题目
给定一个字符串,找出不含有重复字符的最长子串的长度。
示例:
给定 "abcabcbb" ,没有重复字符的最长子串是 "abc",那么长度就是3。
给定"bbbbb",最长的子串就是"b" ,长度是1。
给定"pwwkew" ,最长子串是 "wke" ,长度是3。请注意答案必须是一个子串,"pwke" 是子序列 而不是子串。
个人思路
首先我想到的是直接比对,就拿"abcabcbb"这个字符串来说:
首先使用两个指针来记录比较位置,start指针作为开头,一直往后移动,end指针接着start向后移动,遇到其中包含重复元素就停止向前走,等下一轮start指针向后移动一步的时候再走,然后使用tmp_len来保存临时长度,max_len记录最大长度,这样直到start指针走到最后即可判断出最大的无重复元素的长度,但是时间复杂度较大!,下面给出代码:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<limits.h>
//判断start到end位置之中有没有重复字符串
int isrepetition(char *start, char *end)
{
char *tmp = start;
while (start <= (end - 1))
{
if (*start == *end)
{
//有重复的返回0,否则返回1
return 0;
}
start++;
}
return 1;
}
int lengthOfLongestSubstring01(char* s) {
char *start = NULL;
char *end = NULL;
int len = 0;
int len_max = 0;
int flag = 0;
assert(s != NULL);
if (*s == 0)
{
return 0;
}
start = s;
//排除连续重复这种情况
while (*start)
{
if (*start != *s)
{
flag = 1;
}
start++;
}
if (flag == 0)
{
return 1;
}
else
{
start = s;
end = s + 1;
while (*start)
{
len = 1;
end = start + 1;
//将指针逐个传入,注意这里还有个条件是end指针若指向'\0'也应该退出循环
while (isrepetition(start, end) && (*end != 0))
{
len++;
end++;
}
//获取最大长度
len_max = len_max > len ? len_max : len;
start++;
}
return len_max;
}
}
虽然这样做不是特别快,LeetCode运行时间为264ms,效率是很低的,但是最大的优点就是节省空间,下面这种哈希表的方式效率很快,但是空间也是浪费了不少,等于是在拿空间换时间吧,而且更加容易理解的方式!
哈希的方式
只用哈希表无疑是解决这类办法的最优解,将一个存储127个元素的数组视为Hash表,先初始化为-1,遇到重复的则会开始新的一轮的计数:
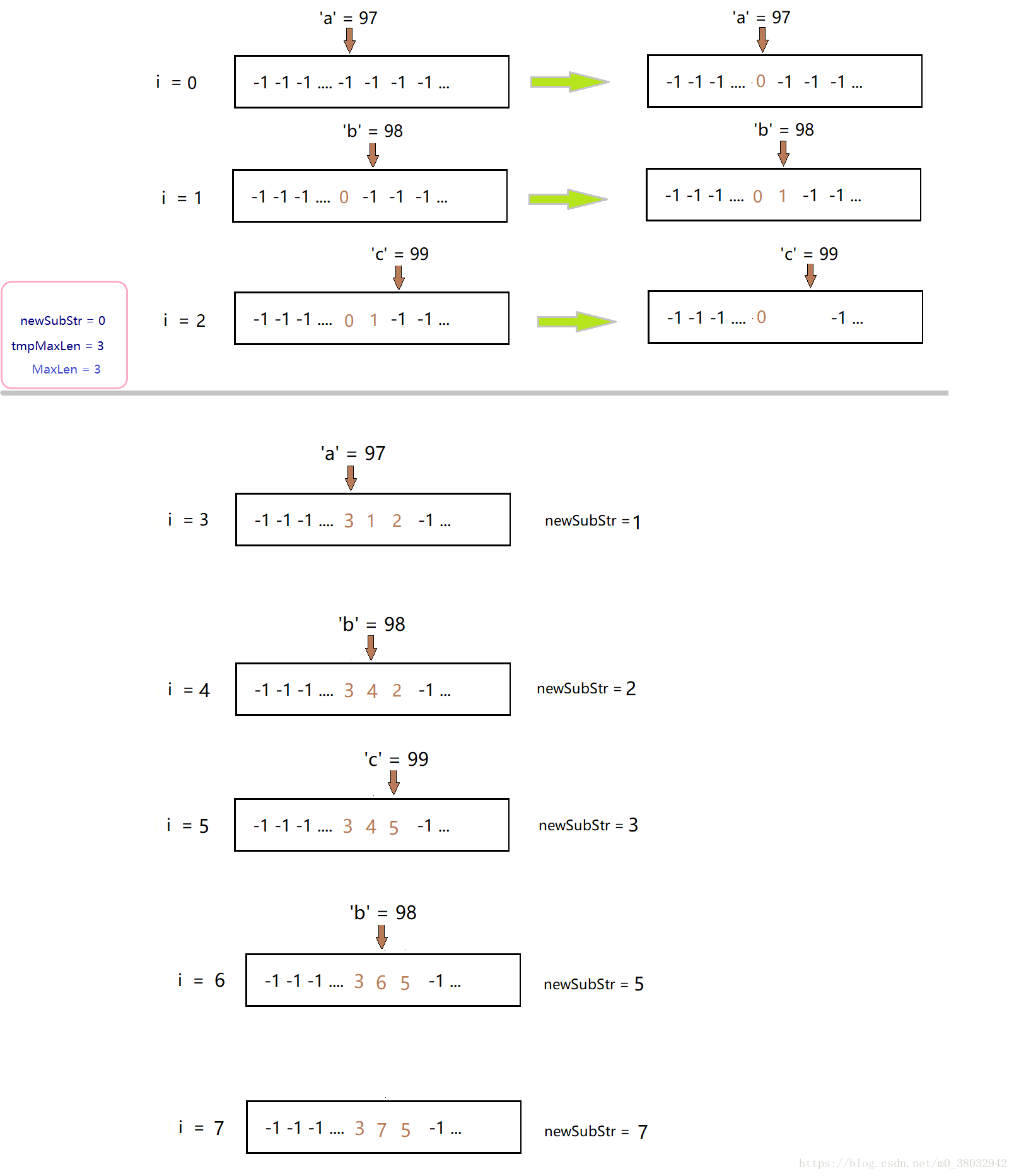
int lengthOfLongestSubstring(char* s) {
int hashTab[CHAR_MAX] = { 0 }; //0-- index 1--len
int i = 0, j = 0, strLen = 0, maxLen = 0, tmpMaxLen = 0;
int newSubStr = 0; //假设如果只有一个字符 那么上次找到的地方就是前面
if (NULL == s)
{
return 0;
}
strLen = strlen(s);
for (i = 0; i < CHAR_MAX; i++)
{
hashTab[i] = -1;
}
for (i = 0; i < strLen; i++)
{
if ((hashTab[*(s + i)] < newSubStr))
{
hashTab[*(s + i)] = i;
tmpMaxLen++;
}
else { //meet a same
/*计算原来的*/
maxLen = tmpMaxLen > maxLen ? tmpMaxLen : maxLen;
//代表新的一轮计数开始
newSubStr = hashTab[*(s + i)] + 1;
tmpMaxLen = i - newSubStr + 1;//代表新的一轮计数开始 +1是因为new和i都是新的长度
hashTab[*(s + i)] = i;
}
}
maxLen = tmpMaxLen > maxLen ? tmpMaxLen : maxLen;
return maxLen;
}最优解复杂度分析
时间复杂度:O(n)
空间复杂度(Table):O(m)O(m),mm 是字符集的大小。