最近才开始用汇编分析具体过程,之前的一些问题,只到达把参数存储到栈顶,准备调用函数之类的模糊认知,今天打算再细分析一下。
(不知道csdn还是猎豹浏览器烂,排版越搞越烂。)
首先是变量初始化:
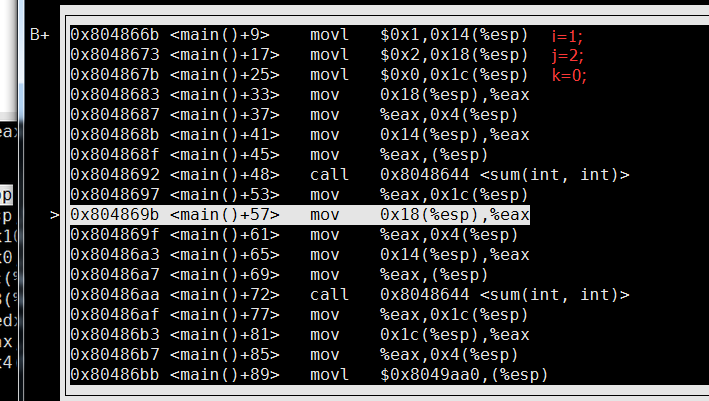
这里有一个问题,就是i,j,k在栈中顺序倒置了i最先,按理说是高地址(linux栈向下生长)
然后是两个参数入栈,这个顺序没得说,由右向左入,保证最左边的参数地址最低,在esp指向的内存。

参数入栈之后就是函数调用了,程序为了观察,重复调用了两次,调用就是call 函数入口地址,可以观察到,固定地址,两次都是
call 0x8048644<sum(int, int)>
(所以我的虚函数例子中,一个类的各个基类vptr,找到vtable再加偏转后,那个函数地址应该是固定的?!比如f::func()的入口地址?可以过去验证一下,给原文补充)
然后跳转到sum()函数内部了,这是函数代码段的首地址(可以这么理解吧,具体这个地址范围,是不是就是text segment,待验证。),和call指令给的地址一样。应该这样理解:所谓函数的入口地址,其实也就是push ebp压栈指令(因为在第一条)的地址。

(frame_dummy不知道干什么的。和哪段代码衔接。)
下边是sum()内部的指令:
x0x8048644 <sum(int, int)> push %ebp x
x0x8048645 <sum(int, int)+1> mov %esp,%ebp x
x0x8048647 <sum(int, int)+3> sub $0x10,%esp x
x0x804864a <sum(int, int)+6> movl $0x0,-0x4(%ebp) x
x0x8048651 <sum(int, int)+13> mov 0xc(%ebp),%eax x
x0x8048654 <sum(int, int)+16> mov 0x8(%ebp),%edx x
x0x8048657 <sum(int, int)+19> lea (%edx,%eax,1),%eax x
x0x804865a <sum(int, int)+22> mov %eax,-0x4(%ebp) x
0x804865d <sum(int, int)+25> mov -0x4(%ebp),%eax x
x0x8048660 <sum(int, int)+28> leave x
x0x8048661 <sum(int, int)+29> ret 关于调用函数:
call指令之前的esp和ebp,这也就是全局的栈帧一个初始化的状态:
(gdb) print $esp
$36 = (void *) 0xbffff5f0
(gdb) print $ebp
$37 = (void *) 0xbffff618
下边开始是<sum(int,int)>的指令:
call之后,push ebp之前,这时候esp等于已经自减4了。因为下边要用esp给ebp赋值,所以这等于找新栈帧的栈底的操作。
(gdb) print $esp
$42 = (void *) 0xbffff5ec
(gdb) print $ebp
$43 = (void *) 0xbffff618
push之后,esp继续自减4,ebp还是不变。push就是保存ebp的操作,下一步ebp的内容就被抹了。只不过,这个ebp是存哪去了呢?
(gdb) print $esp
$44 = (void *) 0xbffff5e8
(gdb) print $ebp
$45 = (void *) 0xbffff618此处esp为何还减4?总共减8了。这个-4应该是给return值预留的一个空间?可以看到,<sum(int,int)>里,$0x0是存到$ebp-4的地址了。对应代码是c = 0;c的地址就是$ebp-4,逆向增长,c(0xbffff5e4)在ebp与esp之间
mov %esp,%ebp 之后,ebp被同步,到这,就算是sum()函数的局部栈了?
(gdb) print $esp
$46 = (void *) 0xbffff5e8
(gdb) print $ebp
$47 = (void *) 0xbffff5e8
然后是esp的自减,之前一直疑惑的esp自减的问题,在比较特殊的程序起始部分main()那可能看不太好,在局部的sum()调用这就比较清晰了,
因为要把ebp指到esp处,也就是让老的栈顶成为新的栈底。此时,两个指针一样,想要栈空间,肯定要让esp再自减,开辟一部分内存出来。
另一个问题也说通了,函数的参数(无论值还是指针),并不属于当前栈帧,而是上层,在新的ebp之前的位置。
(gdb) print $esp
$48 = (void *) 0xbffff5d8
(gdb) print $ebp
$49 = (void *) 0xbffff5e8
总的内存分布和操作流程,上张图吧:

2、3、6分别代表esp的变更后的新指向。
不管lea和寄存器的细节了,总之,是把a+b的值写到c。
最后把临时变量c的内容3写到了eax寄存器,准备leave
0x804865d <sum(int, int)+25> mov -0x4(%ebp),%eax
实测,当栈帧从局部函数sum()回到main()下时,eax寄存器的内容不变,也就是说可以用寄存器返回值。至少technically是这样的,具体它是不是这么用的不知道。
仔细看函数调用返回后的代码,证明是这样用的!!!!!
k = sum(i,j); x0x804869a <main()+56> call 0x8048644 <sum(int, int)> x
x0x804869f <main()+61> mov %eax,0x1c(%esp) x
>x0x80486a3 <main()+65> mov 0x18(%esp),%eax 所以,函数返回值是借助eax寄存器传递的!!!!
函数sum()结尾返回部分:
leave指令执行前的esp和ebp
(gdb) si
(gdb) print $esp
$9 = (void *) 0xbffff5d8
(gdb) print $ebp
$10 = (void *) 0xbffff5e8
leave指令执行后的esp和ebp,都发生了变化,ebp的0xbffff618已经是main的栈底了。esp的0xbffff5ec是之前入栈预留出来的空间,至少不是返回值,不明白。
(gdb) print $esp
$11 = (void *) 0xbffff5ec
(gdb) print $ebp
$12 = (void *) 0xbffff618
ret指令执行后的esp和ebp,ebp不变,esp+4,恢复到main时的原始状态,返回值是借助eax,所以这不可能是返回值了!
(gdb) print $esp
$13 = (void *) 0xbffff5f0
(gdb) print $ebp
$14 = (void *) 0xbffff618
全程打印,局部栈底ebp地址0xbffff5e8数值未改变,应该是没用上。
比局部栈底高四字节的0xbffff5ec指向的地址(假设是个有意义的地址,十六进制转换)134514359-》0x80486b7有变化,但是不知道是不是有意义的东西。
总之,上图空出来的两个地方的功能不太能解释。
再去查一下leave和ret的汇编指令。
=========================================================================================================================
还有,return值存哪?
还有个问题,进入局部栈帧,ebp增长,老的ebp存在哪了?(和之前空出来的八个地址有关?)不存起来肯定是恢复不回去的?但是具体存哪了呢?
找来一个参考图,解释了这八个地址的作用,就是汇编代码中没有显式的用法:
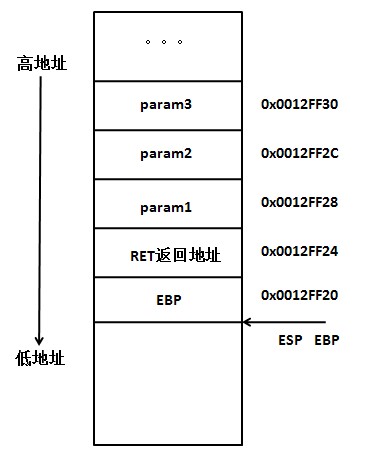
根据此图,结合本案例
第一句,call造成的esp减4,是预留返回地址。
第二句,push ebp是给老ebp留位置。
都是4地址,因为是32位,一个指针都是4bytes。
call指令之前,esp固定,内容为地址:0xbffff5f0,存放入栈参数i=1;
call指令之后,esp减4(图中就是指向RET返回地址)内容为地址0xbffff5ec,该地址存放:0x804869f,其实就是从sum()函数执行结束后的下一条指令的地址。
x0x804869a <main()+56> call 0x8048644 <sum(int, int)> x
x0x804869f <main()+61> mov %eax,0x1c(%esp)
push指令之后,esp减4,内容为地址0xbffff5e8,该地址存放:-1073744360,即0xBFFFF618,果然是main()函数的基ebp。
执行leave前,寄存器%ebp存储局部栈底0xbffff5e8。
执行leave的时候,寄存器%ebp恢复到老的ebp地址0xbffff618。(这是入栈时候存好的)
执行ret前,寄存器%esp存储局部栈顶0xbffff5ec。
执行ret后,寄存器%esp恢复到老的esp地址0xbffff5f0。(不同于ebp,不知道谁给的)
参考指令介绍:
RET ; (10)当前堆栈指针减2,返回到(3)CLR P1.0继续执行MAIN 主程序。
此处,不是减2是减4.但是果然,新老esp才相差0x4,不是两次减0x4,又一次自减0x10么,总工需要0x18!
其实%esp也是两次变更,
在LEAVE操作有一次变更,从0xbffff5d8到0xbffff5ec。指向RET地址了。esp指向的RET比局部EBP高四个地址(一个指针大小),LEAVE的含义可能就在于此吧,已经离开了那个栈帧。
在RET操作还有一次,从0xbffff5ec到0xbffff5f0。这时候程序也跳到RET指定的地址继续执行了。。。。
不过这么说来,RET算三不管么?也就是个临时的,不能称作变量的东西,跳转地址而已。比main()栈帧的esp还低,比sum()栈帧的ebp还高。
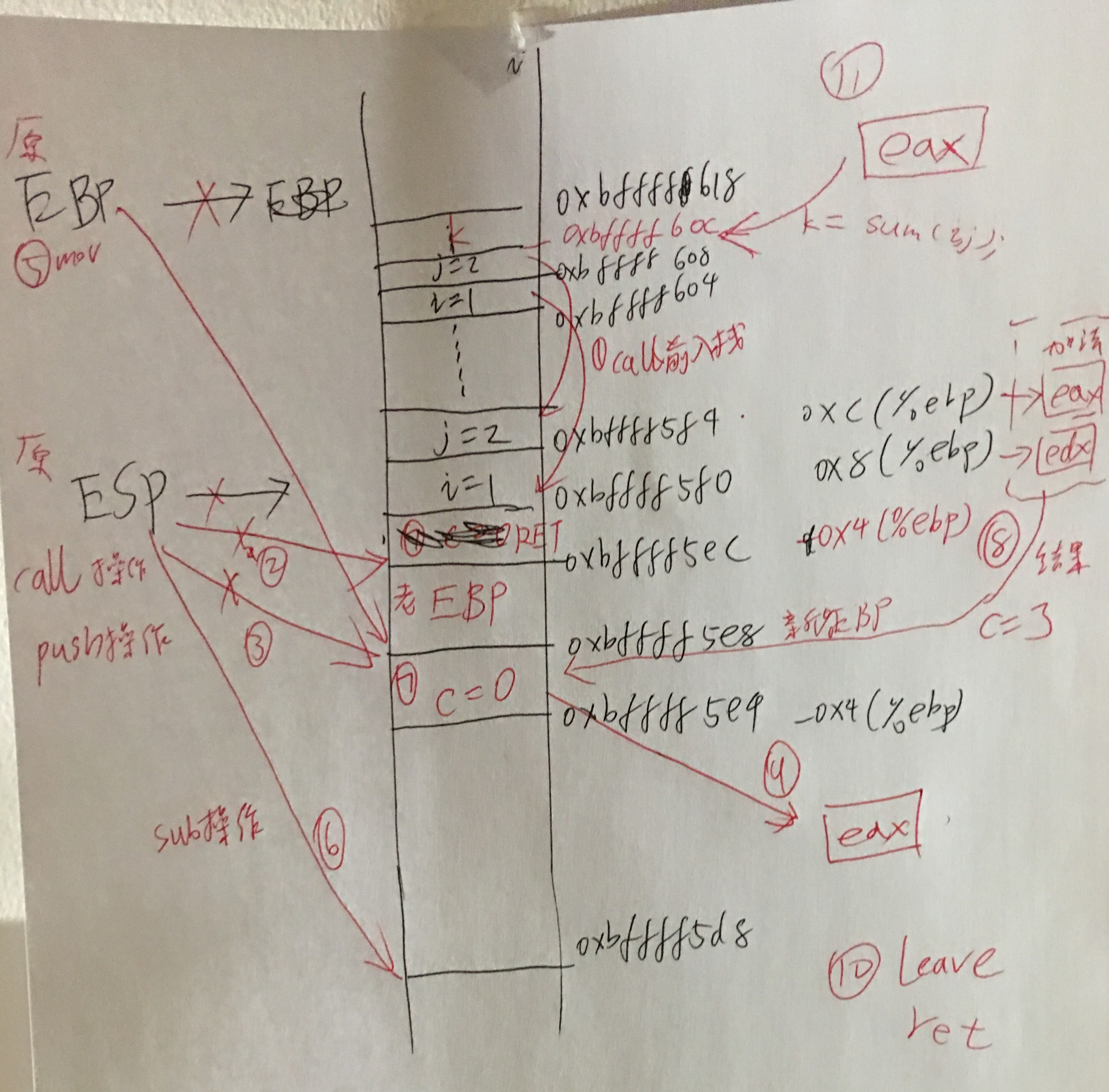
最终堆栈调用过程的内存分布:
==================================================================================================================================================================================================================================================
今天补充讨论新问题:不同类型的返回怎么实现!
之前基于eax返回函数返回值,就一直在想,为何不能用多个寄存器返回多个值?
一方面,有些语言确实这样做了,C/C++不做,也许因为语法不方便,毕竟语言很多地方其实是为程序员考虑的,比如左值右值的问题(好像没什么问题,应该是右值);还有,返回类型代表了函数类型,返回多个值的话函数类型怎么算?
另一方面,就可能是效率!效率,wait!忽略了一个重点,那些个很复杂的东西,它用寄存器返回不了的啊,寄存器就那么大,寄存器效率最高,其实不用寄存器的都有效率问题,区别只是怎么优化这个过程,怎么实现的区别吧!
说到返回多个值呢,大家最常想到的,应该是打包结构体,用容器什么的,或者预先传个结构体指针进去。
那么具体的实现是什么呢?先以结构体为例:
#include<stdio.h>
typedef struct S{
public:
int i;
int j;
}structS;
structS getStruct()
{
structS s1;
s1.i = 1;
s1.j = 2;
return s1;
}
int main()
{
//structS test = getStruct();//怕算作一种构造,干扰
structS test;
test = getStruct();
printf("i:%d\n",test.i);
printf("j:%d\n",test.j);
}
第一种:
structS test = getStruct();
汇编过程:开辟了一块空间,并把地址传给主栈帧顶端esp,函数局部就直接在原结构体对象身上开刀了,断点的话,函数没返回时,原结构体内容已经被改了。
第二种:
structS test;
test = getStruct();
首先,给test对象开辟了空间,在main()函数栈帧内。然后,把对象地址放到了栈顶esp处。
>x0x8048467 <getStruct()+3> mov 0x8(%ebp),%eax x
x0x804846a <getStruct()+6> movl $0x1,(%eax) x
x0x8048470 <getStruct()+12> movl $0x2,0x4(%eax)
函数内部,取出该对象地址到寄存器(体现一个快),然后把i和j的值存入指定地址。本质上,等于一个INOUT的structS*参数传入。
两种一模一样,没区别,本质都是传地址,没走返回值机制,没用eax,等于走了入参机制,并且函数内部的结构体声明与定义也没有占用函数栈帧。这是隐藏传入指针参数!不知道怎么解释这种事情了。编译器优化吧!!!!
下面改下代码,做个对比:
#include<stdio.h>
typedef struct S{
public:
int i;
int j;
}structS;
structS getStruct()
{
structS s1;
s1.i = 1;
s1.j = 2;
return s1;
}
void setStruct(structS *s1)
{
s1->i = 1;
s1->j = 2;
return;
}
int main()
{
structS test;//怕算作一种构造,干扰
setStruct(&test);//怕算作一种构造,干扰
// test = getStruct();
printf("i:%d\n",test.i);
printf("j:%d\n",test.j);
}过程几乎一模一样,唯一的一点小区别,也是非常费解的区别,两次操作使用的eax寄存器内容明明一样,可以省去第二次0x8(%ebp),%eax的,之前的那种做法就省去了。所以,也可能是语句不同,编译器优化不一样了?

现在,关于函数返回值结构体的实现机制就清晰了。
更多其他类型的话:
char也是用eax返回
double就不一样了。
x0x8048474 <getValue()> push %ebp x
x0x8048475 <getValue()+1> mov %esp,%ebp x
x0x8048477 <getValue()+3> sub $0x10,%esp x
x0x804847a <getValue()+6> fldl -0x8(%ebp) x
x0x804847d <getValue()+9> leave x
>x0x804847e <getValue()+10> ret 没有显式的寄存器保存,内存也是ebp负向偏移,局部的。
long long,32位下,寄存器只有32位,一个long long是用两个寄存器eax和edx一起返回的。
函数内
x0x804849c <getLongLong()+20> mov -0x8(%ebp),%eax x
x0x804849f <getLongLong()+23> mov -0x4(%ebp),%edx x
>x0x80484bb <main()+23> mov %eax,0x18(%esp) x
x0x80484bf <main()+27> mov %edx,0x1c(%esp) x
向下兼容,char和short都像int一样,用一个eax寄存器存储返回值。
总之,基本上就两种返回方法,压栈传参传地址法和寄存器暂存返回法。最终保证局部栈帧结束后,变量能够保存下来。
=========================================================================================================================
补充(20160315):有了上边的基础,来看一个破坏性试验:
两层函数func1()和sum()。在sum函数内部强行更改压栈的ebp地址(c地址+8偏移所储存内容即是)
#include<iostream>
using namespace std;
int sum(int a,int b){
int c = 0;
c = a + b;
int *p = &c;
p++;
p++;
*p = *p - 0x10;
return c;
}
int func1(int a, int b)
{
int c = sum(a,b);
return c;
}
int main(){
int iiiii = 0;
int i = 1;
int j = 2;
int k = 0;
k = func1(i,j);
// k = sum(i,j);
cout << k << endl;
cout << i << endl;
cout << j << endl;
return 0;
}流程分析:
初始ebp 0xbffff618,
变量iiiii地址0xbffff600,i地址604j地址608
调用func1(),压栈后,当前ebp 0xbffff5e8(内容0xbffff618),
调用sum(),再次压栈,当前ebp 0xbffff5c8(内容0xbffff5e8),
在sum()函数体内指针p强指向ebp0xbffff5c8指向的内容0xbffff5e8,-0x10,即为0xbffff5d8,
从sum()返回,出栈后ebp破坏,返回值需要靠ebp 的值来找,原来的0xbffff5e8 - 0x4变成了0xbffff5d8 - 0x4 == 0xbffff5d4,返回值存储到了错误的位置。
从func1()返回,k没有得到应有的返回值,仍然为野值:
(gdb) print $ebp
$19 = (void *) 0xbffff5d8
(gdb) print *(0xbffff5d4)
$20 = 3
(gdb) print &k
$22 = (int *) 0xbffff60c
更远的后果,其实没有,因为返回靠的是ret地址,改ebp只改一层,也就是从sum()函数改乱了func1()函数的栈帧基址,回到main()函数就一切正常了。
所以此例的影响主要就是值返回失败。
重新理一下位置关系:ebp寄存器的地址指向老ebp压栈的位置,地址+4为ret地址,地址-4为局部变量c地址,因为语句是return c;所以需要c存储值。
万恶的指针!!!!嘿嘿!
指针不封装,不封装就有权限可以乱改,可一旦改错,后果也是要多严重有多严重。
PS:改了return地址就真的乱了,不过下边也可以试试,应该还可以达成另类goto语句,自己实现循环之类的。
=========================================================================================================================
下边写个例子:
#include<iostream>
using namespace std;
int func1(int a, int b)
{
int c = a + b;
int *p = &c;
p++;
p++;
p++;
*p = *p - 0x19;
return c;
}
int main(){
int iiiii = 0;
int i = 1;
int j = 2;
int k = 0;
i++;
k = func1(i,j);
cout << k << endl;
cout << i << endl;
cout << j << endl;
return 0;
}
死循环!!
自减0x19是把func1()的ret地址从本该返回的位置改成i++的位置,这样每次出来跳转到i++
但是这个死循环的前提是“干净”!!如果中间有系统调用如cout和printf()之类的,则不能达成,例如这种:
i++;
cout << "i:"<< i << endl;
k = func1(i,j);
int func1(int a, int b)
{
cout << "a:"<< a << endl;
int c = a + b;
因为又有函数跳转了嘛。各种错误吧,可能结束,甚至可能core dumped。还有就是语句多了以后,语句差值也不同了, 减法的数值是要根据情况改的!
加上打印,算好合适的跳转距离,重新设计:
#include<iostream>
using namespace std;
int func1(int a, int b)
{
int c = a + b;
int *p = &c;
p++;
p++;
p++;
*p = *p - 0x4d;
return c;
}
int main(){
int iiiii = 0;
int i = 1;
int j = 2;
int k = 0;
i++;
cout << "i:"<< i << endl;
k = func1(i,j);
cout << k << endl;
cout << i << endl;
cout << j << endl;
return 0;
}
这就是我想要的效果
运行结果:

最后,如果你不知道这个跳转值怎么来的,复制我上边的例子,打开
#gdb target
打开目标可执行文件
(gdb)b 15
打个断点
(gdb)run
运行一下卡住,然后layout asm看就行了。

0x750-0x703等于0x4d。
=========================================================================================================================
下边是之前思考顺带留下的疑问:不影响分析入栈出栈过程,博主有空再来巩固,现在不能分心搞这种“副业”。
附1:好吧,这是个强迫症问题,不影响学习机理,看别的够用了,先挂起了。。。。
网友推荐参考书籍(不确定有答案):《老码仕途》 《代码揭秘》
sum()起始部分这些东西和main开始有些相似,都是push ebp,但又不太一样
main()的初始化:
x0x8048662 <main()> push %ebp x
x0x8048663 <main()+1> mov %esp,%ebp x
x0x8048665 <main()+3> and $0xfffffff0,%esp x
x0x8048668 <main()+6> sub $0x20,%esp 疑问,这个0xfffffff0赋值给esp之后ebp就没有操作了,另外,那个也不是赋值,是一个与操作。就是esp和ebp本来一样,进行一个与操作,等于像页(块)一样的取个整?
这样之后还要再减那么多是什么意思?取整的过程中esp会和ebp产生怎样的差别?
main()的压栈和sum()的压栈到底有何不同?因为sum()的压栈只是一个小迁移,而main()的压栈是整个程序的栈的开辟过程?按现在的理解是这样。
假设,在进main之前有个特殊的esp地址,因为是编译过程产生的逻辑地址,所以按理说是多少都可以,这个没有一个规则固定产生么?
总之,在一个选定的esp地址下,先把esp同步到ebp,此时两个指针指向一样的地址,做完与操作之后,等于esp会清空了16个以内的地址(32位,一个十六进制数归0),然后自减一个合适的栈空间大小。最大的疑惑就在这,假如说这一过程还倒退了怎么办?为何一定要这样操作,为了地址达到某种对齐?固然,减去0x20一定能够弥补0xfffffff0与操作,但是不是比较浪费么,就是说只需要0x10个地址存数据,却需要进行一个-0x20操作。
不是这个意思,理解反了,因为是逆向增长,一位清零也是在增加空间,自减20也是在增加空间。所以实际是让esp比ebp多了20多个地址。
(但是一定这么巧,ebp都是8字底?试了好几次编译。)
(gdb) print $esp
$1 = (void *) 0xbffff5f0
(gdb) print $ebp
$2 = (void *) 0xbffff618$3 = (void *) 0xbffff5e8
(gdb) print $ebp
$4 = (void *) 0xbffff5e8
=========================================================================================================================
=========================================================================================================================
附2:下面的东西说不太通,先存起来。
ip寄存器(32位eip),ip寄存器的内容很多时候(还是永久?)是和pc寄存器内容一样的!是下一条指令的地址。
按理说是pc存的是下一条指令的地址,ip是从内存中找到的当前指令的内容,不知道为什么两者相同。可能单步调试刚好卡在某个节点上?但是为何相等。
组成原理课本是说的两种东西,
但网友说“pc就是ip,cs存放段基址,ip存放偏移量,没有单独的pc的说法。”
也有网友说有单独的pc的。
gdb也给出了$pc和$eip两种访问方法。

(图中没打印pc寄存器,但值是和eip一样的)
(gdb) print $eip
$32 = (void (*)(void)) 0x8048644 <sum(int, int)>
(gdb) print $pc
$33 = (void (*)(void)) 0x8048644 <sum(int, int)>
(gdb) si
(gdb) print $pc
$34 = (void (*)(void)) 0x8048645 <sum(int, int)+1>
(gdb) print $eip
$35 = (void (*)(void)) 0x8048645 <sum(int, int)+1>
=========================================================================================================================
下边是之前思考顺带留下的疑问:不影响分析入栈出栈过程,博主有空再来巩固,现在不能分心搞这种“副业”。
=========================================================================================================================
附1:细心可观察内存分布
最高的是栈,从高往低增长(linux)
然后是静态区,存一些全局变量
最下边是只读区,尤以代码地址最低,其次是一些常量字符串“xxxxxx”之类的。
附2:好吧,这是个强迫症问题,不影响学习机理,看别的够用了,先挂起了。。。。
网友推荐参考书籍(不确定有答案):《老码仕途》 《代码揭秘》
sum()起始部分这些东西和main开始有些相似,都是push ebp,但又不太一样
main()的初始化:
x0x8048662 <main()> push %ebp x
x0x8048663 <main()+1> mov %esp,%ebp x
x0x8048665 <main()+3> and $0xfffffff0,%esp x
x0x8048668 <main()+6> sub $0x20,%esp 疑问,这个0xfffffff0赋值给esp之后ebp就没有操作了,另外,那个也不是赋值,是一个与操作。就是esp和ebp本来一样,进行一个与操作,等于像页(块)一样的取个整?
这样之后还要再减那么多是什么意思?取整的过程中esp会和ebp产生怎样的差别?
main()的压栈和sum()的压栈到底有何不同?因为sum()的压栈只是一个小迁移,而main()的压栈是整个程序的栈的开辟过程?按现在的理解是这样。
假设,在进main之前有个特殊的esp地址,因为是编译过程产生的逻辑地址,所以按理说是多少都可以,这个没有一个规则固定产生么?
总之,在一个选定的esp地址下,先把esp同步到ebp,此时两个指针指向一样的地址,做完与操作之后,等于esp会清空了16个以内的地址(32位,一个十六进制数归0),然后自减一个合适的栈空间大小。最大的疑惑就在这,假如说这一过程还倒退了怎么办?为何一定要这样操作,为了地址达到某种对齐?固然,减去0x20一定能够弥补0xfffffff0与操作,但是不是比较浪费么,就是说只需要0x10个地址存数据,却需要进行一个-0x20操作。
不是这个意思,理解反了,因为是逆向增长,一位清零也是在增加空间,自减20也是在增加空间。所以实际是让esp比ebp多了20多个地址。
(但是一定这么巧,ebp都是8字底?试了好几次编译。)
(gdb) print $esp
$1 = (void *) 0xbffff5f0
(gdb) print $ebp
$2 = (void *) 0xbffff618$3 = (void *) 0xbffff5e8
(gdb) print $ebp
$4 = (void *) 0xbffff5e8
=========================================================================================================================
=========================================================================================================================
附3:下面的东西说不太通,先存起来。
ip寄存器(32位eip),ip寄存器的内容很多时候(还是永久?)是和pc寄存器内容一样的!是下一条指令的地址。
按理说是pc存的是下一条指令的地址,ip是从内存中找到的当前指令的内容,不知道为什么两者相同。可能单步调试刚好卡在某个节点上?但是为何相等。
组成原理课本是说的两种东西,
但网友说“pc就是ip,cs存放段基址,ip存放偏移量,没有单独的pc的说法。”
也有网友说有单独的pc的。
gdb也给出了$pc和$eip两种访问方法。
(图中没打印pc寄存器,但值是和eip一样的)
(gdb) print $eip
$32 = (void (*)(void)) 0x8048644 <sum(int, int)>
(gdb) print $pc
$33 = (void (*)(void)) 0x8048644 <sum(int, int)>
(gdb) si
(gdb) print $pc
$34 = (void (*)(void)) 0x8048645 <sum(int, int)+1>
(gdb) print $eip
$35 = (void (*)(void)) 0x8048645 <sum(int, int)+1>