在进行回调函数的项目时,必须要了解Python递归函数的内在原理,听说回调函数和递归函数有着很深的渊源。
之前学习Python因为偷懒,所以直接是看视频的,没有完整的自己敲代码,写demo。所以对这些基本的内容,并没有完全的掌握,后来师兄说,必须要看书,自己敲代码。直到真的遇到问题,找不到视频教程的时候,才知道,书还是需要看的,很多思路流程,视频上是很难被讲清楚的。当然作为一个知识的预接受,看视频还真是一个很舒服的学习方式~
笔记流程:最简单的递归函数流程;函数的执行流程分析;尾递归的优化
不务正业了好久,本来只是想简单的写一个demo,但总想加点有趣的交互式操作~
1、最简单的递归函数流程:贴代码吧:
import sys
def fibonacci(n):#斐波那契数列计算函数
if n<1:
print"please enter an integer greater than 1"
return -1
elif n==1:
return 1
elif n==2:
return 1
else:
return func(n-1)+func(n-2)
def factorial(n):#阶乘函数
if n==1:
return 1
else:
return n*factorial(n-1)
func_name = ["fibonacci","factorial"]#函数名列表
def main():
print"func list:"
for index,name in enumerate(func_name):#可以获取函数的name和下标的for循环
print "the",str(index+1),"is:",name
func_n = input("please select your function:")#输入想要执行的函数
n = input("please input an integer:")#输入需要计算的n
result = globals().get(func_name[func_n-1])(n)#通过字符串执行对应的函数
print"result is %d"%result
if __name__ == "__main__":
main() 执行效果:
func list:
the 1 is: fibonacci
the 2 is: factorial
please select your function:2
please input an integer:12
result is 479001600经实验,在阶乘函数中,n = 998时还可以正常输出值,999就会报错:RuntimeError: maximum recursion depth exceeded
因为系统默认的递归深度就是999.如果想改变的话,可以自我修改,需要加入这行代码:
import sys
sys.setrecursionlimit(1000000) #例如这里设置为一百万 经实验,效果不错~
2、递归执行过程分析:
这里主要借鉴《Python3.5从零开始学》这本书。
理论上,所有的递归函数都可以写成循环的方式,不过循环的逻辑没有递归清晰,像我这种逻辑不强的人,感觉还是循环清晰~
使用递归函数需要注意栈溢出。函数调用是通过栈这种数据结构实现的,每当进入一个函数调用,栈就会增加一层栈帧,每当函数返回,栈就会减少一层栈帧,所以系统一般会默认到999报错。
对于阶乘递归函数的流程,输入n=5:
result = f(5) = 5*f(4) = 5*(4*f(3)) = 5*(4*(3*f(2))) = 5*(4*(3*(2*f(1)))) = 5*(4*(3*(2*(*1))))) = 120
对于斐波那契数列,输入n=5:
result = f(5) = f(4)+f(3) = (f(3)+f(2)) + (f(2)+f(1)) = ((f(2)+f(1))+1) +(1+1) = 5
可以画一个流程图
算了,Ubuntu没有找到合适的画图软件,选择放弃。
阶乘的大概的流程就是,先进入函数f,然后判断n的值,进入return,返回值为n*f(n-1),因此得继续开一个函数,一直伸长到第n个函数f(1),在能进入n的判断n==1:return 1。这时候不会新建函数,所有的都是数值计算,因此整体结束。
至于递归的优点,逻辑清晰,可能是程序计算的逻辑清晰,但是编程的时候,设置判断条件的时候,很明显就得逆向思维才能设置好嘛!
至于斐波那契的流程就更有趣了,这是类似于一个二叉树式的函数新建,具体的可以在b站搜小甲鱼的Python递归函数,这里有一些图的展示。
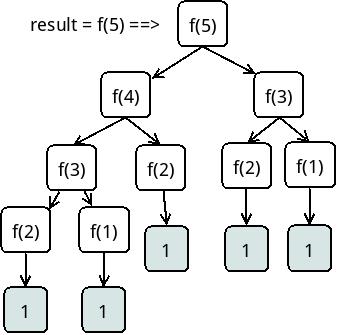
可以看出这样的会打开一个满二叉树的函数,具体多少个的计算公式,我就不是很清楚了。
然后我们需要进行一个尾递归优化——
3、尾递归优化:
尾递归定义:指函数返回时调用函数本身,并且return语句不能包含表达式,函数的自变量可以含有表达式。这样编译器会对尾递归进行优化,使得整个过程无论调用多少次函数,都会只占用一个栈帧,从而避免栈溢出的报错,虽然不知道这样会不会优化内存的占用,我们先来试试是否栈帧报错。
先是阶乘的优化:
def new_factorial(n):
return new_factorial_iter(n,1)
def new_factorial_iter(num,product):
if num == 1:
return product
return new_factorial_iter(num-1,num*product)调用情况如下:new_factorial(5) = n_f_iter(5,1) = n_f_iter(4,5*1) = n_f_iter(3,4*5) = n_f_iter(2,3*4*5) = n_f_iter(1,2*3*4*5)=120
在这篇博客中,博主提供了一种思路,说了,虽然只是一个栈帧,但是仍然会产生递归深度报错。
没办法,我只能直接讲阈值调到1000000~
尴尬~