matplotlib —— 课后练✋
%matplotlib inline
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
练习1:航班乘客变化分析
- 分析年度乘客总量变化情况(折线图)
- 分析乘客在一年中各月份的分布(柱状图)
data = sns.load_dataset("flights")
data.head()
|
year |
month |
passengers |
| 0 |
1949 |
January |
112 |
| 1 |
1949 |
February |
118 |
| 2 |
1949 |
March |
132 |
| 3 |
1949 |
April |
129 |
| 4 |
1949 |
May |
121 |
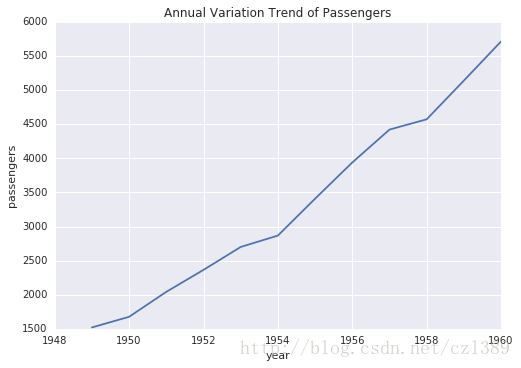
年度变化
year_group=data.groupby('year').sum()
fig,ax=plt.subplots()
ax.plot(year_group.index,year_group['passengers'])
ax.set_xlabel('year')
ax.set_ylabel('passengers')
ax.set_title('Annual Variation Trend of Passengers')
<matplotlib.text.Text at 0x7f89cacfaf50>
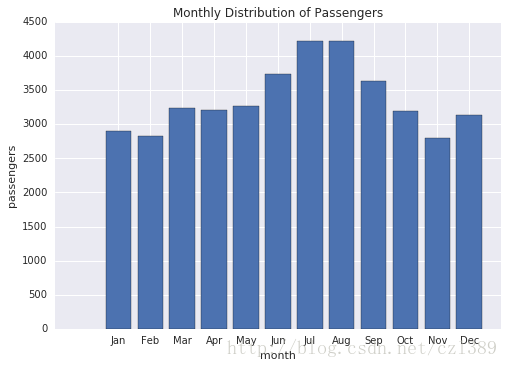
各月份之间的差异
data_1949=data[data['year']==1949]
month_group=data.groupby('month').sum()
month_group['month_num']=range(12)
fig1,ax1=plt.subplots()
ax1.bar(month_group['month_num'],month_group['passengers'],align='center')
ax1.set_xlabel('month')
ax1.set_ylabel('passengers')
ax1.set_xticks(range(12))
month_names=[str[:3] for str in list(month_group.index)]
ax1.set_xticklabels(month_names)
ax1.set_title('Monthly Distribution of Passengers')
<matplotlib.text.Text at 0x7f89cabdad10>
练习2:鸢尾花花型尺寸分析
- 萼片(sepal)和花瓣(petal)的大小关系(散点图)
- 不同种类(species)鸢尾花萼片和花瓣的大小关系(分类散点子图)
- 不同种类鸢尾花萼片和花瓣大小的分布情况(柱状图或者箱式图)
data = sns.load_dataset("iris")
data.head()
|
sepal_length |
sepal_width |
petal_length |
petal_width |
species |
| 0 |
5.1 |
3.5 |
1.4 |
0.2 |
setosa |
| 1 |
4.9 |
3.0 |
1.4 |
0.2 |
setosa |
| 2 |
4.7 |
3.2 |
1.3 |
0.2 |
setosa |
| 3 |
4.6 |
3.1 |
1.5 |
0.2 |
setosa |
| 4 |
5.0 |
3.6 |
1.4 |
0.2 |
setosa |
data['sepal_size']=data['sepal_length']*data['sepal_width']
data['petal_size']=data['petal_length']*data['petal_width']
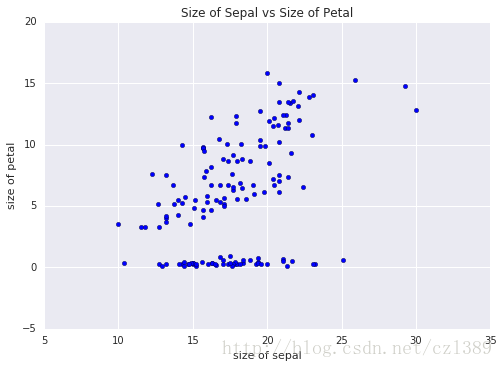
花瓣与萼片的关系
fig, ax2_1 = plt.subplots()
ax2_1.scatter(data['sepal_size'],data['petal_size'])
ax2_1.set_title('Size of Sepal vs Size of Petal')
ax2_1.set_xlabel('size of sepal')
ax2_1.set_ylabel('size of petal')
<matplotlib.text.Text at 0x7f89caa496d0>
species=data['species'].unique()
species
array([‘setosa’, ‘versicolor’, ‘virginica’], dtype=object)
data1=data[data['species']==species[0]]
data2=data[data['species']==species[1]]
data3=data[data['species']==species[2]]
不同种类之间萼片与花瓣的关系
fig, ax2_2 = plt.subplots()
ax2_2.scatter(data1['sepal_size'],data1['petal_size'],color = '#ff0000',label=species[0])
ax2_2.scatter(data2['sepal_size'],data2['petal_size'],color = '#00ff00',label =species[1])
ax2_2.scatter(data3['sepal_size'],data3['petal_size'],color = '#0000ff',label=species[2])
ax2_2.legend(loc = 'best')
ax2_2.set_title('Size of Sepal vs Size of Petal')
ax2_2.set_xlabel('size of sepal')
ax2_2.set_ylabel('size of petal')
<matplotlib.text.Text at 0x7f89ca98b990>
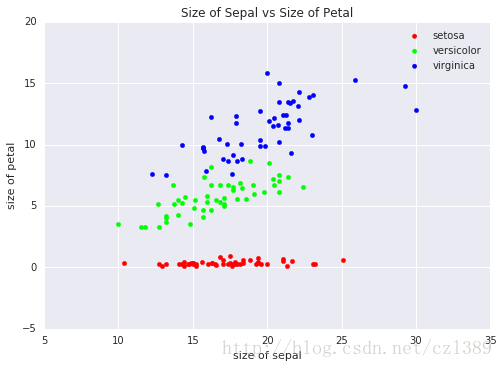
不同种类的花瓣与萼片大小
def boxplot(x_data, y_data, base_color, median_color, x_label, y_label, title):
_, ax = plt.subplots()
ax.boxplot(y_data
, patch_artist = True
, medianprops = {'color': base_color}
, boxprops = {'color': base_color, 'facecolor': median_color}
, whiskerprops = {'color': median_color}
, capprops = {'color': base_color})
ax.set_xticklabels(x_data)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
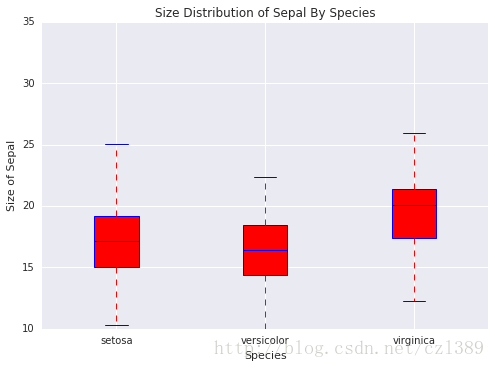
bp_data=[data1['sepal_size'],data2['sepal_size'],data3['sepal_size']]
boxplot(x_data = species
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Species'
, y_label = 'Size of Sepal'
, title = 'Size Distribution of Sepal By Species')
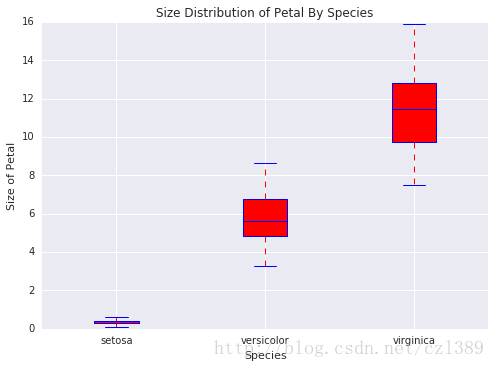
bp_data=[data1['petal_size'],data2['petal_size'],data3['petal_size']]
boxplot(x_data = species
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Species'
, y_label = 'Size of Petal'
, title = 'Size Distribution of Petal By Species')
练习3:餐厅小费情况分析
- 小费和总消费之间的关系(散点图)
- 男性顾客和女性顾客,谁更慷慨(分类箱式图)
- 抽烟与否是否会对小费金额产生影响(分类箱式图)
- 工作日和周末,什么时候顾客给的小费更慷慨(分类箱式图)
- 午饭和晚饭,哪一顿顾客更愿意给小费(分类箱式图)
- 就餐人数是否会对慷慨度产生影响(分类箱式图)
- 性别+抽烟的组合因素对慷慨度的影响(分组柱状图)
data = sns.load_dataset("tips")
data.head()
|
total_bill |
tip |
sex |
smoker |
day |
time |
size |
| 0 |
16.99 |
1.01 |
Female |
No |
Sun |
Dinner |
2 |
| 1 |
10.34 |
1.66 |
Male |
No |
Sun |
Dinner |
3 |
| 2 |
21.01 |
3.50 |
Male |
No |
Sun |
Dinner |
3 |
| 3 |
23.68 |
3.31 |
Male |
No |
Sun |
Dinner |
2 |
| 4 |
24.59 |
3.61 |
Female |
No |
Sun |
Dinner |
4 |
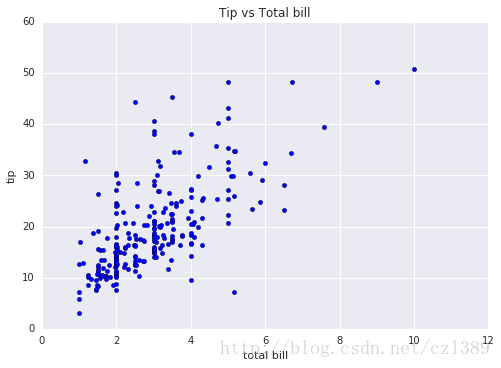
小费与总消费的关系
_, ax3_1 = plt.subplots()
ax3_1.scatter(data['tip'],data['total_bill'])
ax3_1.set_title('Tip vs Total bill')
ax3_1.set_xlabel('total bill')
ax3_1.set_ylabel('tip')
<matplotlib.text.Text at 0x7f89ca689150>
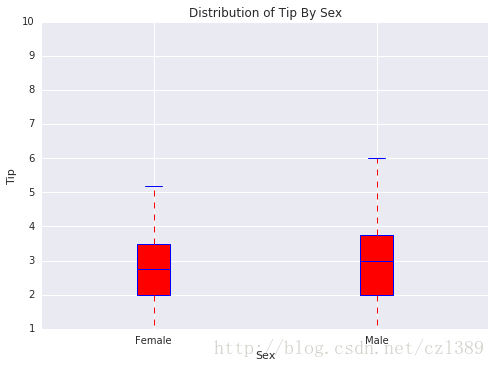
男性与女性
sex=data['sex'].unique()
bp_data=[data[data['sex']==sex[0]]['tip'],data[data['sex']==sex[1]]['tip']]
boxplot(x_data = sex
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Sex'
, y_label = 'Tip'
, title = 'Distribution of Tip By Sex')
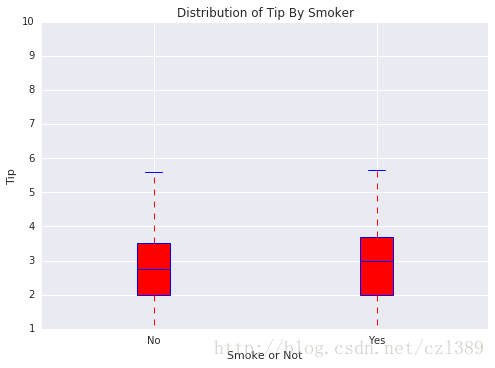
抽烟与否
smoker=data['smoker'].unique()
bp_data=[data[data['smoker']==smoker[0]]['tip'],data[data['smoker']==smoker[1]]['tip']]
boxplot(x_data = smoker
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Smoke or Not'
, y_label = 'Tip'
, title = 'Distribution of Tip By Smoker')
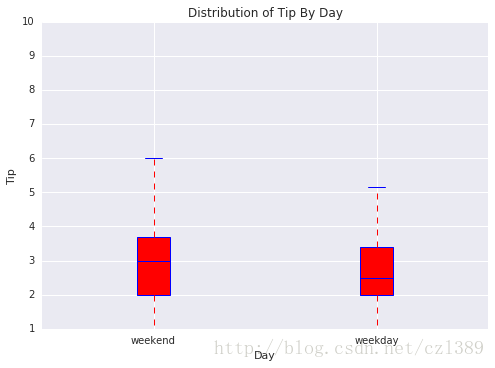
工作日与周末
day=data['day'].unique()
bp_data=[data[data['day'].isin(day[:2])]['tip'],data[data['day'].isin(day[2:4])]['tip']]
boxplot(x_data = ['weekend','weekday']
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Day'
, y_label = 'Tip'
, title = 'Distribution of Tip By Day')
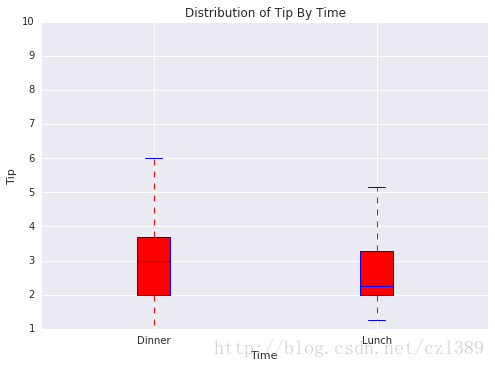
午餐与晚餐
time=data['time'].unique()
bp_data=[data[data['time']==time[0]]['tip'],data[data['time']==time[1]]['tip']]
boxplot(x_data = time
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Time'
, y_label = 'Tip'
, title = 'Distribution of Tip By Time')
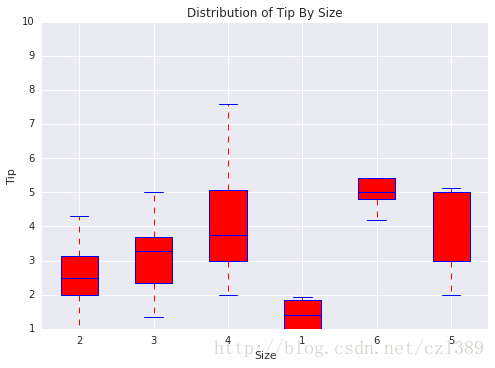
就餐人数
size=data['size'].unique()
bp_data=[]
for i in range(len(size)):
bp_data.append(data[data['size']==size[i]]['tip'])
boxplot(x_data = size
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Size'
, y_label = 'Tip'
, title = 'Distribution of Tip By Size')
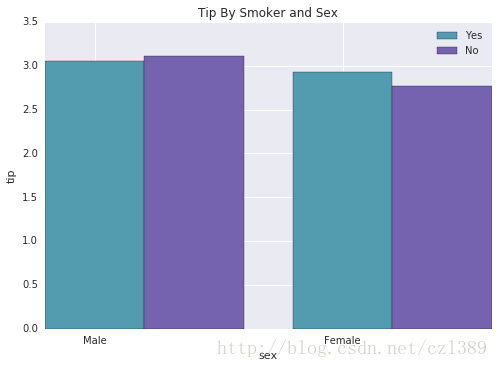
性别+抽烟
tip_by_sex_smoke=data.groupby(['sex','smoker']).mean()['tip']
tip_by_sex_smoke=tip_by_sex_smoke.unstack()
tip_by_sex_smoke
| smoker |
Yes |
No |
| sex |
|
|
| Male |
3.051167 |
3.113402 |
| Female |
2.931515 |
2.773519 |
def groupedbarplot(x_data, y_data_list, y_data_names, colors, x_label, y_label,title):
_, ax = plt.subplots()
total_width = 0.8
ind_width = total_width / len(y_data_list)
alteration = np.arange(-total_width/2+ind_width/2, total_width/2+ind_width/2, ind_width)
for i in range(0, len(y_data_list)):
ax.bar(x_data + alteration[i], y_data_list[i], color = colors[i], label = y_data_names[i], width = ind_width)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = 'upper right')
groupedbarplot(x_data = range(2)
, y_data_list = [tip_by_sex_smoke['Yes'],tip_by_sex_smoke['No']]
, y_data_names = ['Yes', 'No']
, colors = ['#539caf', '#7663b0']
, x_label = 'sex'
, y_label = 'tip'
,title = 'Tip By Smoker and Sex')
ax=plt.gca()
ax.set_xticks(range(2))
ax.set_xticklabels(tip_by_sex_smoke.index.values)
[<matplotlib.text.Text at 0x7f89ca39cdd0>,
<matplotlib.text.Text at 0x7f89ca3a7e90>]
练习4:泰坦尼克号海难幸存状况分析
- 不同仓位等级中幸存和遇难的乘客比例(堆积柱状图)
- 不同性别的幸存比例(堆积柱状图)
- 幸存和遇难乘客的票价分布(分类箱式图)
- 幸存和遇难乘客的年龄分布(分类箱式图)
- 不同上船港口的乘客仓位等级分布(分组柱状图)
- 幸存和遇难乘客堂兄弟姐妹的数量分布(分类箱式图)
- 幸存和遇难乘客父母子女的数量分布(分类箱式图)
- 单独乘船与否和幸存之间有没有联系(堆积柱状图或者分组柱状图)
data = sns.load_dataset("titanic")
data.head()
|
survived |
pclass |
sex |
age |
sibsp |
parch |
fare |
embarked |
class |
who |
adult_male |
deck |
embark_town |
alive |
alone |
| 0 |
0 |
3 |
male |
22.0 |
1 |
0 |
7.2500 |
S |
Third |
man |
True |
NaN |
Southampton |
no |
False |
| 1 |
1 |
1 |
female |
38.0 |
1 |
0 |
71.2833 |
C |
First |
woman |
False |
C |
Cherbourg |
yes |
False |
| 2 |
1 |
3 |
female |
26.0 |
0 |
0 |
7.9250 |
S |
Third |
woman |
False |
NaN |
Southampton |
yes |
True |
| 3 |
1 |
1 |
female |
35.0 |
1 |
0 |
53.1000 |
S |
First |
woman |
False |
C |
Southampton |
yes |
False |
| 4 |
0 |
3 |
male |
35.0 |
0 |
0 |
8.0500 |
S |
Third |
man |
True |
NaN |
Southampton |
no |
True |
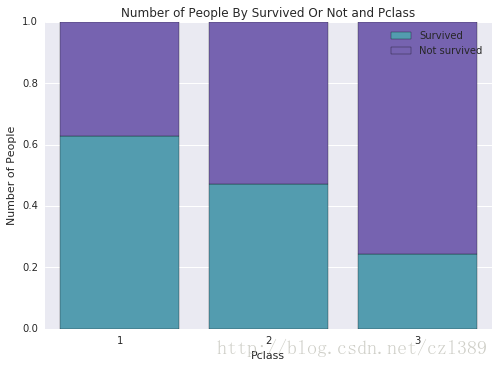
不同仓位等级幸存比例
def stackedbarplot(x_data, y_data_list, y_data_names, colors, x_label, y_label, title):
_, ax = plt.subplots()
for i in range(0, len(y_data_list)):
if i == 0:
ax.bar(x_data, y_data_list[i], color = colors[i], align = 'center', label = y_data_names[i])
else:
ax.bar(x_data, y_data_list[i], color = colors[i], bottom = y_data_list[i - 1], align = 'center', label = y_data_names[i])
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = 'upper right')
pclass_survived=data.groupby(['pclass','survived']).size().unstack()
pclass_survived
| survived |
0 |
1 |
| pclass |
|
|
| 1 |
80 |
136 |
| 2 |
97 |
87 |
| 3 |
372 |
119 |
pclass_survived['sum']=pclass_survived[0]+pclass_survived[1]
pclass_survived['yes_prop']=pclass_survived[1]/pclass_survived['sum']
pclass_survived['no_prop']=pclass_survived[0]/pclass_survived['sum']
pclass_survived
| survived |
0 |
1 |
sum |
yes_prop |
no_prop |
| pclass |
|
|
|
|
|
| 1 |
80 |
136 |
216 |
0.629630 |
0.370370 |
| 2 |
97 |
87 |
184 |
0.472826 |
0.527174 |
| 3 |
372 |
119 |
491 |
0.242363 |
0.757637 |
stackedbarplot(x_data = pclass_survived.index.values
, y_data_list = [pclass_survived['yes_prop'], pclass_survived['no_prop']]
, y_data_names = ['Survived', 'Not survived']
, colors = ['#539caf', '#7663b0']
, x_label = 'Pclass'
, y_label = 'Number of People'
, title = 'Number of People By Survived Or Not and Pclass')
ax=plt.gca()
ax.set_xticks(range(1,4))
ax.set_xticklabels(pclass_survived.index.values)
[<matplotlib.text.Text at 0x7f89ca2f1890>,
<matplotlib.text.Text at 0x7f89ca27a410>,
<matplotlib.text.Text at 0x7f89ca26d6d0>]
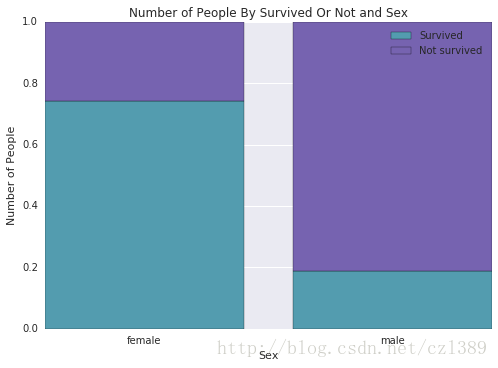
不同性别幸存比例
sex_survived=data.groupby(['sex','survived']).size().unstack()
sex_survived
| survived |
0 |
1 |
| sex |
|
|
| female |
81 |
233 |
| male |
468 |
109 |
sex_survived['sum']=sex_survived[0]+sex_survived[1]
sex_survived['yes_prop']=sex_survived[1]/sex_survived['sum']
sex_survived['no_prop']=sex_survived[0]/sex_survived['sum']
sex_survived
| survived |
0 |
1 |
sum |
yes_prop |
no_prop |
| sex |
|
|
|
|
|
| female |
81 |
233 |
314 |
0.742038 |
0.257962 |
| male |
468 |
109 |
577 |
0.188908 |
0.811092 |
stackedbarplot(x_data = [0,1]
, y_data_list = [sex_survived['yes_prop'], sex_survived['no_prop']]
, y_data_names = ['Survived', 'Not survived']
, colors = ['#539caf', '#7663b0']
, x_label = 'Sex'
, y_label = 'Number of People'
, title = 'Number of People By Survived Or Not and Sex')
ax=plt.gca()
ax.set_xticks(range(2))
ax.set_xticklabels(sex_survived.index.values)
[<matplotlib.text.Text at 0x7f89ca1c3a10>,
<matplotlib.text.Text at 0x7f89ca1ce0d0>]
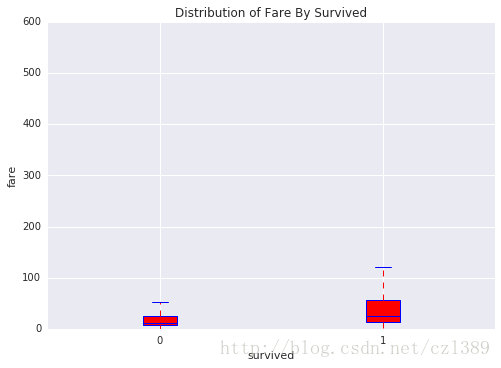
幸存or遇难の票价分布
survived=data['survived'].unique()
bp_data=[data[data['survived']==survived[0]]['fare'],data[data['survived']==survived[1]]['fare']]
boxplot(x_data = survived
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'survived'
, y_label = 'fare'
, title = 'Distribution of Fare By Survived')
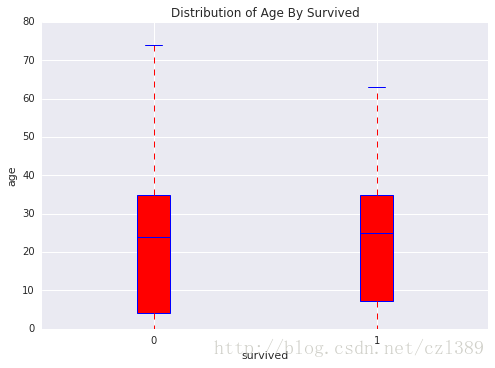
幸存or遇难の年龄分布
data['age'].fillna(0,inplace=True)
survived=data['survived'].unique()
bp_data=[data[data['survived']==survived[0]]['age'],data[data['survived']==survived[1]]['age']]
boxplot(x_data=survived
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'survived'
, y_label = 'age'
, title = 'Distribution of Age By Survived')
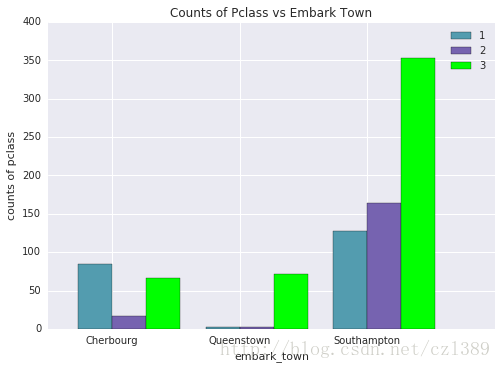
不同上传港口の仓位等级
embark_pclass=data.groupby(['embark_town','pclass']).size().unstack()
embark_pclass
| pclass |
1 |
2 |
3 |
| embark_town |
|
|
|
| Cherbourg |
85 |
17 |
66 |
| Queenstown |
2 |
3 |
72 |
| Southampton |
127 |
164 |
353 |
pclass_list=[embark_pclass.iloc[:,0],embark_pclass.iloc[:,1],embark_pclass.iloc[:,2]]
pclass_list
[embark_town Cherbourg 85 Queenstown 2 Southampton 127 Name: 1, dtype: int64, embark_town Cherbourg 17 Queenstown 3 Southampton 164 Name: 2, dtype: int64, embark_town Cherbourg 66 Queenstown 72 Southampton 353 Name: 3, dtype: int64]
groupedbarplot(x_data = range(3)
, y_data_list = pclass_list
, y_data_names = embark_pclass.columns
, colors = ['#539caf', '#7663b0','#00ff00']
, x_label = 'embark_town'
, y_label = 'counts of pclass'
,title = 'Counts of Pclass vs Embark Town')
ax=plt.gca()
ax.set_xticks(range(3))
ax.set_xticklabels(embark_pclass.index.values)
[<matplotlib.text.Text at 0x7f89c9f488d0>,
<matplotlib.text.Text at 0x7f89ca045b10>,
<matplotlib.text.Text at 0x7f89c9eec150>]
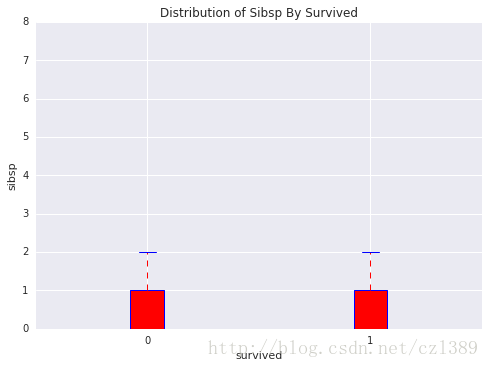
幸存or遇难の堂兄弟姐妹数量分布
survived=data['survived'].unique()
bp_data=[data[data['survived']==survived[0]]['sibsp'],data[data['survived']==survived[1]]['sibsp']]
boxplot(x_data=survived
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'survived'
, y_label = 'sibsp'
, title = 'Distribution of Sibsp By Survived')
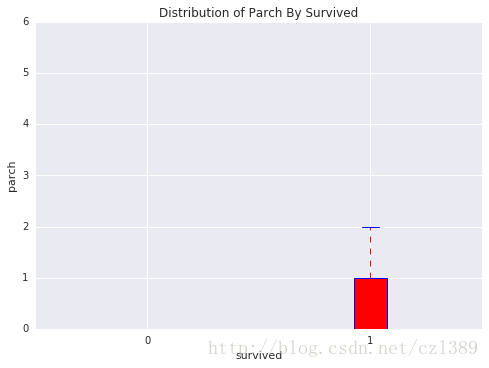
幸存or遇难の父母子女数量分布
survived=data['survived'].unique()
bp_data=[data[data['survived']==survived[0]]['parch'],data[data['survived']==survived[1]]['parch']]
boxplot(x_data=survived
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'survived'
, y_label = 'parch'
, title = 'Distribution of Parch By Survived')
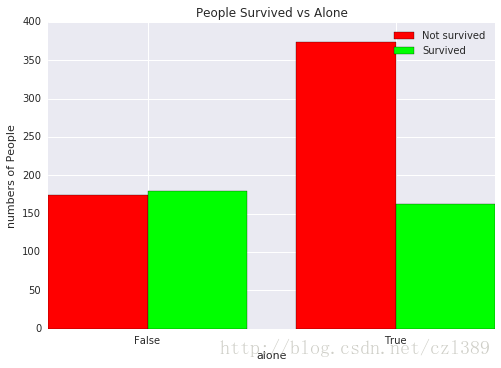
单独乘船 vs 幸存
alone_survived=data.groupby(['alone','survived']).size().unstack()
alone_survived
| survived |
0 |
1 |
| alone |
|
|
| False |
175 |
179 |
| True |
374 |
163 |
_, ax = plt.subplots()
width=0.4
index=alone_survived.index.values
ax.bar(index, alone_survived[0], color = '#ff0000', label = 'Not survived', width = width)
ax.bar(index+width, alone_survived[1], color = '#00ff00', label = 'Survived', width = width)
ax.set_ylabel('numbers of People')
ax.set_xlabel('alone')
ax.set_title('People Survived vs Alone')
ax.legend(loc = 'upper right')
plt.xticks(index+width,index)
([<matplotlib.axis.XTick at 0x7f89ca2d73d0>,
<matplotlib.axis.XTick at 0x7f89ca85f4d0>],
<a list of 2 Text xticklabel objects>)