常量池深度剖析:
在上一次【https://www.cnblogs.com/webor2006/p/9416831.html】中已经将常量池分析到了2/3了,接着把剩下的分析完,先回顾一下我们编译的源文件为:

然后用javap -verbose查看一下编译字节码的信息,其中字符串相关的如下:
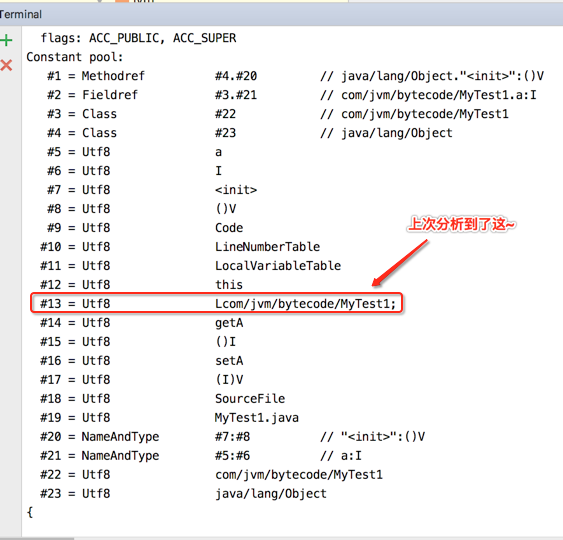
而对应用Hex Fiend来查看字符码的二进制文件的位置如下:

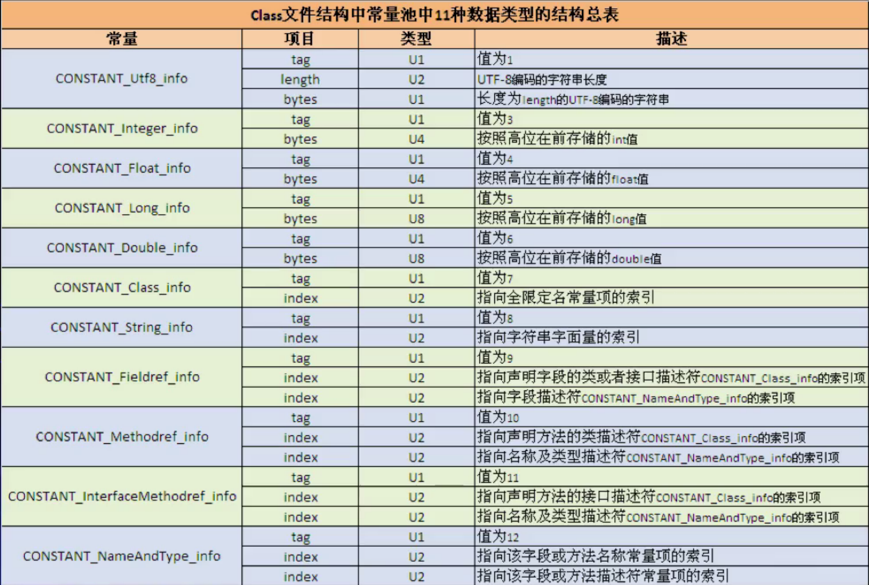
另外在继续分析之前再来回顾下常量的对应表,如下:
好下面开始,先来读一个字节来看一下是什么类型的常量:
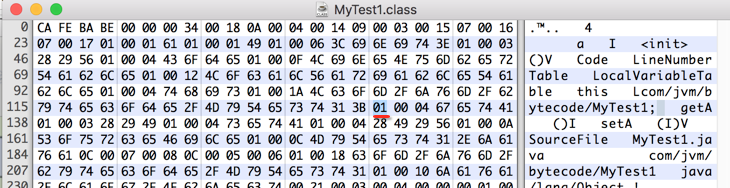
查表可以看到是属于这个常量:

接着2个字节表示字符串的长度,所以往下数二个字节:
长度为4,则下往下数4个字节则为常量的内容:

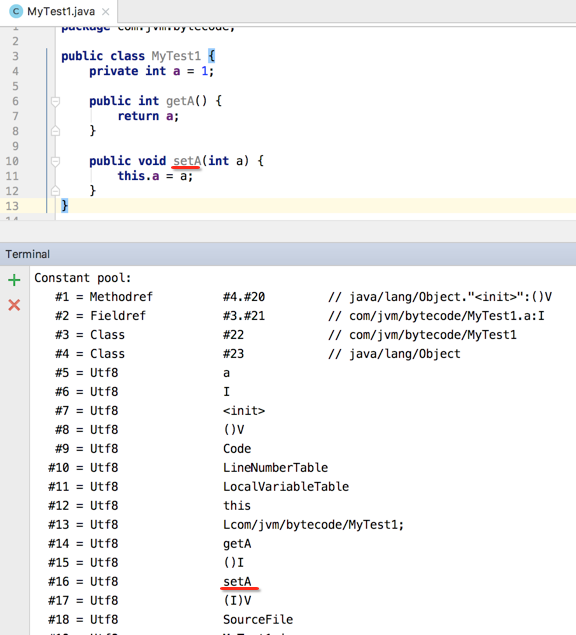
用javap -verbose来确认一下是否也是它:
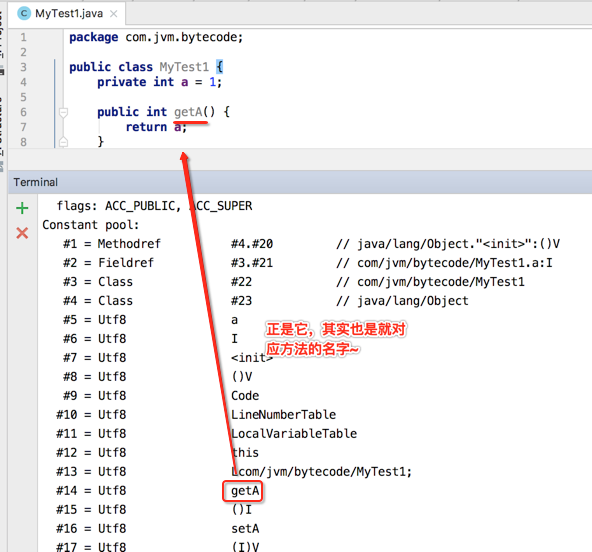
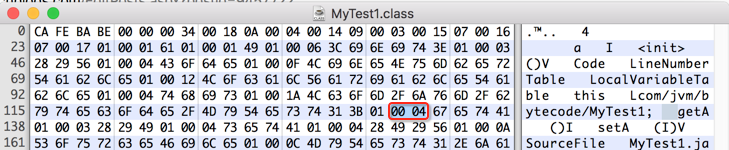
接下来继续读一个字节:
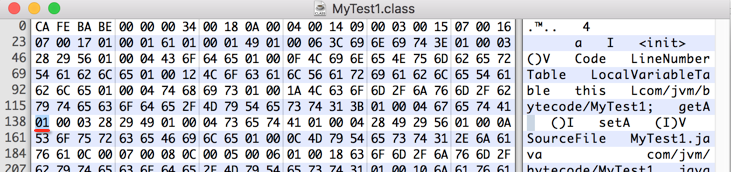
又是同样的常量类型,所以直接再读二个字节来看一下字符串的长度是多少:
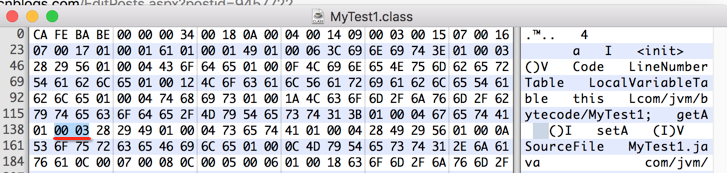
长度为3,则往后再数3个字节:
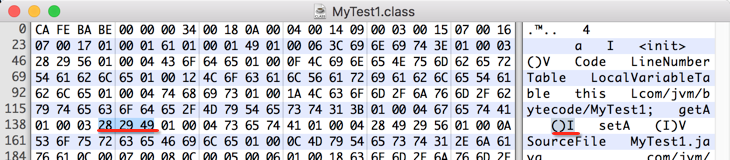
看一下javap -verbose:
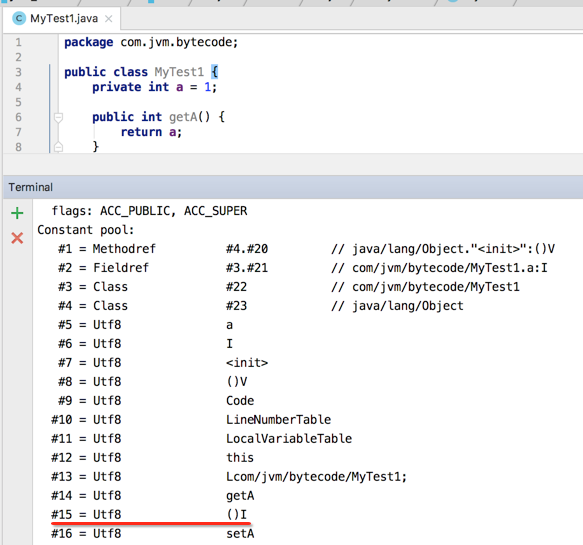
实际上"getA()I"就可以确认其方法名为getA,无参,并且返回值为整型,就可以完全的对应的源程序中的方法了。
接下来继续往下,读一个字节:
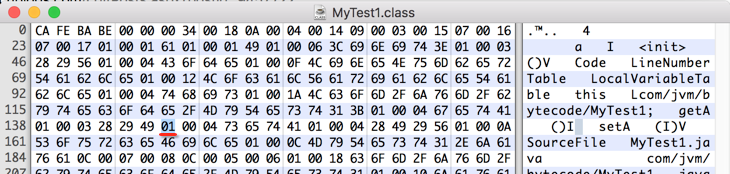
同样的类型,不多说,直接往下再看两个字节来决定字符串的长度:
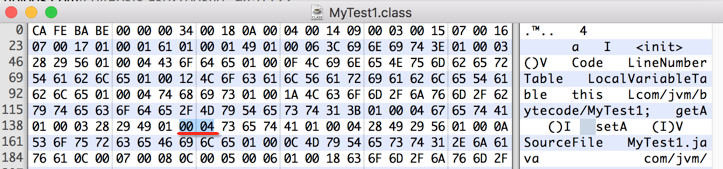
占四个字节,于是乎往后再数四个字节:
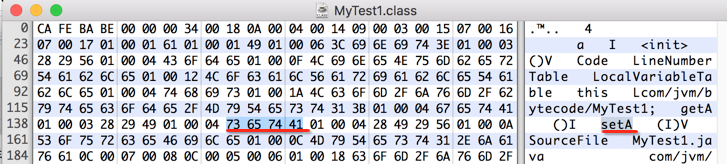
对一下javap -verbose:
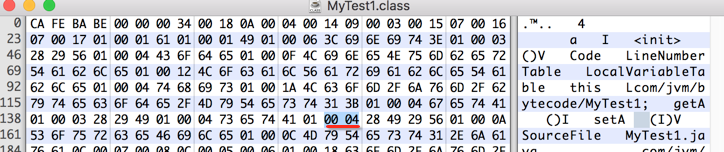
继续往下,读一个字节:

再数2个字节:
字节码整体结构分解: