一,什么是机架感知和它的好处
1,什么是机架感知:
机架感知就是告诉Hadoop集群中那台机器属于哪个机架,Hadoop对机架的感知并非自适应,hadoop集群分辨某台slave机器是属于哪一个rack并非智能,这样hadoop的namenode启动初始化时,会将这些机器与rack的对应信息保存在内存中,用来作为接下来所有的HDFS的写块操作分配给datanode列表时,尽量将复本分布到不同的rack中,如果你没用给hadoop集群做机架感知。
2,机架感知的好处
他不会自动识别,就有可能会把3个复本放在一个机架的不同机器上,这样机架崩坏那么数据会全部丢失,虽然这样的概念很小,但为了减小这样的事情方式,我们都会使用机架感知来把复本分发到不同机架上
副本放置的机架感知目的在可靠性、可用性、提升网络性能
3,复本的存放:
- 1st replica. 如果写请求方所在机器是其中一个datanode,则直接存放在本地,否则随机在集群中选择一个datanode.
- 2nd replica. 第二个副本存放于不同第一个副本的所在的机架.
- 3rd replica.第三个副本存放于第二个副本所在的机架,但是属于不同的节点.
所以总的存放效果图如下所示
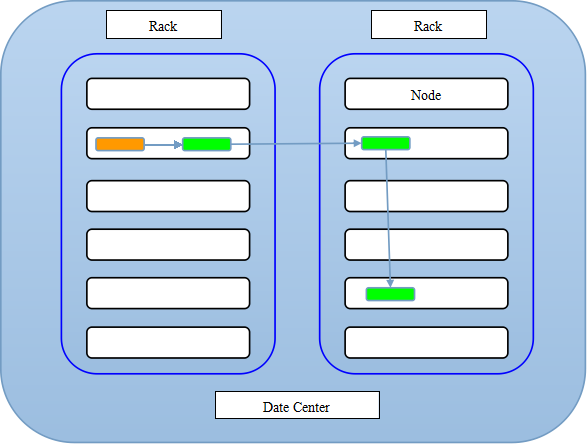
二,具体实现机架感知
hadoop自身是没有机架感知能力的,必须通过人为的设定来达到这个目的。在FSNamesystem类中的resolveNetworkLocation()方法负载进行网络位置的转换。其中dnsToSwitchMapping变量代表了完成具体转换工作的类。
也就是说dnsToSwitchMapping的值由“core-site.xml”配置文件中的"topology.node.switch.mapping.impl"参数指定。默认值为ScriptBasedMapping,也就是通过读提前写好的脚本文件来进行网络位置映射的。但如果这个脚本没有配置的话,那就使用默认值“default-rack”作为所有结点的网络位置。
首先我们先把准备工作做好:
1, 电脑内存有限我就只开了4台datanode机器
192.168.14.125 t125
192.168.14.126 t126
192.168.14.127 t127
192.168.14.128 t128
2,我用的是maven项目jre包就不能给你们看了太多了,我索性就把pom文件给你们copy下来:
<repositories><!-- 代码库 -->
<repository>
<id>maven-ali</id>
<url>http://maven.aliyun.com/nexus/content/groups/public//</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
</dependency>
</dependencies>
3,在maven项目创建myDNSToSwitchMapping类实现DNSToSwitchMapping接口,重写接口的方法完成的(主要就是在resolve方法写内容)。这就需要自己写个java类来完成映射了,这样的话,在进行网络位置解析的时候,就会调用自己类中的resolve()方法来完成转换了。我看一下其他的利用java实现hadoop的机架感知都是一个样,没什么新鲜的,于是我就稍微机灵了一下虽然实现的机制都是一样的但是保证你见了我的代码就不想看他们的代码了贼简单就几句话:
package demo1;
import java.util.ArrayList;
import java.util.List;import org.apache.hadoop.net.DNSToSwitchMapping;
public class myDNSToSwitchMapping implements DNSToSwitchMapping{
@Override
public List<String> resolve(List<String> names) {
List<String> list=new ArrayList<String>();
for (String name : names) {
Integer ip=null;
if(name.startsWith("192")) {
ip=Integer.parseInt(name.substring(name.lastIndexOf(".")+1));
}else {
ip=Integer.parseInt(name.substring(1));
}
if(ip<=126) {
list.add("/dc1/rack1");
}else {
list.add("/dc1/rack2");
}
}
return list;
}@Override
public void reloadCachedMappings() {
}@Override
public void reloadCachedMappings(List<String> names) {
}
}
4,使用maven的install来打jar包,放入每台机器的${hadoop_home}/soft/hadoop/share/hadoop/common/lib/下(包括namenode机器上面叙述的机器我没有写namenode的机器但也是要分发的),我这里使用的是自己编写的脚本底层使用的是xsync这个命令分发的时候大家可能使用的方式都有可能不一样,这样能发进去就OK了
sh xsync HDFS_day2-0.0.1-SNAPSHOT.jar (我打的jar包)
5,配置每台机器的core-site.xml文件具体配置如下:
<property> <name>topology.node.switch.mapping.impl</name> <value>demo1.myDNSToSwitchMapping</value> #myDNSToSwitchMapping类的全名 </property>然后分发:
sh xsync.sh core-site.xml
6,开启hadoop集群 start-all.sh
7,开启成功后在任意一台机器上输入 hadoop dfsadmin -printTopology
Rack: /dc1/rack1 192.168.14.125:50010 (t125) 192.168.14.126:50010 (t126) Rack: /dc1/rack2 192.168.14.127:50010 (t127) 192.168.14.128:50010 (t128)
这就说明机架感知配置成功了。
java类的方式性能较高,但是编译之后就无法改变了,所以灵活程度较低,但在公司里一般是定死的,不会轻易改变,所以java实现的方式还是高效的.。