今天接着分析上次没有分析完的i.MX6网卡驱动程序。上一篇分析了iMX6网卡驱动程序的driver与device的加载过程(点击可以查看上一篇文章),这篇我们来分析一下MAC层,物理层接口以及1588协议支持的代码。
首先分析MAC层的初始化函数fec_enet_init():、
/*
* XXX: We need to clean up on failure exits here.
*
*/
static int fec_enet_init(struct net_device *ndev)
{
struct fec_enet_private *fep = netdev_priv(ndev);
struct bufdesc *cbd_base;
struct bufdesc *bdp;
int i;
/* Allocate memory for buffer descriptors. */
cbd_base = dma_alloc_noncacheable(NULL, BUFDES_SIZE, &fep->bd_dma,
GFP_KERNEL);
if (!cbd_base) {
printk("FEC: allocate descriptor memory failed?\n");
return -ENOMEM;
}
spin_lock_init(&fep->hw_lock);
fep->netdev = ndev;
/* Get the Ethernet address */
fec_get_mac(ndev);
/* Set receive and transmit descriptor base. */
fep->rx_bd_base = cbd_base;
fep->tx_bd_base = cbd_base + RX_RING_SIZE;
/* The FEC Ethernet specific entries in the device structure */
ndev->watchdog_timeo = TX_TIMEOUT;
ndev->netdev_ops = &fec_netdev_ops;
ndev->ethtool_ops = &fec_enet_ethtool_ops;
fep->use_napi = FEC_NAPI_ENABLE;
fep->napi_weight = FEC_NAPI_WEIGHT;
if (fep->use_napi) {
fec_rx_int_is_enabled(ndev, false);
netif_napi_add(ndev, &fep->napi, fec_rx_poll, fep->napi_weight);
}
/* Initialize the receive buffer descriptors. */
bdp = fep->rx_bd_base;
for (i = 0; i < RX_RING_SIZE; i++) {
/* Initialize the BD for every fragment in the page. */
bdp->cbd_sc = 0;
bdp->cbd_bufaddr = 0;
bdp++;
}
/* Set the last buffer to wrap */
bdp--;
bdp->cbd_sc |= BD_SC_WRAP;
/* Init transmit descriptors */
fec_enet_txbd_init(ndev);
fec_restart(ndev, 0);
return 0;
}从这个函数传进来的参数net_device可以知道,这个函数可以通过netdev_priv(ndev)获取到之前alloc_etherdev()分配的指向设备私有数据的指针,如下:
ndev = alloc_etherdev(sizeof(struct fec_enet_private));
struct fec_enet_private *fep = netdev_priv(ndev);
这种通过结构体内部的指针传递私有数据的方式在driver中非常常见。
函数开头即为为ethernet controller的缓冲区描述符分配内存:
/* Allocate memory for buffer descriptors. */
cbd_base = dma_alloc_noncacheable(NULL, BUFDES_SIZE, &fep->bd_dma,
GFP_KERNEL);
if (!cbd_base) {
printk("FEC: allocate descriptor memory failed?\n");
return -ENOMEM;
}这里分配的内存的大小为BUFDES_SIZE:
#define BUFDES_SIZE ((RX_RING_SIZE + TX_RING_SIZE) * sizeof(struct bufdesc))
由该宏可知,为DMA的缓冲区描述符分配的大小为(tx buffer个数+rx buffer个数)×buffer描述符大小。这个很好理解,这里不多做解释。至于为什么用dma_alloc_noncacheable这个函数分配内存,这是因为buffer描述符这段内存会被CPU和DMA控制器以不可预知的方式访问,这就涉及到Cache一致性问题,这里采用了dma_alloc_noncacheable()函数,即DMA一致性映射。在Linux内核中解决Cache一致性问题,有两种方案:DMA流式映射和DMA一致性映射。关于这方面的问题,个人目前不是很懂,以后有机会去研究一下。关于这两者的区别在《Understanding Linux Kernel》以及《LDD3》中均有介绍,也可以参考博客:点击链接查看
继续分析fec_enet_init函数:
spin_lock_init(&fep->hw_lock); // 初始化自旋锁
fep->netdev = ndev; //把net_device地址传给netdev结构体。
/* Get the Ethernet address */
fec_get_mac(ndev); //从多个地方获取mac地址分析一下fec_get_mac(ndev)的函数内容,如下:
/* ------------------------------------------------------------------------- */
static void __inline__ fec_get_mac(struct net_device *ndev)
{
struct fec_enet_private *fep = netdev_priv(ndev);
struct fec_platform_data *pdata = fep->pdev->dev.platform_data;
unsigned char *iap, tmpaddr[ETH_ALEN];
/*
* try to get mac address in following order:
*
* 1) module parameter via kernel command line in form
* fec.macaddr=0x00,0x04,0x9f,0x01,0x30,0xe0
*/
iap = macaddr;
/*
* 2) from flash or fuse (via platform data)
*/
if (!is_valid_ether_addr(iap)) {
#ifdef CONFIG_M5272
if (FEC_FLASHMAC)
iap = (unsigned char *)FEC_FLASHMAC;
#else //执行这个
if (pdata)
memcpy(iap, pdata->mac, ETH_ALEN);
#endif
}
/*
* 3) FEC mac registers set by bootloader
*/
if (!is_valid_ether_addr(iap)) {
*((unsigned long *) &tmpaddr[0]) =
be32_to_cpu(readl(fep->hwp + FEC_ADDR_LOW));
*((unsigned short *) &tmpaddr[4]) =
be16_to_cpu(readl(fep->hwp + FEC_ADDR_HIGH) >> 16);
iap = &tmpaddr[0];
}
memcpy(ndev->dev_addr, iap, ETH_ALEN);
/* Adjust MAC if using macaddr */
if (iap == macaddr)
ndev->dev_addr[ETH_ALEN-1] = macaddr[ETH_ALEN-1] + fep->pdev->id;
}分析以上代码:
1)首先是从全局变量macaddr获取MAC地址,macaddr定义相关的代码如下:
iap = macaddr;macaddr的定义为:
static unsigned char macaddr[ETH_ALEN];
module_param_array(macaddr, byte, NULL, 0);
MODULE_PARM_DESC(macaddr, "FEC Ethernet MAC address");
__setup("fec_mac=", fec_mac_addr_setup);这里的__setup是用来从uboot传给内核的启动参数中捕获fec_mac(即mac地址)参数,并将该参数传递给fec_mac_addr_setup(char *mac_addr)函数进行解析的。如果uboot中没有传递mac参数,那么macaddr数组中的成员全是0。
2)检测 1)中的MAC地址是否合法,如果不合法,则从设备的私有数据获得MAC地址(前提是pdata不为空)。
3)检测 2)中的MAC地址是否合法,如果不合法,则从Ethernet控制器的MAC寄存器来读取MAC地址。
最后执行下面这行代码,将MAC地址传送给net_device结构体中的dev_addr变量:
memcpy(ndev->dev_addr, iap, ETH_ALEN);接着回到fec_get_mac函数继续分析代码,接下来执行:
/* Set receive and transmit descriptor base. */
fep->rx_bd_base = cbd_base;
fep->tx_bd_base = cbd_base + RX_RING_SIZE;上面代码是设置rx_bd_base 和tx_bd_base,即rx_buffer_descriptor_base和tx_buffer_descriptor_base。
接下来的代码主要设置net_device 以及fec_enet_private的结构体参数:
/* The FEC Ethernet specific entries in the device structure */
ndev->watchdog_timeo = TX_TIMEOUT;
ndev->netdev_ops = &fec_netdev_ops;
ndev->ethtool_ops = &fec_enet_ethtool_ops;
fep->use_napi = FEC_NAPI_ENABLE;
fep->napi_weight = FEC_NAPI_WEIGHT;
if (fep->use_napi) {
fec_rx_int_is_enabled(ndev, false);
netif_napi_add(ndev, &fep->napi, fec_rx_poll, fep->napi_weight);
}
上面的fec_netdev_ops与fec_enet_ethtool_ops是两个非常重要的结构体指针,我们放到后面分析。先分析剩下的内容。
这里有一个新的变量:use_napi =>理解为new api。通过查阅资料得知:它主要为了提升在网络负荷较大时的性能。一般来说,网络接收数据包是通过中断来通知内核的,但是当网络负荷较大时,napi会改为轮询的方式接收数据包。这样会显得更加高效。然后当网络负荷较小时,napi会将轮询改为中断的方式将通知内核。napi_weight的值,我参考别人的说法,大概的理解应该是是否开启轮询的一个权值,一般取64较多。接着就是对开启napi的一个判断了,开启了,则将rx中断禁止。然后注册napi,同时提供一个轮询的函数:fec_rx_poll,这个也放到后面分析。
接着分析代码,现在到了初始化rx_buffer_descriptors:
/* Initialize the receive buffer descriptors. */
bdp = fep->rx_bd_base;
for (i = 0; i < RX_RING_SIZE; i++) {
/* Initialize the BD for every fragment in the page. */
bdp->cbd_sc = 0;
bdp->cbd_bufaddr = 0;
bdp++;
}
/* Set the last buffer to wrap */
bdp--;
bdp->cbd_sc |= BD_SC_WRAP;然后初始化tx _buffer_descriptor(原理与rx相同,所以直接调用了函数):
/* Init transmit descriptors */
fec_enet_txbd_init(ndev);最后就是整个Ethernet restart:
fec_restart(ndev, 0);下面我们来分析fec_restart这个函数,由于函数内容较多,下面内不整体贴代码了,边分析边贴代码:
一开始就是设置寄存器,注释已经很清楚了:
/* Whack a reset. We should wait for this. */
writel(1, fep->hwp + FEC_ECNTRL);
udelay(10);
/* if uboot don't set MAC address, get MAC address
* from command line; if command line don't set MAC
* address, get from OCOTP; otherwise, allocate random
* address.
*/
memcpy(&temp_mac, dev->dev_addr, ETH_ALEN);
writel(cpu_to_be32(temp_mac[0]), fep->hwp + FEC_ADDR_LOW);
writel(cpu_to_be32(temp_mac[1]), fep->hwp + FEC_ADDR_HIGH);
/* Clear any outstanding interrupt. */
writel(0xffc00000, fep->hwp + FEC_IEVENT);
/* Reset all multicast. */
writel(0, fep->hwp + FEC_GRP_HASH_TABLE_HIGH);
writel(0, fep->hwp + FEC_GRP_HASH_TABLE_LOW);
#ifndef CONFIG_M5272
writel(0, fep->hwp + FEC_HASH_TABLE_HIGH);
writel(0, fep->hwp + FEC_HASH_TABLE_LOW);
#endif
/* Set maximum receive buffer size. */
writel(PKT_MAXBLR_SIZE, fep->hwp + FEC_R_BUFF_SIZE);
/* Set receive and transmit descriptor base. */
writel(fep->bd_dma, fep->hwp + FEC_R_DES_START);
writel((unsigned long)fep->bd_dma + sizeof(struct bufdesc) * RX_RING_SIZE,
fep->hwp + FEC_X_DES_START);上面函数中最后一句,是设置rx与tx的描述符的基地址。这是由于DMA控制器访问的是物理地址,所以我们需要把rx/tx的基地址,写进寄存器。fep->bd_dma的值是在dma_alloc_noncacheable()中赋值的,同样地也是RX地址在前,TX地址在后。
接下来的代码,这里主要是针对descriptor指针的初始化:
/* Reinit transmit descriptors */
fec_enet_txbd_init(dev);
fep->dirty_tx = fep->cur_tx = fep->tx_bd_base;
fep->cur_rx = fep->rx_bd_base;
/* Reset SKB transmit buffers. */
fep->skb_cur = fep->skb_dirty = 0;
for (i = 0; i <= TX_RING_MOD_MASK; i++) {
if (fep->tx_skbuff[i]) {
dev_kfree_skb_any(fep->tx_skbuff[i]);
fep->tx_skbuff[i] = NULL;
}
}上面代码中dirty_tx 代表还没有释放的buffer对应的descriptor,cur_tx/cur_rx分别代表当前填充好的buffer对应的descriptor,最后复位Socket Buffer 发送缓冲区的内容,这里也有两个参数:skb_cur,skb_dirty:分别代表当前的与卫视放的Socket Buffer。同时遍历整个tx_skbuff[]指针数组,释放释放非空数组。
接下来是设置半双工或者全双工模式,默认情况下是半双工模式(即发送数据报文时不接收):
/* Enable MII mode */
if (duplex) {
/* MII enable / FD enable */
writel(OPT_FRAME_SIZE | 0x04, fep->hwp + FEC_R_CNTRL);
writel(0x04, fep->hwp + FEC_X_CNTRL);
} else {
/* MII enable / No Rcv on Xmit */
writel(OPT_FRAME_SIZE | 0x06, fep->hwp + FEC_R_CNTRL);
writel(0x0, fep->hwp + FEC_X_CNTRL);
}
fep->full_duplex = duplex;
/* Set MII speed */
writel(fep->phy_speed, fep->hwp + FEC_MII_SPEED);下面是设置物理接口的相关函数(这里不分析):
/*
* The phy interface and speed need to get configured
* differently on enet-mac.
*/
if (id_entry->driver_data & FEC_QUIRK_ENET_MAC) {
val = readl(fep->hwp + FEC_R_CNTRL);
/* MII or RMII */
if (fep->phy_interface == PHY_INTERFACE_MODE_RGMII)
val |= (1 << 6);
else if (fep->phy_interface == PHY_INTERFACE_MODE_RMII)
val |= (1 << 8);
else
val &= ~(1 << 8);
/* 10M or 100M */
if (fep->phy_dev && fep->phy_dev->speed == SPEED_100)
val &= ~(1 << 9);
else
val |= (1 << 9);
/* Enable pause frame
* ENET pause frame has two issues as ticket TKT116501
* The issues have been fixed on Rigel TO1.1 and Arik TO1.2
*/
if ((cpu_is_mx6q() &&
(mx6q_revision() >= IMX_CHIP_REVISION_1_2)) ||
(cpu_is_mx6dl() &&
(mx6dl_revision() >= IMX_CHIP_REVISION_1_1)))
val |= FEC_ENET_FCE;
writel(val, fep->hwp + FEC_R_CNTRL);
}下面是开启IEEE 1588的定时器:
if (fep->ptimer_present) {
/* Set Timer count */
ret = fec_ptp_start(fep->ptp_priv);
if (ret) {
fep->ptimer_present = 0;
reg = 0x0;
} else
#if defined(CONFIG_SOC_IMX28) || defined(CONFIG_ARCH_MX6)
reg = 0x00000010;
#else
reg = 0x0;
#endif
} else
reg = 0x0;然后下面的代码都是与寄存器相关的一些接口,这里就不分析了,我们的主要目的是理解数据是在哪里通过标准的以太网网络协议栈传送数据的。
那么对于MAC层相关的driver函数:fec_enet_init这个函数,就剩下:fec_netdev_ops入口与fec_enet_ethtool_ops入口两个函数需要分析了。
fec_netdev_ops:
static const struct net_device_ops fec_netdev_ops = {
.ndo_open = fec_enet_open,
.ndo_stop = fec_enet_close,
.ndo_start_xmit = fec_enet_start_xmit,
.ndo_set_multicast_list = set_multicast_list,
.ndo_change_mtu = eth_change_mtu,
.ndo_validate_addr = eth_validate_addr,
.ndo_tx_timeout = fec_timeout,
.ndo_set_mac_address = fec_set_mac_address,
.ndo_do_ioctl = fec_enet_ioctl,
#ifdef CONFIG_NET_POLL_CONTROLLER
.ndo_poll_controller = fec_enet_netpoll,
#endif
};这里重点介绍前面三个函数,即:fec_enet_open,fec_enet_close,fec_enet_start_xmit。
先分析fec_enet_open函数:
这个open函数对应着用户空间的ifconfig的up操作,当在用户空间执行ifconfig eth0 up,就会执行这个open函数。
static int
fec_enet_open(struct net_device *ndev)
{
struct fec_enet_private *fep = netdev_priv(ndev);
struct fec_platform_data *pdata = fep->pdev->dev.platform_data;
int ret;
if (fep->use_napi)
napi_enable(&fep->napi);
/* I should reset the ring buffers here, but I don't yet know
* a simple way to do that.
*/
clk_enable(fep->clk);
ret = fec_enet_alloc_buffers(ndev);
if (ret)
return ret;
/* Probe and connect to PHY when open the interface */
ret = fec_enet_mii_probe(ndev);
if (ret) {
fec_enet_free_buffers(ndev);
return ret;
}
phy_start(fep->phy_dev);
netif_start_queue(ndev);
fep->opened = 1;
ret = -EINVAL;
if (pdata->init && pdata->init(fep->phy_dev))
return ret;
return 0;
}这个open函数首先是napi的设置,如果开启了napi,则enable它,然后是clock的enable。
if (fep->use_napi)
napi_enable(&fep->napi);
/* I should reset the ring buffers here, but I don't yet know
* a simple way to do that.
*/
clk_enable(fep->clk);接着是为接收缓冲区分配buffer,前面说过tx buffer是由内核的网络子系统分配的, 而rx buffer是由Ethernet驱动分配。
ret = fec_enet_alloc_buffers(ndev);
if (ret)
return ret;这个函数与之前初始化buffer descriptor的类似,这里面的rx_socket_buffer为流式映射(我个人对这个不懂,在网上查的资料):
多说一下:
DMA_FROM_DEVICE:
传输方向是从Device那边往RAM传送数据,因此,其实是接收外部发送的数据。
DMA_TO_DEVICE:
传输方向是从RAM往Device传送数据,因此,其实是发送数据到外部。
接收缓冲区的示意图如下:这里要注意的是接收缓冲区是由Ethernet driver分配的,不是由内核网络子系统分配的。
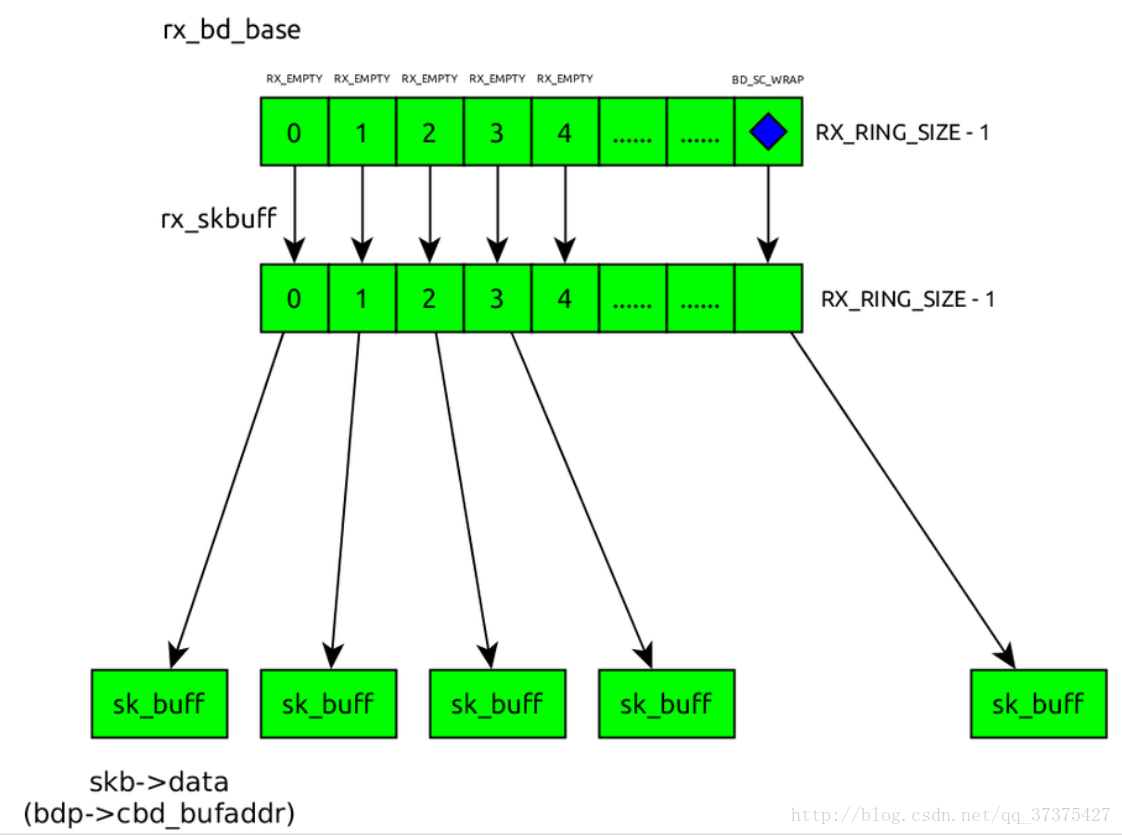
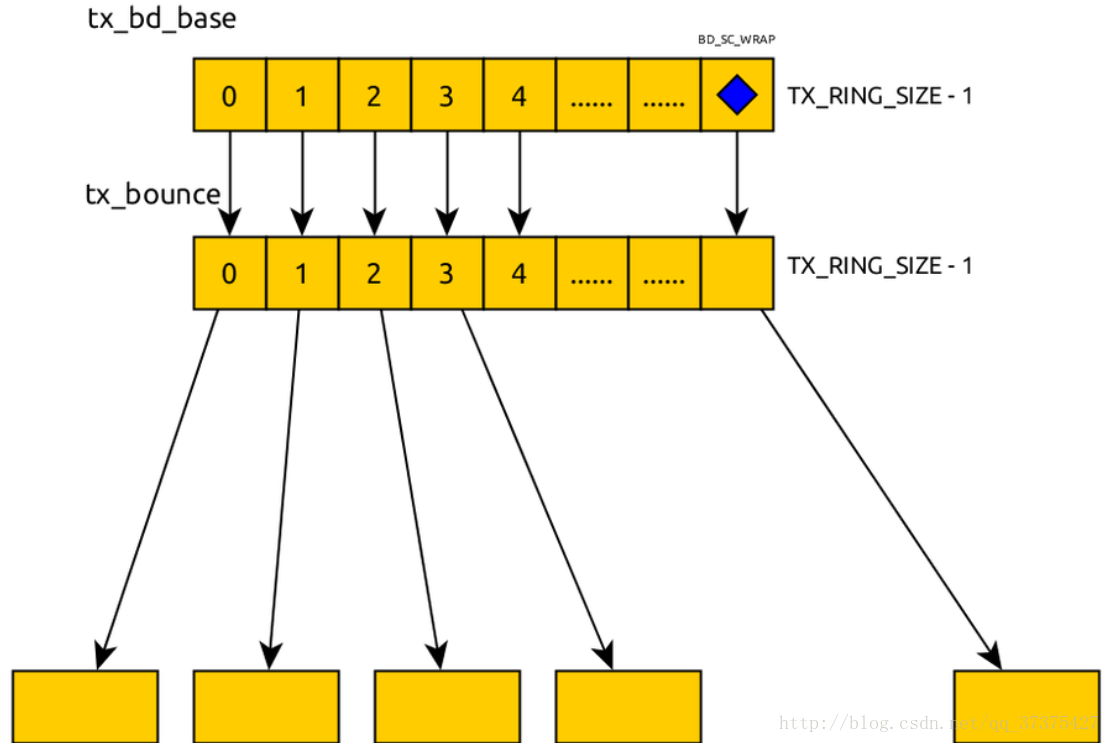
对于tx buffer descriptor部分来说,这里tx_bounce指向的分配的内存是用来进行buffer字节对齐的,对应的tx buffer descriptor相关的示意图:
接下来再回到open函数的分析:接下来的代码是与物理层相关的代码:
/* Probe and connect to PHY when open the interface */
ret = fec_enet_mii_probe(ndev);
if (ret) {
fec_enet_free_buffers(ndev);
return ret;
}
phy_start(fep->phy_dev);
netif_start_queue(ndev);
fep->opened = 1;
ret = -EINVAL;
if (pdata->init && pdata->init(fep->phy_dev))
return ret;
return 0;这部分函数,等到MAC层相关函数全部讲解完,再回来讲解。
然后就是fec_enet_close函数,与open函数做的事情相反,这里不再分析。
下面讲述:fec_enet_start_xmit函数。(函数内容太多不整体复制粘贴了,下面一一讲解粘贴):
首先是关闭一个全局中断:
spin_lock_irqsave(&fep->hw_lock, flags);接着判断link是否断开:
if (!fep->link) {
/* Link is down or autonegotiation is in progress. */
netif_stop_queue(ndev);
spin_unlock_irqrestore(&fep->hw_lock, flags);
return NETDEV_TX_BUSY;
}接着从待发送队列获取待发送buffer对应的buffer描述符指针,并获取当前描述符的状态:
/* Fill in a Tx ring entry */
bdp = fep->cur_tx;
status = bdp->cbd_sc;接着判断buffer描述符的准备状态是否准备好:
if (status & BD_ENET_TX_READY) {
/* Ooops. All transmit buffers are full. Bail out.
* This should not happen, since ndev->tbusy should be set.
*/
printk("%s: tx queue full!.\n", ndev->name);
netif_stop_queue(ndev);
spin_unlock_irqrestore(&fep->hw_lock, flags);
return NETDEV_TX_BUSY;
}如果当前buffer描述符的BD_ENET_TX_READY值没有被DMA控制器清0,则表示buffer还没有被传送出去,也就是发送队列满,因此我们需要让内核网络系统的发送队列stop,并且解除禁止的中断,恢复中断现场。最后返回BUSY状态。
下面接着是队列没有满的情况下执行的代码:
/* Clear all of the status flags */
status &= ~BD_ENET_TX_STATS;
/* Set buffer length and buffer pointer */
bufaddr = skb->data;
bdp->cbd_datlen = skb->len;很简单,先把从buffer获取的描述符status 清零,并且从内核网络层传过来的socket buffer结构体中获取要发送的buffer的逻辑地址(注意是逻辑地址,后面还会有物理地址)和长度。
接着是字节对齐:
/*
* On some FEC implementations data must be aligned on
* 4-byte boundaries. Use bounce buffers to copy data
* and get it aligned. Ugh.
*/
if (((unsigned long) bufaddr) & FEC_ALIGNMENT) {
unsigned int index;
index = bdp - fep->tx_bd_base;
bufaddr = PTR_ALIGN(fep->tx_bounce[index], FEC_ALIGNMENT + 1);
memcpy(bufaddr, (void *)skb->data, skb->len);
}Ethercat driver单独分配了一个tx_bounce[]数组进行字节的对齐。
接着是IEEE 1588协议的支持,即标记时间戳:
if (fep->ptimer_present) {
if (fec_ptp_do_txstamp(skb)) {
estatus = BD_ENET_TX_TS;
status |= BD_ENET_TX_PTP;
} else
estatus = 0;
#ifdef CONFIG_ENHANCED_BD
bdp->cbd_esc = (estatus | BD_ENET_TX_INT);
bdp->cbd_bdu = 0;
#endif同时这里还对CONFIG_ENHANCED_BD支持。
接着是大小端的转换,有一部分IP用的是大端模式:
/*
* Some design made an incorrect assumption on endian mode of
* the system that it's running on. As the result, driver has to
* swap every frame going to and coming from the controller.
*/
if (id_entry->driver_data & FEC_QUIRK_SWAP_FRAME)
swap_buffer(bufaddr, skb->len);接着把socket buffer指针存放在之前分配好的tx_skbuff[]指针数组:
/* Save skb pointer */
fep->tx_skbuff[fep->skb_cur] = skb;
ndev->stats.tx_bytes += skb->len;
fep->skb_cur = (fep->skb_cur+1) & TX_RING_MOD_MASK;同时对net_device 结构体中的统计数据进行更新。然后TX指针数组下标递增。
接着就是对待发送的socket buffer进行DMA映射,映射的过程也就是刷新data cache的过程:
/* Push the data cache so the CPM does not get stale memory
* data.
*/
bdp->cbd_bufaddr = dma_map_single(&fep->pdev->dev, bufaddr,
FEC_ENET_TX_FRSIZE, DMA_TO_DEVICE);
/* Send it on its way. Tell FEC it's ready, interrupt when done,
* it's the last BD of the frame, and to put the CRC on the end.
*/
status |= (BD_ENET_TX_READY | BD_ENET_TX_INTR
| BD_ENET_TX_LAST | BD_ENET_TX_TC);
bdp->cbd_sc = status;
映射完毕后,标记status 的READY,INTR,LAST,TC的值。并将当前的socket buffer对应的bufferdescriptor的状态字节写回。
下面就是写寄存器触发硬件的发送操作:
/* Trigger transmission start */
writel(0, fep->hwp + FEC_X_DES_ACTIVE);下面的代码我不理解:
bdp_pre = fec_enet_get_pre_txbd(ndev);
if ((id_entry->driver_data & FEC_QUIRK_BUG_TKT168103) &&
!(bdp_pre->cbd_sc & BD_ENET_TX_READY))
schedule_delayed_work(&fep->fixup_trigger_tx,
msecs_to_jiffies(1));网上大神解释:只能理解为IC的BUG 。本质上就是DMA发送到某个位置并满足某些条件额情况下,调度工作队列来,工作队列中就是解决这个BUG的代码。
下面代码递增的描述符,如果这是环中最后一个BD,则从头再次开始。
/* If this was the last BD in the ring, start at the beginning again. */
if (status & BD_ENET_TX_WRAP)
bdp = fep->tx_bd_base;
else
bdp++;接下来的代码,如果当前的cur_tx与dirty_tx指向同一个指针地址的话,表示软件还没有来得及释放发送完成的buffer:
if (bdp == fep->dirty_tx) {
fep->tx_full = 1;
netif_stop_queue(ndev);
}
fep->cur_tx = bdp;这里的full区别于一开始的full,一开始的full是由于DMA传送比发送函数的填充要慢,而这里的full是由socket buffer释放地比发送函数填充地慢导致的。最后cur_tx指针指向当前的描述符,并恢复中断上下文,返回发送成功:
spin_unlock_irqrestore(&fep->hw_lock, flags);
return NETDEV_TX_OK;如果实际硬件发送成功,会触发发送中断,中断入口函数是在probe函数中注册的fec_enet_interrupt(),并且接受网络数据包传送过来的数据,也要触发这个中断。下面我们来分析这个中断函数:
fec_enet_interrupt():
do {
int_events = readl(fep->hwp + FEC_IEVENT);
writel(int_events, fep->hwp + FEC_IEVENT);
…………
…………
} while (int_events);大家都知道顶半部做重要的事,底半部做不重要的事。并且是一个bo while循环。首先是读取FEC_IEVENT寄存器,然后再写相同的值清掉这些寄存器位,这里很明显是写1清零,然后再读有没有中断过来,有的话再次这处理。
下面着重分析while循环里面的内容:
如果是接收中断的话:
if (int_events & FEC_ENET_RXF) {
ret = IRQ_HANDLED;
spin_lock_irqsave(&fep->hw_lock, flags);
if (fep->use_napi) {
/* Disable the RX interrupt */
if (napi_schedule_prep(&fep->napi)) {
fec_rx_int_is_enabled(ndev, false);
__napi_schedule(&fep->napi);
}
} else
fec_enet_rx(ndev);
spin_unlock_irqrestore(&fep->hw_lock, flags);
}那么首先是进入临界段操作,然后使判断是不是用的napi,如果是的话就调用napi_schedule_prep()函数检测队列是否已经在调度,如果没有(即返回true)则标记napi开始运行。然后if条件,关闭rx中断并调度napi队列。如果不是napi的话那么就直接执行fec_enet_rx()函数。
接着如果是发送中断的话:
/* Transmit OK, or non-fatal error. Update the buffer
* descriptors. FEC handles all errors, we just discover
* them as part of the transmit process.
*/
if (int_events & FEC_ENET_TXF) {
ret = IRQ_HANDLED;
fec_enet_tx(ndev);
}直接执行fec_enet_tx()函数,while循环后面还有两个中断,分别是timestamp定时器中断和MII中断,这里略过。
下面我们着重分析:fec_enet_tx()和fec_enet_rx()函数。
首先看fec_enet_tx()函数:
首先获取dirty_tx指向的描述符:
bdp = fep->dirty_tx;然后就是一个大的while循环:
while (((status = bdp->cbd_sc) & BD_ENET_TX_READY) == 0) {
…………
…………
/* Update pointer to next buffer descriptor to be transmitted */
if (status & BD_ENET_TX_WRAP)
bdp = fep->tx_bd_base;
else
bdp++;
/* Since we have freed up a buffer, the ring is no longer full
*/
if (fep->tx_full) {
fep->tx_full = 0;
if (netif_queue_stopped(ndev))
netif_wake_queue(ndev);
}基本的循环就是一个不断递增dirty_tx指针的过程,递增一直递增到待发送buffer的描述符为止。
下面分析while循环中的代码:
if (bdp == fep->cur_tx && fep->tx_full == 0)
break;这是整个队列空的情况,此时dirty_tx和cur_tx指向同一块区域,并且tx_full为0。
队列非空之后就开始释放发送成功的缓冲区,下面是DMA UNMAP操作,这里对应的是skb = fep->tx_skbuff[fep->skb_dirty];DMA_TO_DEVICE方向。
if (bdp->cbd_bufaddr)
dma_unmap_single(&fep->pdev->dev, bdp->cbd_bufaddr,
FEC_ENET_TX_FRSIZE, DMA_TO_DEVICE);
bdp->cbd_bufaddr = 0;下面是一系列错误检查,从skb_dirty下标获取dirty(这里dirty表示使用完还没有释放)的socket buffer,判断是否非空。
skb = fep->tx_skbuff[fep->skb_dirty];
if (!skb)
break;接着是net_device结构体数据的统计:
/* Check for errors. */
if (status & (BD_ENET_TX_HB | BD_ENET_TX_LC |
BD_ENET_TX_RL | BD_ENET_TX_UN |
BD_ENET_TX_CSL)) {
ndev->stats.tx_errors++;
if (status & BD_ENET_TX_HB) /* No heartbeat */
ndev->stats.tx_heartbeat_errors++;
if (status & BD_ENET_TX_LC) /* Late collision */
ndev->stats.tx_window_errors++;
if (status & BD_ENET_TX_RL) /* Retrans limit */
ndev->stats.tx_aborted_errors++;
if (status & BD_ENET_TX_UN) /* Underrun */
ndev->stats.tx_fifo_errors++;
if (status & BD_ENET_TX_CSL) /* Carrier lost */
ndev->stats.tx_carrier_errors++;
} else {
ndev->stats.tx_packets++;
}下面这段代码是为了DBUG调试用的:
if (status & BD_ENET_TX_READY)
printk("HEY! Enet xmit interrupt and TX_READY.\n");
接着还是net_devidce的数据统计:
/* Deferred means some collisions occurred during transmit,
* but we eventually sent the packet OK.
*/
if (status & BD_ENET_TX_DEF)
ndev->stats.collisions++;下面用来标记发送的时间戳,我还不理解IEEE 1588协议及其内核驱动:
#if defined(CONFIG_ENHANCED_BD)
if (fep->ptimer_present) {
if (bdp->cbd_esc & BD_ENET_TX_TS)
fec_ptp_store_txstamp(fpp, skb, bdp);
}
#elif defined(CONFIG_IN_BAND)
if (fep->ptimer_present) {
if (status & BD_ENET_TX_PTP)
fec_ptp_store_txstamp(fpp, skb, bdp);
}
#endif
接着就是释放socket buffer,同时TX指针数组对应的成员指向NULL,skb_dirty下标递增。
/* Free the sk buffer associated with this last transmit */
dev_kfree_skb_any(skb);
fep->tx_skbuff[fep->skb_dirty] = NULL;
fep->skb_dirty = (fep->skb_dirty + 1) & TX_RING_MOD_MASK;
/* Update pointer to next buffer descriptor to be transmitted */
if (status & BD_ENET_TX_WRAP)
bdp = fep->tx_bd_base;
else
bdp++;
最后是处理tx_full为1的情况:
/* Since we have freed up a buffer, the ring is no longer full
*/
if (fep->tx_full) {
fep->tx_full = 0;
if (netif_queue_stopped(ndev))
netif_wake_queue(ndev);
}跳出了while循环之后就更新dirty_tx指针:
fep->dirty_tx = bdp;下面来看fec_enet_rx()函数:
类似于fec_enet_tx()函数,也是一个主while循环:
bdp = fep->cur_rx;
while (!((status = bdp->cbd_sc) & BD_ENET_RX_EMPTY)) {
..........
..........
/* Update BD pointer to next entry */
if (status & BD_ENET_RX_WRAP)
bdp = fep->rx_bd_base;
else
bdp++;
}
fep->cur_rx = bdp;也就是获取当前rx buffer对应的buffer描述符指针cur_rx,然后不停地判断其BD_ENET_RX_EMPTY位是否为0,如果为0则表示这个buffer已经被DMA控制器处理过,接受到了数据,然后进入while循环处理,最后再递增指针并更新cur_rx指针。
下面来看while循环里面的内容:
/* Since we have allocated space to hold a complete frame,
* the last indicator should be set.
*/
if ((status & BD_ENET_RX_LAST) == 0)
printk("FEC ENET: rcv is not +last\n");这条语句纯粹是用来debug的,一般情况下不会出现BD_ENET_RX_LAST位没有置1的情况。
接着判断物理层是否打开:
if (!fep->opened)
goto rx_processing_done;下面全是进行错误检测的以及数据统计的:
/* Check for errors. */
if (status & (BD_ENET_RX_LG | BD_ENET_RX_SH | BD_ENET_RX_NO |
BD_ENET_RX_CR | BD_ENET_RX_OV)) {
ndev->stats.rx_errors++;
if (status & (BD_ENET_RX_LG | BD_ENET_RX_SH)) {
/* Frame too long or too short. */
ndev->stats.rx_length_errors++;
}
if (status & BD_ENET_RX_NO) /* Frame alignment */
ndev->stats.rx_frame_errors++;
if (status & BD_ENET_RX_CR) /* CRC Error */
ndev->stats.rx_crc_errors++;
if (status & BD_ENET_RX_OV) /* FIFO overrun */
ndev->stats.rx_fifo_errors++;
}
/* Report late collisions as a frame error.
* On this error, the BD is closed, but we don't know what we
* have in the buffer. So, just drop this frame on the floor.
*/
if (status & BD_ENET_RX_CL) {
ndev->stats.rx_errors++;
ndev->stats.rx_frame_errors++;
goto rx_processing_done;
}接下来也是,统计接受的数据包和字节数:
/* Process the incoming frame. */
ndev->stats.rx_packets++;
pkt_len = bdp->cbd_datlen;
ndev->stats.rx_bytes += pkt_len;接着进行DMA去映射和大小端转换:
data = (__u8*)__va(bdp->cbd_bufaddr);
if (bdp->cbd_bufaddr)
dma_unmap_single(&fep->pdev->dev, bdp->cbd_bufaddr,
FEC_ENET_TX_FRSIZE, DMA_FROM_DEVICE);
if (id_entry->driver_data & FEC_QUIRK_SWAP_FRAME)
swap_buffer(data, pkt_len);
下面进行16字节边界对齐,因为包头是14字节,所以NET_IP_ALIGN为2,对齐完了以后还要处理1588的Timestamp标记。
/* This does 16 byte alignment, exactly what we need.
* The packet length includes FCS, but we don't want to
* include that when passing upstream as it messes up
* bridging applications.
*/
skb = dev_alloc_skb(pkt_len - 4 + NET_IP_ALIGN);
if (unlikely(!skb)) {
printk("%s: Memory squeeze, dropping packet.\n",
ndev->name);
ndev->stats.rx_dropped++;
} else {
skb_reserve(skb, NET_IP_ALIGN);
skb_put(skb, pkt_len - 4); /* Make room */
skb_copy_to_linear_data(skb, data, pkt_len - 4);
/* 1588 messeage TS handle */
if (fep->ptimer_present)
fec_ptp_store_rxstamp(fpp, skb, bdp);
skb->protocol = eth_type_trans(skb, ndev);
netif_rx(skb);
}对齐处理完了以后再重新建立dma映射:
bdp->cbd_bufaddr = dma_map_single(&fep->pdev->dev, data,
FEC_ENET_TX_FRSIZE, DMA_FROM_DEVICE);接下来再更新dma buffer描述符中的status字段:
rx_processing_done:
/* Clear the status flags for this buffer */
status &= ~BD_ENET_RX_STATS;
/* Mark the buffer empty */
status |= BD_ENET_RX_EMPTY;
bdp->cbd_sc = status;
#ifdef CONFIG_ENHANCED_BD
bdp->cbd_esc = BD_ENET_RX_INT;
bdp->cbd_prot = 0;
bdp->cbd_bdu = 0;
#endif
/* Update BD pointer to next entry */
if (status & BD_ENET_RX_WRAP)
bdp = fep->rx_bd_base;
else
bdp++;while循环的最后,处理输入包的同时也保持FEC运行,提高吞吐量。
/* Doing this here will keep the FEC running while we process
* incoming frames. On a heavily loaded network, we should be
* able to keep up at the expense of system resources.
*/
writel(0, fep->hwp + FEC_R_DES_ACTIVE);跳出while循环以后再更新cur_rx指针:
fep->cur_rx = bdp;到这里以太网控制器的发送和接收函数都已经分析介绍的差不多了,写一遍发现确实很乱,本身对对以太网就不太熟悉,再加上参考的网上的资料有点多。以后还是要多总结记录,不然对于内核函数,看一遍是根本记不住的。好了,大概也明白了整体的框架,细节就不去纠结了,等实力牛逼了再去看具体的实现细节代码。熬夜熬了两天,明天开始看ethercat官方提供的文档,去研究一下,如何才能改造这个网卡驱动程序,从而让数据的传送绕过标准的以太网协议,用ethercat协议进行传输数据。累死了。。。。。
想一起探讨以及获得各种学习资源加我(有我博客中写的代码的原稿):
qq:1126137994
微信:liu1126137994
可以共同交流关于嵌入式,操作系统,C++语言,C语言,数据结构等技术问题。