引子
我们在做分布式缓存的时候,通常会对需要存储key进行一定的算法,然后使该key均匀的落到每一个节点进行存储。
最简单的实现算法是普通余数Hash算法,按照节点数量,对key的hashCode进行取余,根据结果将key随机分配到不同节点上。
举个例子:
假设缓存服务器有三个节点,我们标记为0号节点,1号节点,2号节点。
每次往缓存中插入数据的时候,会先对key取余,余数是几则存到几号节点,从缓存中取数据也一样,先对key的hashCode取余,余数是几则从几号节点查询数据。
比如我们有3000个key,取余算法能基本帮我们实现key的均匀分布,可以基本实现每个节点存储1000个左右的key。
但是普通余数Hash算法伸缩性差,伸缩性差指的是增删节点性能差,还是上面的例子,我们假设现在需要添加一个节点。
由于现在服务器变成了四个节点,那么需要对目前已存在的3000个key的hashCode值对4进行取余,重新分配存储位置。假设我们所有key的hashCode从0-2999,我们通过下面一段代码看看有多少key需要更换存储节点:
@Test
public void test3To4() {
Map<Integer, Integer> oldMap = setKeyToNode(3);
Map<Integer, Integer> newMap = setKeyToNode(4);
int changeCount = 0;
Set<Entry<Integer,Integer>> entrySet = oldMap.entrySet();
for (Entry<Integer, Integer> entry : entrySet) {
Integer oldNode = entry.getValue();
Integer newNode = newMap.get(entry.getKey());
if (!oldNode.equals(newNode)) {
changeCount++;
}
}
System.out.println(changeCount + " nodes have changed");
}
//将key,节点id 以Map的形式存到HashMap中
private Map<Integer, Integer> setKeyToNode(int nodeNum){
Map<Integer, Integer> keyNodeMap = new HashMap<Integer, Integer>();
for (int i=0; i<3000; i++) {
keyNodeMap.put(i, i%nodeNum);
}
return keyNodeMap;
}控制台输出
2250 nodes have changed从上面的小案例中我们可以发现普通余数Hash算法在增删节点的时候,会有大量的key更换存储节点,这不是我们所希望见到的,所以一致性Hash算法就出现了。
一致性Hash算法介绍
先构造一个长度为2^32的整数环(一致性Hash环),首尾相连

自定义一个Hash算法使得Hash值分布在0-2^32-1,根据Hash算法将服务器节点(可以根据IP,mac id等唯一标识)放置在Hash环上
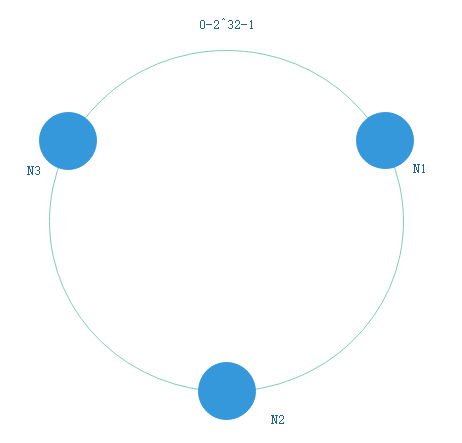
使用Hash算法计算出key的hash值,在Hash环上顺时针查找距离这个hash值最近的服务器节点
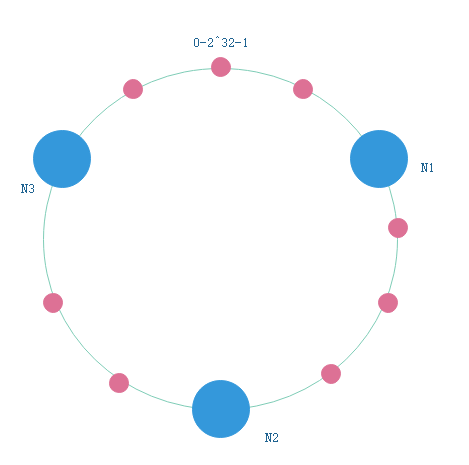
这样的话由于key基本均匀分布在Hash环上的,所以三个节点上分布的key数量也是比较均衡的。
伸缩性
节点故障
如果节点N3发生故障:
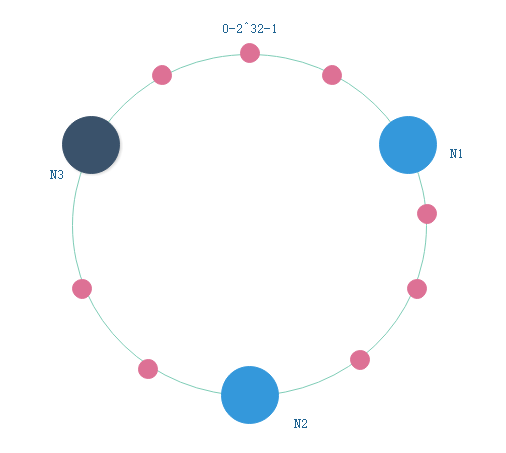
根据顺时针的原则,只有N2-N3部分的key会从N3转移到N1,其他key都保持不变。
新增节点
如果新增节点N4:
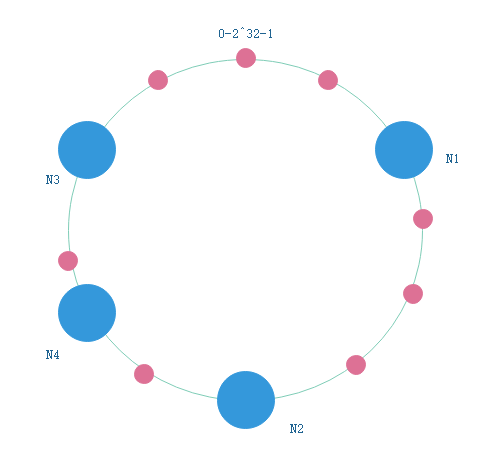
只有N2-N4之间的key会从N3转移到N4,其他key都保持不变。
所以一致性Hash算法能保证伸缩性良好,在增删节点时需要移动的key并不会太多。
虚拟节点
由于hash算法的不确定性,三个节点可能不是按照上面图中的三角分布,可能会出现三个节点很接近的情况:
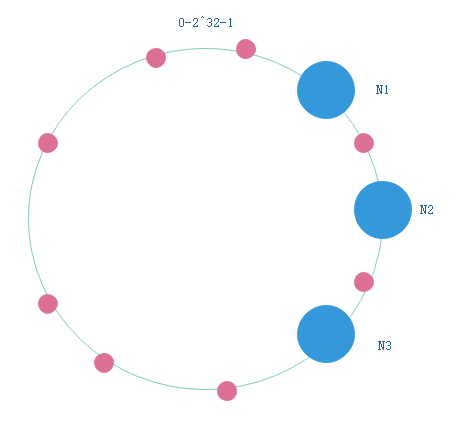
那么就会出现大量key都落在N1节点上的情况,导致分布不均匀。
这是由于节点太少的原因导致的,如果我们有几十上百个节点,那么节点的分布会均匀很多,key的分布也就会比较均匀。
但是实际情况下我们可能就只有几个节点,那么我们就可以添加一些虚拟节点
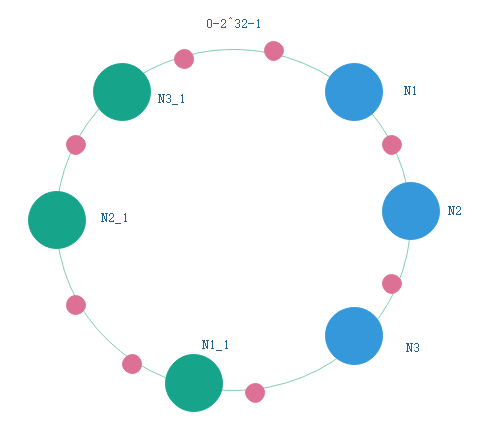
我们可以在N1节点的IP(唯一标识)后面加上后缀,然后通过hash算法产生一个虚拟节点N1_1,然后再将虚拟节点N1_1指向真实节点N1。
同样的我们还可以生成虚拟节点N1_x、N2_x、N3_x,这样就可以让我们在节点很少的情况下也能实现key的均匀分布。
总结
- 一致性Hash算法可以帮我们基本实现数据均匀分布到不同节点
- 一致性Hash算法伸缩性很好
- 在节点数量很少的情况下,可以添加虚拟节点帮我们实现数据的均匀分布
一致性Hash算法是一种比较合适的拆分数据方式,我们工作中分库、分表、分布式缓存的时候,都可以用到。
喜欢这篇文章的朋友,欢迎长按下图关注公众号lebronchen,第一时间收到更新内容。
