自身的情况,
namenode 就可以比较清楚的知道其管理的每个datanode的具体情况,在数据存储的时候就知道选择那些datanode来存储
二、1、客户端需要上传文件,首先会向namenode请求,告诉namenode需要上传的文件的相关信息,例如路径文件名称大小等等,namenode会告诉客户端是否可以上传;如果允许客户端上传,(默认配置的块的大小是128M)
如果文件大于128M,客户端会对文件进行分割处理,这里就做三份处理,这时候客户端会请求namenode,提供相关块的信息以及需要存储的备份数(这里默认3份),namenode会返回相关datanode的信息给客户端(如何选择datanode?),
namenode会告诉客户端 服务器1,服务器2,服务器3即将上传的三个datanode服务器地址,这里客户端就会根据返回的地址进行文件的上传;
2、客户端上传时,namenode返回的是三台服务器的地址,那么客户端在上传时其实每次只针对一个datanode,也就是说客户端不需要分别向三个datanode上传文件,比如客户端选择服务器1上传,服务器2和3其实在客户端上传的时候,
服务器1已经和服务器2建立了上传通道,服务器2和服务器3也建立上传的通道,也就是说其实三台服务器的上传基本是同步的,如果每次都要分别取处理,这样效率也低,如果一个服务器上传出现问题,这样容错的能力也相应的降低;
只要保证服务器1成功,上传就是成功,HDFS内部应该是有机制去处理2-3过程中上传失败的容错机制;同理文件的第二个块也是和第一个块一样的上传;
三、以上只是大致描述一下HDFS客户端上传的一个流程,其中还有很多细节需要在去深究,例如,上传时,namenode是如何去选择datanode的,客户端是如何与namenode之间进行通信的等等,最后还是通过自己画的一张图来直观的表示上传的大致流程