广州代孕_广州育儿g
【正规代孕】【微*电138*0226*9370】代孕,是指将受精卵子植入代孕妈妈子宫,由孕母替他人完成“十月怀胎一朝分娩”的过程。妇女代孕时需植入他人的受精卵子,精子与卵子在人体外的结合,必须实施“人类辅助生殖技术”。我国有关法律对“人类辅助生殖技术”的实施做了严格的规定。
代孕是一种新的观念,新的趋势。在现今社会里人类文明高度发达,依然有不少不孕不育的夫妇。随着人工生殖科技的迅速发展,七十年代以来,欧美各国陆续开始有人委托代理孕母怀孕生子,代孕是一种解决不孕不育的临床选择。
隐含狄利克雷分布
简称LDA(Latent Dirichlet allocation),首先由Blei, David M.、吴恩达和Jordan, Michael I于2003年提出,目前在文本挖掘领域包括文本主题识别、文本分类以及文本相似度计算方面都有应用。
LDA就是在pLSA的基础上加层贝叶斯框架,即LDA就是pLSA的贝叶斯版本。
pLSA与LDA对比(文档生成方式)

pLSA与LDA对比(文档生成方式)
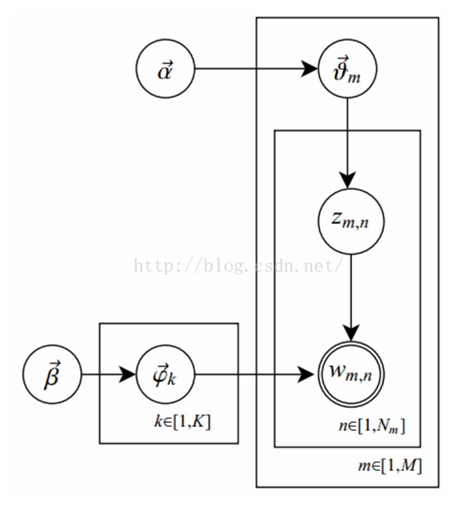
Note:
- 阴影圆圈表示可观测的变量,非阴影圆圈表示隐变量;箭头表示两变量间的条件依赖性;方框表示重复抽样,方框右下角的数字代表重复抽样的次数。
- 对应到图, 和 是超参数;方框 表示有k种“主题-词项”分布; 有M种“文档-主题分布”,即每篇文档都会产生一个 分布;每篇文档m中有n个词,每个词 一个主题 ,该词实际上由 产生
- β⃗ 到φ(生成topic-word分布的分布) and α⃗到θ(生成doc-topic分布的分布) 是狄利克雷分布,θ生成z(赋给词w的主题) and φ生成w(当前词) 是多项式分布。θ指向z是从doc-topic分布中采样一个主题赋给w(但是此时还不知道词w具体是什么,而是只知道其主题),φ指向w是φ的topic-word分布依赖于w。
pLSA与LDA对比(概率图)
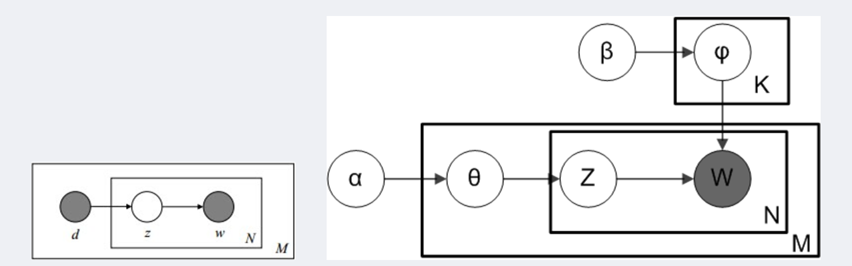
对应到上面右图的LDA,只有W / w是观察到的变量,其他都是隐变量或者参数,其中,Φ表示词分布,Θ表示主题分布,α是主题分布Θ的先验分布(即Dirichlet 分布)的参数,β是词分布Φ的先验分布的参数,N表示文档的单词总数,M表示文档的总数。
假定语料库中共有M篇文章,每篇文章下的Topic的主题分布是一个从参数为的Dirichlet先验分布中采样得到的Multinomial分布,每个Topic下的词分布是一个从参数为的Dirichlet先验分布中采样得到的Multinomial分布。
对于某篇文章中的第n个词,首先从该文章中出现的每个主题的Multinomial分布(主题分布)中选择或采样一个主题,然后再在这个主题对应的词的Multinomial分布(词分布)中选择或采样一个词。不断重复这个随机生成过程,直到M篇文章全部生成完成。
M 篇文档会对应于 M 个独立的 Dirichlet-Multinomial 共轭结构(每篇文档都有其独特不同的doc-topic分布),K 个 topic 会对应于 K 个独立的 Dirichlet-Multinomial 共轭结构。
其中,α→θ→z 表示生成文档中的所有词对应的主题,显然 α→θ 对应的是Dirichlet 分布,θ→z 对应的是 Multinomial 分布,所以整体是一个 Dirichlet-Multinomial 共轭结构,如下图所示:
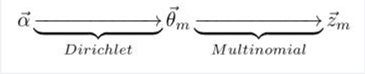
类似的,β→φ→w,容易看出, 此时β→φ对应的是 Dirichlet 分布, φ→w 对应的是 Multinomial 分布, 所以整体也是一个Dirichlet-Multinomial 共轭结构,如下图所示:

pLSA与LDA对比(生成模型)
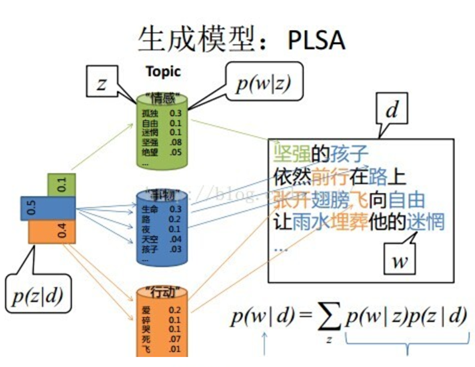
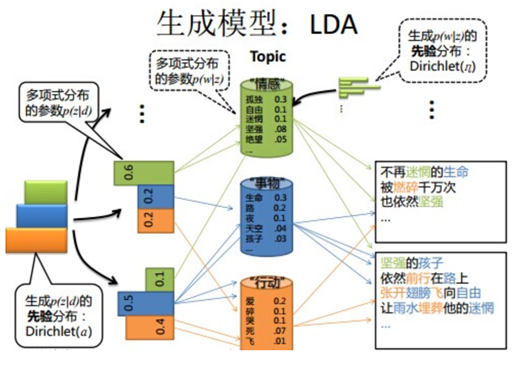
第一个图已经讲解过了,第二个图,在每次生成一个文档前,我先生成文档主题的先验分布,得出每篇文档不同的主题分布,生成词汇的分布同理。
本质区别详解,PLSA中,主题分布和词分布是唯一确定的,能明确的指出主题分布可能就是{教育:0.5,经济:0.3,交通:0.2},词分布可能就是{大学:0.5,老师:0.3,课程:0.2}。
LDA中,主题分布和词分布不再唯一确定不变,即无法确切给出。例如主题分布可能是{教育:0.5,经济:0.3,交通:0.2},也可能是{教育:0.6,经济:0.2,交通:0.2},到底是哪个我们不再确定,因为它是随机的可变化的。但再怎么变化,也依然服从一定的分布,即主题分布跟词分布由Dirichlet先验随机确定。面对多个主题或词,各个主题或词被抽中的概率不一样,所以抽取主题或词是随机抽取。主题分布和词分布本身也都是不确定的,正因为LDA是PLSA的贝叶斯版本,所以主题分布跟词分布本身由先验知识随机给定。
pLSA与LDA对比(参数估计)

隐含狄利克雷分布
简称LDA(Latent Dirichlet allocation),首先由Blei, David M.、吴恩达和Jordan, Michael I于2003年提出,目前在文本挖掘领域包括文本主题识别、文本分类以及文本相似度计算方面都有应用。
LDA就是在pLSA的基础上加层贝叶斯框架,即LDA就是pLSA的贝叶斯版本。
pLSA与LDA对比(文档生成方式)
pLSA与LDA对比(文档生成方式)
Note:
- 阴影圆圈表示可观测的变量,非阴影圆圈表示隐变量;箭头表示两变量间的条件依赖性;方框表示重复抽样,方框右下角的数字代表重复抽样的次数。
- 对应到图, 和 是超参数;方框 表示有k种“主题-词项”分布; 有M种“文档-主题分布”,即每篇文档都会产生一个 分布;每篇文档m中有n个词,每个词 一个主题 ,该词实际上由 产生
- β⃗ 到φ(生成topic-word分布的分布) and α⃗到θ(生成doc-topic分布的分布) 是狄利克雷分布,θ生成z(赋给词w的主题) and φ生成w(当前词) 是多项式分布。θ指向z是从doc-topic分布中采样一个主题赋给w(但是此时还不知道词w具体是什么,而是只知道其主题),φ指向w是φ的topic-word分布依赖于w。
pLSA与LDA对比(概率图)
对应到上面右图的LDA,只有W / w是观察到的变量,其他都是隐变量或者参数,其中,Φ表示词分布,Θ表示主题分布,α是主题分布Θ的先验分布(即Dirichlet 分布)的参数,β是词分布Φ的先验分布的参数,N表示文档的单词总数,M表示文档的总数。
假定语料库中共有M篇文章,每篇文章下的Topic的主题分布是一个从参数为的Dirichlet先验分布中采样得到的Multinomial分布,每个Topic下的词分布是一个从参数为的Dirichlet先验分布中采样得到的Multinomial分布。
对于某篇文章中的第n个词,首先从该文章中出现的每个主题的Multinomial分布(主题分布)中选择或采样一个主题,然后再在这个主题对应的词的Multinomial分布(词分布)中选择或采样一个词。不断重复这个随机生成过程,直到M篇文章全部生成完成。
M 篇文档会对应于 M 个独立的 Dirichlet-Multinomial 共轭结构(每篇文档都有其独特不同的doc-topic分布),K 个 topic 会对应于 K 个独立的 Dirichlet-Multinomial 共轭结构。
其中,α→θ→z 表示生成文档中的所有词对应的主题,显然 α→θ 对应的是Dirichlet 分布,θ→z 对应的是 Multinomial 分布,所以整体是一个 Dirichlet-Multinomial 共轭结构,如下图所示:
类似的,β→φ→w,容易看出, 此时β→φ对应的是 Dirichlet 分布, φ→w 对应的是 Multinomial 分布, 所以整体也是一个Dirichlet-Multinomial 共轭结构,如下图所示:
pLSA与LDA对比(生成模型)
第一个图已经讲解过了,第二个图,在每次生成一个文档前,我先生成文档主题的先验分布,得出每篇文档不同的主题分布,生成词汇的分布同理。
本质区别详解,PLSA中,主题分布和词分布是唯一确定的,能明确的指出主题分布可能就是{教育:0.5,经济:0.3,交通:0.2},词分布可能就是{大学:0.5,老师:0.3,课程:0.2}。
LDA中,主题分布和词分布不再唯一确定不变,即无法确切给出。例如主题分布可能是{教育:0.5,经济:0.3,交通:0.2},也可能是{教育:0.6,经济:0.2,交通:0.2},到底是哪个我们不再确定,因为它是随机的可变化的。但再怎么变化,也依然服从一定的分布,即主题分布跟词分布由Dirichlet先验随机确定。面对多个主题或词,各个主题或词被抽中的概率不一样,所以抽取主题或词是随机抽取。主题分布和词分布本身也都是不确定的,正因为LDA是PLSA的贝叶斯版本,所以主题分布跟词分布本身由先验知识随机给定。
pLSA与LDA对比(参数估计)