一个message,序列化时首先就算这个message所有filed序列化需要占用的字节长度,计算这个长度是非常简单的,因为protobuf中每种类型的filed所占用的字节数是已知的(bytes、string除外),只需要累加即可。这个长度就是serializedSize,32为integer,在protobuf的某些序列化方式中可能使用varint32(一个压缩的、根据数字区间,使用不同字节长度的int);
此后是filed列表输出,每个filed输出包含int32(tag,type)和value的字节数据,我们知道每个filed都有一个唯一的数字tag表示它的index位置,type为字段的类型;如果filed为string、bytes类型,还会在value之前额外的补充添加一个varint32类型的数字,表示string、bytes的字节长度。
消息经过序列化后会成为一个二进制数据流,该流中的数据为一系列的 Key-Value 对,如下图
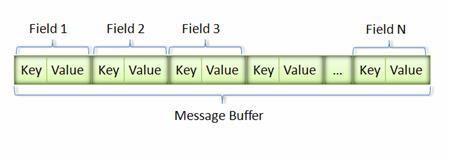
二进制格式的message使用数字标签作为key,Key 用来标识具体的 field,在解包的时候,Protocol Buffer 根据 Key 就可以知道相应的 Value 应该对应于消息中的哪一个 field。
那么在反序列化的时候,首先读取一个32为的int表示serializedSize,然后读取serializedSize个字节保存在一个bytebuffer中,即读取一个完整的package。然后读取一个int32数字,从这个数字中解析出tag和type,如果type为string、bytes,然后补充读取一个varint32就知道了string的字节长度了,此后根据type或者字节长度,读取后续的字节数组并转换成java type。重复上述操作,直到整个package解析完毕。
采用这种 Key-Pair 结构无需使用分隔符来分割不同的 Field。对于可选的 Field,如果消息中不存在该 field,那么在最终的 Message Buffer 中就没有该 field,这些特性都有助于节约消息本身的大小。
上边我们说,“二进制格式的message使用数字标签作为key”,此处的数字标签,并非单纯的数字标签,而是数字标签与传输类型的组合,根据传输类型能够确定出值的长度。
key的定义:
(field_number >> 3) | wire_type
Key 由两部分组成。第一部分是 field_number,第二部分为 wire_type。表示 Value 的传输类型。也就是说,key中的后三位,是值的传输类型
Wire Type 可能的类型如下表所示:
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimi | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | Groups (deprecated) |
| 4 | End group | Groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |