文章节选自 http://www.runoob.com/python3/python3-basic-syntax.html
编码
默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串。
注意:如果你使用编辑器,同时需要设置 py 文件存储的格式为 UTF-8,否则会出现类似以下错误信息:
SyntaxError: (unicode error) ‘utf-8’ codec can’t decode byte 0xc4 in position 0: invalid continuation byte
Pycharm 设置步骤:
- 进入 file > Settings,在输入框搜索 encoding。
- 找到 Editor > File encodings,将 IDE Encoding 和 Project Encoding 设置为utf-8。

大家在学习过程中,代码中包含中文,就需要在头部指定编码。
在文件开头加入 # -*- coding: UTF-8 -*- 或者 #coding=utf-8 就行了
注意:#coding=utf-8 的 = 号两边不要空格。
补充:
文章节选自
https://www.cnblogs.com/zihe/p/6993891.html
https://blog.csdn.net/qq_34162294/article/details/53727357
字符编码 (前世) 今生:
1.字符编码的使用:

2.程序的执行
阶段一:启动python解释器
阶段二:python解释器此时就是一个文本编辑器,负责打开文件test.py,即从硬盘中读取test.py的内容到内存中
此时,python解释器会读取test.py的第一行内容,#coding:utf-8,来决定以什么编码格式来读入内存,这一行就是来设定python解释器这个软件的编码使用的编码格式
可以用sys.getdefaultencoding()查看( 前提是import sys ),如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的
python2中默认使用ascii,python3中默认使用utf-8.
阶段三:读取已经加载到内存的代码(unicode编码的二进制),然后执行,执行过程中可能会开辟新的内存空间,比如x="egon"
内存的编码使用unicode,不代表内存中全都是unicode编码的二进制,
在程序执行之前,内存中确实都是unicode编码的二进制,比如从文件中读取了一行x="egon",其中的x,等号,引号,地位都一样,都是普通字符而已,都是以unicode编码的二进制形式存放在内存中的.
但是程序在执行过程中,会申请内存(与程序代码所存在的内存是俩个空间),可以存放任意编码格式的数据,比如x="egon",会被python解释器识别为字符串,会申请内存空间来存放"hello",然后让x指向该内存地址,此时新申请的该内存地址保存也是unicode编码的egon,如果代码换成x="egon".encode('utf-8'),那么新申请的内存空间里存放的就是utf-8编码的字符串egon了
Python3 如图所示

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
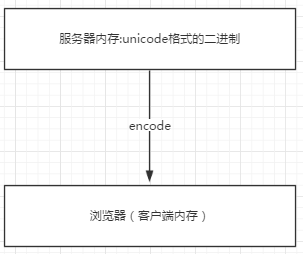
如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的二进制。
小总结:
字符串在Python内部的表示是unicode编码,因此,
在做编码转换时,通常需要以unicode作为中间编码, 即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,
如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,
如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
想要将其他的编码转换成utf-8必须先将其解码成unicode然后重新编码成utf-8,它是以unicode为转换媒介的
isinstance(str , unicode):判断str是否是unicode编码,如果是就返回true,否则返回false
s='中文'
s=s.decode('utf-8') #将utf-8编码的解码成unicode
isinstance(s,unicode) #此时输出的就是True
s=s.encode('utf-8') #又将unicode码编码成utf-8
isinstance(s,unicode) #此时输出的就是False
查看系统默认编码格式:
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'