title: PriorityQueue and Queue源码剖析
date: 2018-3-3 23:18:40
categories:
- JDK
tags:
- JDK
- 源码学习
此博文过长,纯属自己记录的笔记,慎入。
ArrayDeque
是一个双向队列,队列的两个口都可以入队和出队操作。再进一步说,其实ArrayDeque可以说成是一个双向循环队列
defination
public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable
{
}从ArrayDeque的定义可以看到,它继承AbstractCollection,实现了Deque,Cloneable,Serializable接口。不知道看到这里你会不会发现什么,Deque接口我们在LinkedList中见过,LinkedList也是实现Deque接口的。Deque是一个双端队列,它实现于Queue接口,就是在队列的同一端即可以入队又可以出队,所以Deque即可以作为队列又可以作为栈使用。
欲知Dequeue先知Queue,jdk1.8源码如下:
public interface Queue<E> extends Collection<E> {
// 增加一个元素到队尾,如果队列已满,则抛出一个IIIegaISlabEepeplian异常
boolean add(E e);
// 添加一个元素到队尾并返回true,如果队列已满,则返回false
boolean offer(E e);
// 移除并返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常
E remove();
// 移除并返问队列头部的元素,如果队列为空,则返回null
E poll();
// 返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常
E element();
// 返问队列头部的元素,如果队列为空,则返回null
E peek()
}Queue的定义和Stack的定义差不多了。ArrayDeque并不是一个固定大小的队列,每次队列满了就会进行扩容,除非扩容至超过int的边界,才会抛出异常。所以这里的add和offer几乎是没有区别的。
// 底层用数组存储元素
private transient E[] elements;
// 队列的头部元素索引(即将pop出的一个)
private transient int head;
// 队列下一个要添加的元素索引
private transient int tail;
// 最小的初始化容量大小,需要为2的n次幂
private static final int MIN_INITIAL_CAPACITY = 8;这里的MIN_INITIAL_CAPACITY要求是2的整数次幂,我们知道在Hashmap里面,bucket桶的长度是要求2的整数次幂,这里又是什么原因呢?
看一下ArrayDeque的构造函数就知道了。
/**
* 默认构造方法,数组的初始容量为16
*/
public ArrayDeque() {
elements = (E[]) new Object[16];
}
/**
* 使用一个指定的初始容量构造一个ArrayDeque
*/
public ArrayDeque( int numElements) {
allocateElements(numElements);
}
/**
* 构造一个指定Collection集合参数的ArrayDeque
*/
public ArrayDeque(Collection<? extends E> c) {
allocateElements(c.size());
addAll(c);
}
/**
* 分配合适容量大小的数组,确保初始容量是大于指定numElements的最小的2的n次幂
*/
private void allocateElements(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// 找到大于指定容量的最小的2的n次幂
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
// 如果指定的容量小于初始容量8,则执行一下if中的逻辑操作
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1; // Good luck allocating 2 ^ 30 elements
}
elements = (E[]) new Object[initialCapacity];
}这里的代码是抄别人的,期初我也看不懂,大概的意思就是说,每次需要找到刚好大于numElementsd的2的整数次幂的整数,这些位运算,你自己去算吧。
入队操作
我们经常用到就是 add(), offer(),分别调用 addLast(), offerLast()这几个方法了。不同的是 add()系列的方法会抛异常,而offer()系列的会返回true or false. remove() poll()同理。
/**
* 增加一个元素,如果队列已满,则抛出一个IIIegaISlabEepeplian异常
*/
public boolean add(E e) {
// 调用addLast方法,将元素添加到队尾
addLast(e);
return true;
}
/**
* 添加一个元素
*/
public boolean offer(E e) {
// 调用offerLast方法,将元素添加到队尾
return offerLast(e);
}
/**
* 在队尾添加一个元素
*/
public boolean offerLast(E e) {
// 调用addLast方法,将元素添加到队尾
addLast(e);
return true;
}
/**
* 将元素添加到队尾
*/
public void addLast(E e) {
// 如果元素为null,咋抛出空指针异常
if (e == null)
throw new NullPointerException();
// 将元素e放到数组的tail位置
elements[tail ] = e;
// 判断tail和head是否相等,如果相等则对数组进行扩容
if ( (tail = (tail + 1) & ( elements.length - 1)) == head)
// 进行两倍扩容
doubleCapacity();
}(tail = (tail + 1) & ( elements.length - 1)) == head)最为精妙!
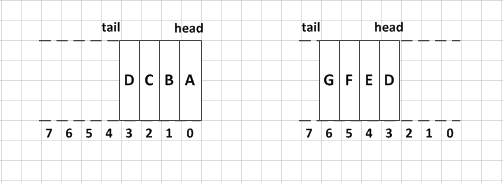
偷张别人的图解释一下。
我们假设队列初始容量为8,初始化添加,A,B,C,D四元素。分别对应数组下标0,1,2,3,但是因为这是双端队列,经过一段时间的出队,入队,可能会变成上图,右边的情况。
那么tail到达了数组末尾,再添加元素的话,怎么办, 直接扩容吗? 前面还有一段呢? 答案是不会扩容,会把元素填充到前面缺失的位置,一直到这个数组是真正的满了,才会扩容。(tail = (tail + 1) & ( elements.length - 1))只会在 head 和 tail指针相邻才会 == head然后就开始扩容。Javaer们把这个叫做,循环数组!
ArrayDeque的扩容
/**
* 数组将要满了的时候(tail==head)将,数组进行2倍扩容
*/
private void doubleCapacity() {
// 验证head和tail是否相等
assert head == tail;
int p = head ;
// 记录数组的长度
int n = elements .length;
// 计算head后面的元素个数,这里没有采用jdk中自带的英文注释right,是因为所谓队列的上下左右,只是我们看的方位不同而已,如果上面画的图,这里就应该是left而非right
int r = n - p; // number of elements to the right of p
// 将数组长度扩大2倍
int newCapacity = n << 1;
// 如果此时长度小于0,则抛出IllegalStateException异常,什么时候newCapacity会小于0呢,前面我们说过了int值<<1越界
if (newCapacity < 0)
throw new IllegalStateException( "Sorry, deque too big" );
// 创建一个长度是原数组大小2倍的新数组
Object[] a = new Object[newCapacity];
// 将原数组head后的元素都拷贝值新数组
System. arraycopy(elements, p, a, 0, r);
// 将原数组head前的元素都拷贝到新数组
System. arraycopy(elements, 0, a, r, p);
// 将新数组赋值给elements
elements = (E[])a;
// 重置head为数组的第一个位置索引0
head = 0;
// 重置tail为数组的最后一个位置索引+1((length - 1) + 1)
tail = n;
}两次复制,是因为,这个数组是分为两段的。
出队
/**
* 移除并返回队列头部的元素,如果队列为空,则抛出一个NoSuchElementException异常
*/
public E remove() {
// 调用removeFirst方法,移除队头的元素
return removeFirst();
}
/**
* @throws NoSuchElementException {@inheritDoc}
*/
public E removeFirst() {
// 调用pollFirst方法,移除并返回队头的元素
E x = pollFirst();
// 如果队列为空,则抛出NoSuchElementException异常
if (x == null)
throw new NoSuchElementException();
return x;
}
/**
* 移除并返问队列头部的元素,如果队列为空,则返回null
*/
public E poll() {
// 调用pollFirst方法,移除并返回队头的元素
return pollFirst();
}
public E pollFirst() {
int h = head ;
// 取出数组队头位置的元素
E result = elements[h]; // Element is null if deque empty
// 如果数组队头位置没有元素,则返回null值
if (result == null)
return null;
// 将数组队头位置置空,也就是删除元素
elements[h] = null; // Must null out slot
// 将head指针往前移动一个位置
head = (h + 1) & (elements .length - 1);
// 将队头元素返回
return result;
}PriorityQueue
自己在写一些算法题目的时候,特别是一些面试刁钻的搜索问题时(google有一道无序数组,寻找第K大元素,就是用构造K堆来实现的),都会用到堆排序,其实JDK已经为我们封装好了一个类似对结构的优先队列,就是这个PriorityQueue 也叫 二叉堆。
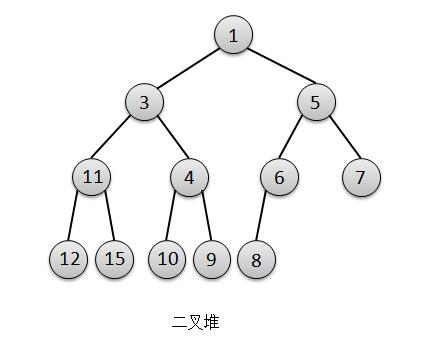
其实就是一颗完全二叉树(二叉堆),特点:在第n层深度被填满之前,不会开始填第n+1层深度,而且元素插入是从左往右填满。
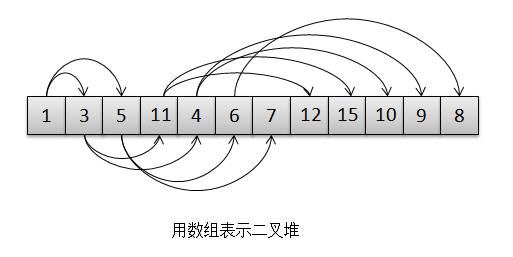
基于这个特点,二叉堆又可以用数组来表示而不是用链表
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
}底层存储
// 默认初始化大小
privatestaticfinalintDEFAULT_INITIAL_CAPACITY = 11;
//
/**
* Priority queue represented as a balanced binary heap: the two
* children of queue[n] are queue[2*n+1] and queue[2*(n+1)]. The
* priority queue is ordered by comparator, or by the elements'
* natural ordering, if comparator is null: For each node n in the
* heap and each descendant d of n, n <= d. The element with the
* lowest value is in queue[0], assuming the queue is nonempty.
*/
private transient Object[] queue ;
// 队列的大小
private int size = 0;
// 比较器
private final Comparator<? super E> comparator;
// 版本号
private transient int modCount = 0;看上面的英文注释,我的英语不好也看懂了,哈哈。
PriorityQueue()
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null); // null 为比较器,默认null
}
public PriorityQueue( int initialCapacity) {
this(initialCapacity, null);
}
/**
* 使用指定的初始大小和比较器来构造一个优先队列
*/
public PriorityQueue( int initialCapacity,
Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
// 初始大小不允许小于1
if (initialCapacity < 1)
throw new IllegalArgumentException();
// 使用指定初始大小创建数组
this.queue = new Object[initialCapacity];
// 初始化比较器
this.comparator = comparator;
}
/**
* 构造一个指定Collection集合参数的优先队列
*/
public PriorityQueue(Collection<? extends E> c) {
// 从集合c中初始化数据到队列
initFromCollection(c);
// 如果集合c是包含比较器Comparator的(SortedSet/PriorityQueue),则使用集合c的比较器来初始化队列的Comparator
if (c instanceof SortedSet)
comparator = (Comparator<? super E>)
((SortedSet<? extends E>)c).comparator();
else if (c instanceof PriorityQueue)
comparator = (Comparator<? super E>)
((PriorityQueue<? extends E>)c).comparator();
// 如果集合c没有包含比较器,则默认比较器Comparator为空
else {
comparator = null;
// 调用heapify方法重新将数据调整为一个二叉堆
heapify();
}
}
/**
* 构造一个指定PriorityQueue参数的优先队列
*/
public PriorityQueue(PriorityQueue<? extends E> c) {
comparator = (Comparator<? super E>)c.comparator();
initFromCollection(c);
}
/**
* 构造一个指定SortedSet参数的优先队列
*/
public PriorityQueue(SortedSet<? extends E> c) {
comparator = (Comparator<? super E>)c.comparator();
initFromCollection(c);
}
/**
* 从集合中初始化数据到队列
*/
private void initFromCollection(Collection<? extends E> c) {
// 将集合Collection转换为数组a
Object[] a = c.toArray();
// If c.toArray incorrectly doesn't return Object[], copy it.
// 如果转换后的数组a类型不是Object数组,则转换为Object数组
if (a.getClass() != Object[].class)
a = Arrays. copyOf(a, a.length, Object[]. class);
// 将数组a赋值给队列的底层数组queue
queue = a;
// 将队列的元素个数设置为数组a的长度
size = a.length ;
}add() 和 offer()
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
//如果压入的元素为null 抛出异常
int i = size;
if (i >= queue.length)
grow(i + 1);
//如果数组的大小不够扩充
size = i + 1;
if (i == 0)
queue[0] = e;
//如果只有一个元素之间放在堆顶
else
siftUp(i, e);
//否则调用siftUp函数从下往上调整堆。
return true;
}这两个方法都是向这个小堆里面添加一个元素,add()方法体内,也是调用的offer()啦。
public boolean add(E e) {
return offer(e);
}offer()的源码是这样的:
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
//如果压入的元素为null 抛出异常
int i = size;
if (i >= queue.length)
grow(i + 1);
//如果数组的大小不够扩充
size = i + 1;
if (i == 0)
queue[0] = e;
//如果只有一个元素之间放在堆顶
else
siftUp(i, e);
//否则调用siftUp函数从下往上调整堆。
return true;
}和我自己写得堆排序里面的,交换过程差不多。
1. 优先队列无法存放 null
2. 元素进堆之后,如果数组大小不够,进行扩充数组,
3. 从下往上,调整堆。siftUp(i,e)
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}就是一个不断比较交换的过程,不再赘述。
Poll() remove()
poll 方法每次从 PriorityQueue 的头部删除一个节点,也就是从小顶堆的堆顶删除一个节点,而remove()不仅可以删除头节点而且还可以用 remove(Object o) 来删除堆中的与给定对象相同的最先出现的对象。
poll() 方法就很好理解了,删除堆顶元素,然后再调整堆。
public E poll() {
if (size == 0)
return null;
//如果堆大小为0则返回null
int s = --size;
modCount++;
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
//如果堆中只有一个元素直接删除
if (s != 0)
siftDown(0, x);
//否则删除元素后对堆进行调整
return result;
}同理,siftDown()是从堆顶往下调整堆。
private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}大小变换
如果想利用 priorityQueue来构造最大堆的话,自己写一个Comparator传入构造函数就行了,具体的构造函数,前面已经说过了啊。
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}