看着自己写的文章浏览数一点一点增加是非常开心的,但总感觉浏览数增长地太慢了,于是自然想到,为什么不能写一个小程序自动刷博客浏览量呢?Let's do it
首先,我们尝试用requests打开博客url,看看浏览量是否会增加(当然要用到一点点伪装技术):
import requests
from requests import RequestException
def get_page(url):
try:
headers = {
'Referer': 'https://blog.csdn.net', # 伪装成从CSDN博客搜索到的文章
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36' # 伪装成浏览器
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求出错')
return None
def main():
url = 'https://blog.csdn.net/polyhedronx/article/details/81459592' # 待刷浏览量博客的url
get_page(url)
if __name__ == '__main__':
main()运行程序后,发现博客的浏览量确实是增加了。这就简单了,我们只要加一个循环就能不停地自动刷浏览量了。
为了直观地看出博客当前浏览量的变化,对页面进行简单的解析,并用正则表达式提取出博客的浏览量信息,也就是下面图片中的阅读数:
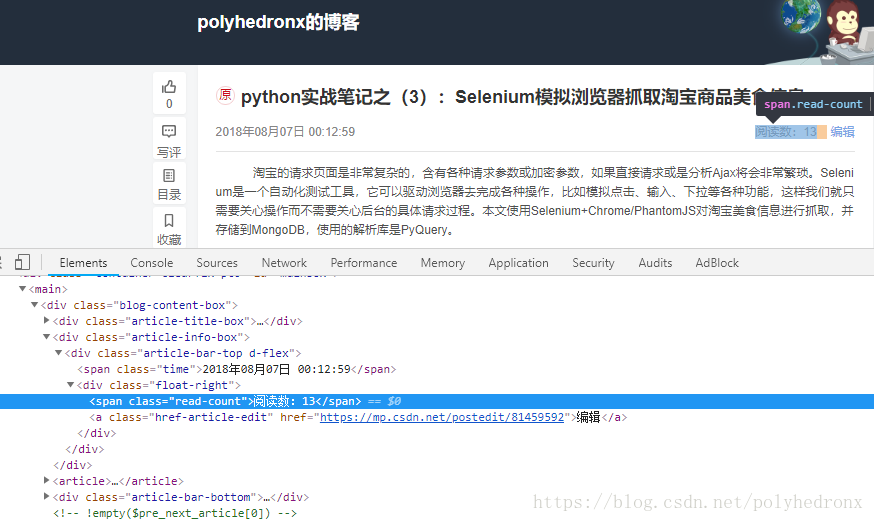
def parse_page(html):
try:
read_num = int(re.compile('<span.*?read-count.*?(\d+).*?</span>').search(html).group(1))
return read_num
except Exception:
print('解析出错')
return None更改一下main()函数:
def main():
try:
url = 'https://blog.csdn.net/polyhedronx/article/details/81459592' # 待刷浏览量博客的url
while 1:
html = get_page(url)
if html:
read_num = parse_page(html)
if read_num:
print('当前阅读量:', read_num)
time.sleep(1)
except Exception:
print('出错啦!')运行一遍完整的程序,却发现阅读量一直没有变化,耐心地等了很久阅读量才增加了1,应该是访问地太过频繁,触发了反爬虫机制之类的(具体原因求指教..),但幸好没有被封IP,把time.sleep()改大一些就好了。
下面是完整的程序:
import re
import requests
from requests import RequestException
import time
def get_page(url):
try:
headers = {
'Referer': 'https://blog.csdn.net', # 伪装成从CSDN博客搜索到的文章
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36' # 伪装成浏览器
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求出错')
return None
def parse_page(html):
try:
read_num = int(re.compile('<span.*?read-count.*?(\d+).*?</span>').search(html).group(1))
return read_num
except Exception:
print('解析出错')
return None
def main():
try:
url = 'https://blog.csdn.net/polyhedronx/article/details/81459592' # 待刷浏览量博客的url
while 1:
html = get_page(url)
if html:
read_num = parse_page(html)
if read_num:
print('当前阅读量:', read_num)
time.sleep(60) # 设置访问频率,过于频繁的访问会触发反爬虫
except Exception:
print('出错啦!')
if __name__ == '__main__':
main()
更新:
IP被封了,看来缺德事还是要少干,不过可以使用代理IP,有空再试试吧。另外这篇博客提到了一些反爬虫和反反爬虫机制,大家可以参考一下:https://blog.csdn.net/Marksinoberg/article/details/78168223