一 。solr简介
solr是以lucene为内核开发的企业级搜索应用 应用程序可以通过http请求方式来提交索引,查询索引,提供了比lucene更丰富的查询语言,是
一个高性能,高可用环境全文搜索引擎
二 。solr安装配置
1》下载solr安装包 solr所有版本 (http://archive.apache.org/dist/lucene/solr/)
这里下载 solr-5.5.4
2》安装 解压将solr-5.5.4\server\solr-webapp下的webapp 拷贝到tomcat\webapps目录下 改名为solr 启动tomcat
直接访问 出现404 找到tomcat/logs/localhost.2017-08-17.log 日志 出现以下异常
可用看到缺少SLF4j包 应该去 应该去 解压包 /server/lib/ext下找到并拷贝到 tomcat/solr/lib目录下 然后重启继续访问 出现以下错误
明显是Servlet版本不一致 tomcat6不支持solr5.54 加大tomcat版本 tomcat7也不支持 换成tomcat8 启动后访问 依然错误: 是因为需要配置solrhome和solrhome的配置环境3》配置solrhome
找到 tomcat\solr\WEB-INF\web.xml 编辑 找到以下这段(配置solrhome) 去掉注释 将第二个参数配置为本地任意一个目录即可
找到solr解压包/server/solr目录拷贝所有文件到 以上web.xml指定的路径D:\learn\solr-5.5.4\home下 重启tomcat 访问http://localhost:8080/solor/index.html 或者 http://localhost:8080/solr/admin.html

4》配置core(core类似于数据库可以插入多个document(数据库表行)每个document拥有多个 field 数据库的列)
solrhome下新建一个core目录 比如mycore
拷贝 solr解压包下\server\solr\configsets\basic_configs到新建目录 mycore中
进入solr管理网页 点击 core admin 添加该core
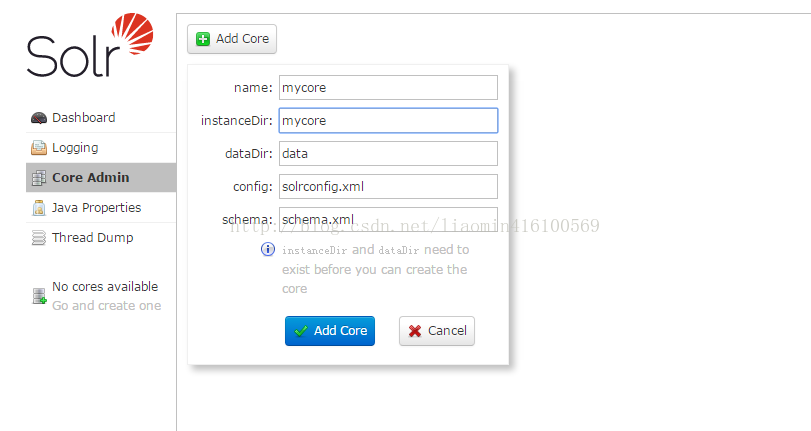
点击Add core后 成功后 检查 mycore目录 发现多了 core.properties和data两个资源
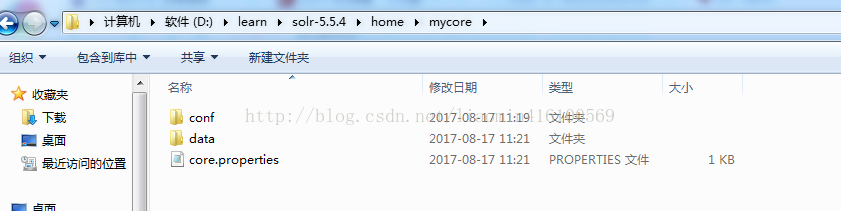
登陆solr管理网站发现 列表中多了mycore
4》配置文件理解
core/conf目录下的两个配置文件非常重要
managed-schema 主要用于配置 可以提交到该core的所有field定义,field的类型定义,唯一标识符等
常用配置如下:
solrconfig.xml 主要用于配置solor的主要配置信息 比如lucene版本 缓存 数据目录 请求路径映射 等 尝试在界面上添加数据和查询数据添加数据
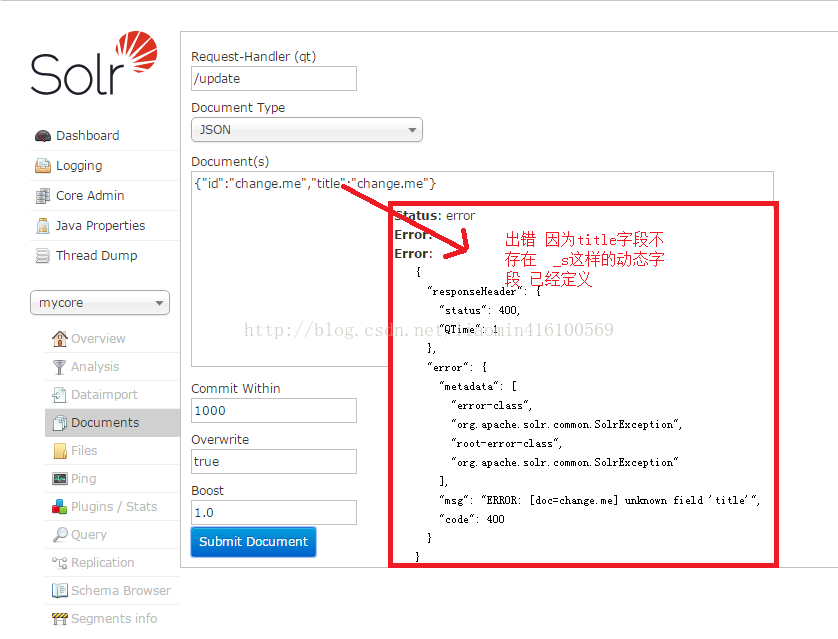
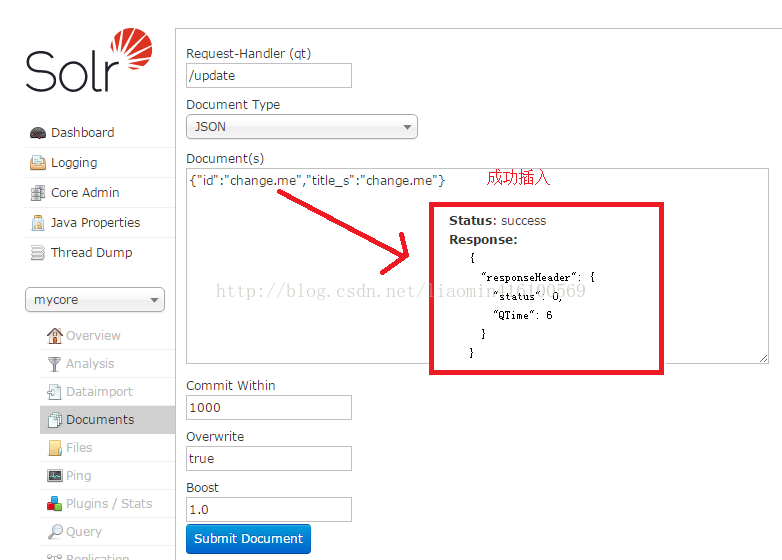
查询结果
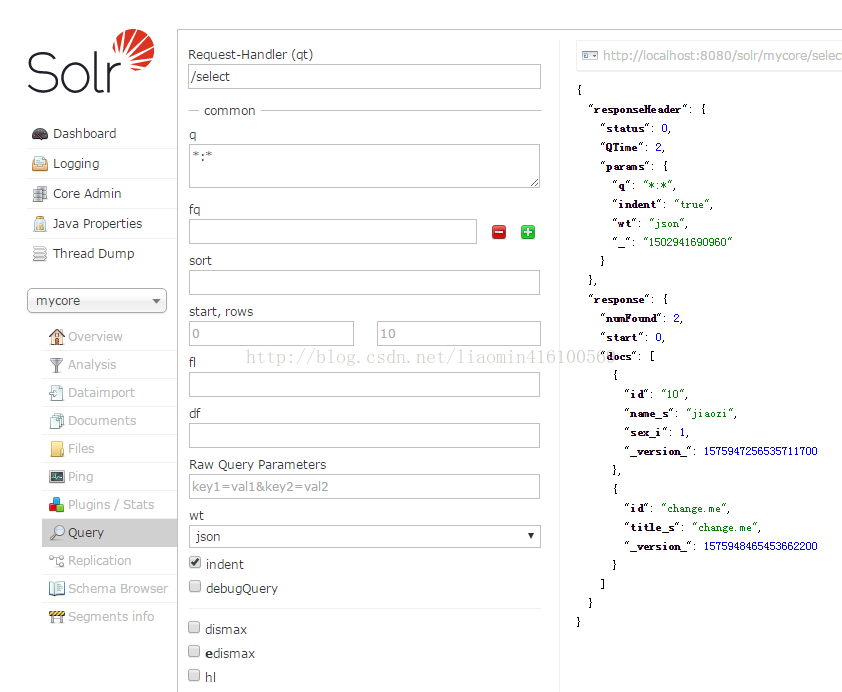
查询的参数列表
q表示查询的条件 字段名:值的格式
fq表示filter query 过滤条件 和q是and的关系支持各种逻辑运算符 (参考https://cwiki.apache.org/confluence/display/solr/The+Standard+Query+Parser)
sort表示排序 的字段 字段名 asc|desc
start 表示从第几行开始 rows表示查询的总行数
fl表示查询显示的列 比如只需要查询 name_s,sex_i 这两列 使用,隔开
df表示默认的查询字段 一般不设置
Raw Query Parameters表示原始查询字段 可以使用 start=0&rows=10这种url的方式传入参数
wt(write type)表示写入的格式 可以使用json和xml
shards 多核同时搜索 solrhome拷贝mycore为mycore1 管理平台添加core 设置参数为 路径,路径来设置需要搜索的核
其他参考(https://cwiki.apache.org/confluence/display/solr/Common+Query+Parameters)
5》配置中文分词器
默认solr 没有使用中文分词器 所有搜索的词 都是整个句子就是一个词 搜索时 将单词全部写入才能搜索或者使用* 需要配置中文分词器
目前比较好用的分词器 是IK 2012年停更 只支持到 Lucene4.7 所有 solr5.5 需要lucene5支持 需要修改部分源码来支持solr5.5
找到 IKAnalyzer类 需要重写 protected TokenStreamComponents createComponents(String fieldName) 方法
找到 IKTokenizer类 需要重写构造方法 public IKTokenizer(Reader in, boolean useSmart) 为 public IKTokenizer(boolean useSmart) {
在任意项目中 使用maven 引用lucene5 和ik
<!-- 解决maven的冲突 -->
<dependencies>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
<exclusions><!--排除4.7.2版本中的jar-->
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queries</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-sandbox</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency><!--添加5.5.4的jar -->
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>5.5.4</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>5.5.4</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queries</artifactId>
<version>5.5.4</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-sandbox</artifactId>
<version>5.5.4</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.5.4</version>
</dependency>
</dependencies> cop在项目中 添加完整的包名和类名 和 ik中一致 拷贝源代码
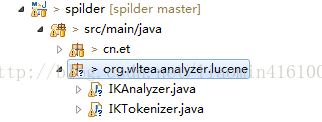
代码修改对应的方法即可
IKAnalyzer
IKTokenizer在MAVEN\apache-maven-3.0.4_localtest\resp\com\janeluo\ikanalyzer\2012_u6目录下找到ikanalyzer-2012_u6.jar
拷贝该jar,在编译好java类的maven项目中的target\classes\org\wltea\analyzer\lucene目录下找到class文件,
将编译好的class文件替换拷贝的jar包中
然后将jar放到tomcat的apache-tomcat-8.0.44\webapps\solr\WEB-INF\lib目录下;
将solrhome下 配置文件managed-schema 添加一个字段类型 使用ik分词器
不能修改 StrField 不支持自定义分词器<fieldType name="string" class="solr.StrField" sortMissingLast="true" >
</fieldType>
然后将对应需要进行中文分词的字段使用 text_ik该字段类型 比如
重启 或者 cloud环境下重新生成collection 插入数据即可实现中文分词 通过某些中文关键字搜索三。solr客户端
solr提供的solrj java客户端可以使用java来添加和查询索引
使用maven引入solrj的依赖库
使用客户端操作添加和查询索引的代码
package cn.et;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrQuery.ORDER;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.FacetField;
import org.apache.solr.client.solrj.response.FacetField.Count;
import org.apache.solr.client.solrj.response.Group;
import org.apache.solr.client.solrj.response.GroupCommand;
import org.apache.solr.client.solrj.response.GroupResponse;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.client.solrj.response.UpdateResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.apache.solr.common.params.GroupParams;
public class TestSolr {
static String urlString="http://localhost:8080/solr/mycore";
static SolrClient solr;
static{
solr = new HttpSolrClient(urlString);
}
public static void main(String[] args) throws SolrServerException, IOException {
getCount();
}
/**
* 用对象写入数据
* @throws SolrServerException
* @throws IOException
*/
public static void writeBean() throws IOException, SolrServerException{
HttpSolrClient hsc=new HttpSolrClient(urlString);
Food food=new Food();
food.setId("10");
food.setFoodname_ik("青椒炒肉");
hsc.addBean(food);
hsc.commit();
hsc.close();
}
/**
* 通过对象读取数据
* @throws IOException
* @throws SolrServerException
*/
public static void readBean() throws SolrServerException, IOException{
HttpSolrClient hsc=new HttpSolrClient(urlString);
SolrQuery sq=new SolrQuery();
sq.setQuery("foodname_ik:青椒");
sq.setSort("id",ORDER.asc);
sq.setStart(0);
sq.setRows(20);
List<Food> beans = hsc.query(sq).getBeans(Food.class);
for (Food food : beans) {
System.out.println(food.getFoodname_ik());
}
hsc.close();
}
/**
* 统计个数
* @throws SolrServerException
* @throws IOException
*/
public static void getCount() throws SolrServerException, IOException{
HttpSolrClient hsc=new HttpSolrClient(urlString);
SolrQuery sq=new SolrQuery();
sq.setQuery("foodname_ik:青椒");
sq.setSort("id",ORDER.asc);
sq.setStart(0);
sq.setRows(20);
//设置统计结果
sq.setFacet(true);
sq.addFacetField("type_s");
QueryResponse query = solr.query(sq);
List<FacetField> facetDates = query.getFacetFields();
for (FacetField facetField : facetDates) {
List<Count> values = facetField.getValues();
for (Count count : values) {
System.out.println(count.getName()+":"+count.getCount());
}
}
hsc.close();
}
/**
* 用document装配
* @throws SolrServerException
* @throws IOException
*/
public static void write() throws SolrServerException, IOException{
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "4");
document.addField("name_ik", "糖醋里脊");
document.addField("price_d", "49.99");
UpdateResponse response = solr.add(document);
// Remember to commit your changes!
solr.commit();
solr.close();
}
/**
* 分组
* @throws SolrServerException
* @throws IOException
*/
public static void groupBy() throws SolrServerException, IOException{
SolrQuery solrQuery=new SolrQuery("content_ik:桂林");
solrQuery.setParam(GroupParams.GROUP, true);
solrQuery.setParam(GroupParams.GROUP_FIELD, "type_s");
solrQuery.setParam("group.ngroups", true);
QueryResponse query=solr.query(solrQuery);
solrQuery.setParam(GroupParams.GROUP_LIMIT, "10");
GroupResponse groupResponse=query.getGroupResponse();
List<GroupCommand> values = groupResponse.getValues();
for (GroupCommand groupCommand : values) {
String name = groupCommand.getName();
List<Group> values2 = groupCommand.getValues();
for (Group group : values2) {
System.out.println(group.getGroupValue());
SolrDocumentList result = group.getResult();
for (SolrDocument solrDocument : result) {
System.out.println(solrDocument.getFieldValue("content_ik"));
}
System.out.println("----------");
}
}
}
/**
* 根据document查询,设置高亮
* @throws SolrServerException
* @throws IOException
*/
public static void read() throws SolrServerException, IOException{
SolrQuery solrQuery=new SolrQuery();
//查询
solrQuery.setQuery("foodname_ik:青椒");
//过滤(不考虑得分)
//solrQuery.setFilterQueries("foodname_ik:青椒");
//排序
solrQuery.setSort("id",ORDER.asc);
//分页查询两个参数
//开始位置 从0开始
solrQuery.setStart(0);
//返回总行数
solrQuery.setRows(2);
//设置高亮
//是否高亮
solrQuery.setHighlight(true);
solrQuery.addHighlightField("foodname_ik");
solrQuery.set("hl.fl", "foodname_ik");
solrQuery.setHighlightSimplePre("</font color=red>");
solrQuery.setHighlightSimplePost("</font>");
//solrQuery.set(HighlightParams.HIGHLIGHT, "foodname_ik");
QueryResponse query = solr.query(solrQuery);
//获取集合
SolrDocumentList results = query.getResults();
Map<String, Map<String, List<String>>> highlighting = query.getHighlighting();
for (SolrDocument solrDocument : results) {
String id=solrDocument.getFieldValue("id").toString();
System.out.println(id);
System.out.println(solrDocument.getFieldValue("foodname_ik"));
Map<String, List<String>> map = highlighting.get(id);
List<String> list = map.get("foodname_ik");
String highStr=list.get(0);
System.out.println(highStr);
}
solr.close();
}
/**
* 根据id删除
* @throws SolrServerException
* @throws IOException
*/
public static void delete() throws SolrServerException, IOException{
UpdateResponse deleteById = solr.deleteById("4");
solr.commit();
solr.close();
}
/**
* 根据条件删除
* @throws SolrServerException
* @throws IOException
*/
public static void deleteByCondition() throws SolrServerException, IOException{
UpdateResponse deleteById = solr.deleteByQuery("foodname_ik:炒蛋");
solr.commit();
solr.close();
}
}
package cn.et;
import org.apache.solr.client.solrj.beans.Field;
public class Food {
public Food(){
}
@Field
private String id;
@Field
private String foodname_ik;
@Field
private String type_s;
public String getType_s() {
return type_s;
}
public void setType_s(String type_s) {
this.type_s = type_s;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getFoodname_ik() {
return foodname_ik;
}
public void setFoodname_ik(String foodname_ik) {
this.foodname_ik = foodname_ik;
}
}