本文介绍的内容,有真亦是假假亦真的部分,请读者自行斟酌。具体数据比较敏感,都使用模糊的描述方式代替。
概述
竞价广告,这个在大百度的时代就家喻户晓的词汇,相比大家也很熟悉了。顾名思义,竞价、竞价,广告位置有限,满足条件的竞争商家有很多,那么如何选择商家对商家排序。价高者应该是在没有任何数据积累的情况下,最原始的策略。这类广告的收费模型往往是按照点击次数付费(CPC),如果价高者得广告位,但是因为自身原因或者用户喜好原因,而没有发生点击,那么既浪费的流量,也降低了用户体验。所以除了出价(Bid)因素外,竞价广告还要解决的一个非常重要的问题就是点击率预估(CTR)。并用 BID * CTR 作为决定排序结果的主要因子,它直接衡量了该广告可以给平台带来的营收的期望值。
如果你留心观察(一定要留心,因为广告标小到很难看到),会发现淘宝,京东都有大量对竞价广告。下图展示了饿了么首页、分类页,搜索结果页面的竞价广告。

整体架构
在深入介绍之前,首先抛出系统的整体架构,大致可以分为基础数据层,策略层和应用层。

基础数据层主要是大数据平台提供用户日志(UBT)行为,和各种业务数据,包括用户资料,订单数据,历史评价等。
有了这些基础数据,数据挖掘工程师可以真对业务场景,挖掘出大量的符合广告场景的用户商户基础画像,用户商户交叉画像,针对时间和领域的细分特征,以及抽象用户当下喜好或者行为的实时特征。有了画像、特征数据和用户行为历史,就可以用这些打标的历史数据来做点击率预估模型和转化率预估模型,产出通常是模型文件提供给线上使用。
用户浏览请求的第一步会经过Lucene搜索引擎召回粗排结果,例如命中配送范围内商户,过滤掉关闭商户等,如果是搜索页广告,商户要命中搜索词。获得粗排商户列表后,载入用户画像、商户画像等特征数据以及业务数据,按照规则做特征变换得到模型可用数据,然后用模型计算预估点击率或者转化率,最后按照规则(可能是比 BID * CTR 更复杂的规则)排序商户。
应用层是不同业务形态广告的接入方,可以饿了么APP首页分类页的竞价广告,搜索页面的关键词广告,也可能是新零售业务的竞价广告。
下面分别从特征、样本生成、模型、在线引擎等方面分别深入介绍一下系统。
特征维度
在机器学习领域,有一个很著名的说法:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。出去演讲,大家基本也是秉承着模型随便聊,特征却闭口不提的潜规则,可见特征的核心重要度。对于计算广告这种传统而特征容易提取的领域,前期投入到特征挖掘带来的质量提升是更明显的。当然特征的挖掘也是循序渐进,不断迭代的,至今我们的特征工程体系下,主要包括如下种类的特征:用户画像、商户画像、用户商户交叉画像、实时特征、细分特征等。
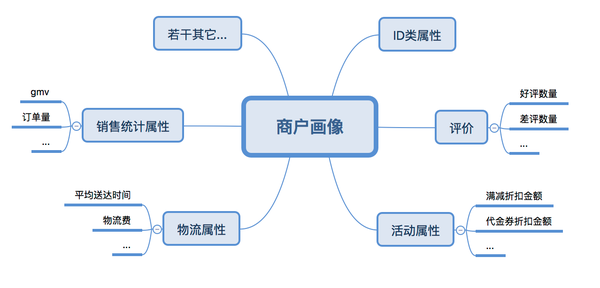
1. 商户画像
。主要刻画了商户的属性,可以使用各种统计数据来做挖掘,不同的业务需求,挖掘的特征也有所不同。下图展示了用户画像和商户画像的分类举例。
2. 用户画像
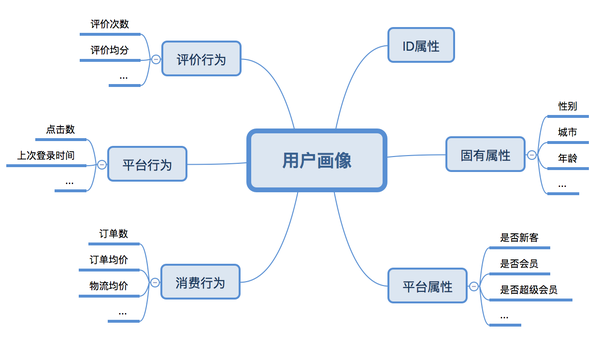
3. 用户商户交叉画像,
这类画像主要刻画了商户和用户之间的关系,该类特征可以很好的刻画反购倾向,有如下若干分类。

4. 细分特征
,细分特征严格 意义来说,并不算是一类单独的特征,它是对基本特征做细粒度拆分的手段。通常有几种做特征细分的方式。
a. 按照某个条件细粒的值域扩展
,例如gmv是衡量用户给平台的总营收的属性,这个属性可以按照性别 user_sex (取值1、2) 做拆分,此时一个 gmv 属性,可以拆成 gmv_user_sex_1 和 gmv_user_sex_2两个属性。
b. 按照特征+值域范围组合,值
域范围例如时间,例如基础属性同样是gmv,可以按照用户在不同时间段贡献的gmv拆分成,gmv_at_morning,gmv_at_noon,gmv_at_afternoon, gmv_night 等。通过这样的拆分可以更精细的描述用户,例如上面的例子,对于白天很少点外卖正餐,晚上经常外卖吃宵夜的用户,区分度就很高。
根据业务敏感度不同,还有更多的细分手段。
5. 实时特征,
用来刻画用户的实时行为,例如当下用户口味偏好,当下对某个店铺的喜好程度等。

样本生成
1. 离线样本生成
各类画像数据准备好以后,我们要生成打标的训练样本,以训练模型。打标数据根据在我们的业务下主要是,曝光点击表(用于CTR模型),点击转化表等(用于CVR模型)。我们这里以训练CTR模型为例,主要拆分成如下步骤:首先将各类画像表数据和点击日志做Join操作,操作等 key 值就是用户画像或者商户画像;得到宽表后(merged wide log),对数据做预处理,例如对于值缺失的,加上默认值等;然后做特征变换,包括归一化、分桶、one-hot编码等,最后得到纯数字的,可以被模型训练使用的样本表。流程图如下:
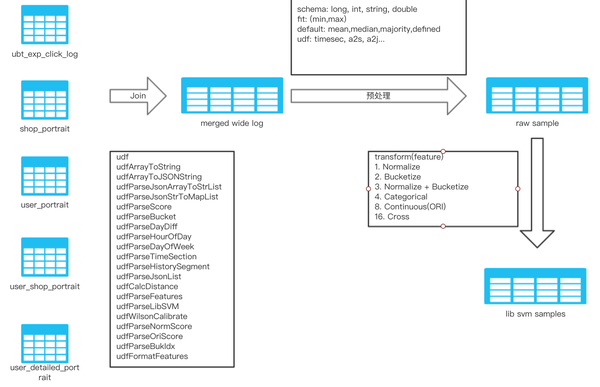
对于专家读者,这个操作是天经地义的,不过也准备了一个小例子阐述一下特征工程的做法,假设有用户画像如下:
{
"userId"
:
1000
,
"sex"
:
"男"
,
"age"
:
20
,
"phone"
:
"iphoneX"
}
商户画像如下:
{
"shopId"
:
2000
,
"cateLevel1"
:
"川菜"
,
"cateLevel2"
:
"火锅"
,
"shop_gmv"
:
300000
,
"falor"
:
"辣"
}
以及曝光点击日志如下:
[
{
"exp"
:
1
,
"click"
:
0
,
"shopId"
:
2000
,
"userId"
:
1000
,
"time"
:
"2017-12-12 12:34:00"
}
,
{
"exp"
:
1
,
"click"
:
1
,
"shopId"
:
2000
,
"userId"
:
1000
,
"time"
:
"2017-12-12 14:34:00"
}
]
那么我们需要把日志表里面的 userId 和 shopId 分别和用户画像和商户 Join 操作,变成拥有所有属性的样本表。
[
{
"exp"
:
1
,
"click"
:
0
,
"shopId"
:
2000
,
"userId"
:
1000
,
"age"
:
"20"
,
"shop_gmv"
:
300000
,
"cateLevel1"
:
"川菜"
,
"cateLevel2"
:
"火锅"
,
"falor"
:
"辣"
,
"sex"
:
"男"
,
"phone"
:
"iphoneX"
,
"time"
:
"2017-12-12 12:34:00"
}
,
{
"exp"
:
1
,
"click"
:
1
,
"shopId"
:
2000
,
"userId"
:
1000
,
"age"
:
"20"
,
"shop_gmv"
:
300000
,
"cateLevel1"
:
"川菜"
,
"cateLevel2"
:
"火锅"
,
"falor"
:
"辣"
,
"sex"
:
"男"
,
"phone"
:
"iphoneX"
,
"time"
:
"2017-12-12 14:34:00"
}
]
这样我们就获得了一条正样本(曝光了并且点击了)和负样本(曝光了,没点击)。最后一步我们把数据做特征变换,变成模型可以使用的数据,例如下面的样子。
[
{
"exp"
:
1
,
"click"
:
0
,
"shopId"
:
2000
,
"userId"
:
1000
,
"age"
:
"0.3"
,
//归一化后值,最简单的 minmax 归一
"age_1"
:
1
,
//归一化后分桶, //例如分桶为
[
0
,
0.2
)
,
[
0.2
,
0.4
)
,
[
0.4
,
0.6
]
..用户落在编号是
1
的桶中
"shop_gmv"
:
0.8
,
//归一化
"cateLevel1_川菜"
:
1
,
//one hot
"cateLevel2_火锅"
:
1
,
//one hot
"falor_辣"
:
1
,
//one hot
"sex_男"
:
1
,
//one hot
"phone_iphoneX"
:
1
,
//one hot
"noon"
:
1
,
//根据时间做的自定义转化,例如抽取时间部分中午
"dayOfWeek_1"
:
1
//抽取星期部分,是星期一
}
]
2. 样本快照
先介绍下这个技术的前提,假设我们已经根据生成的样本,训练了模型,模型已经推上线。线上载入模型后,要对当前对用户,商户的点击率做预测,那么首先线上要载入各类画像数据,然后做特征变换,然后用变换后的值输入模型获得预测结果。那么我们会发现,离线部分和线上部分都有Join画像和做特征变换这个步骤。而这两个部分往往使用不同的语言实现,甚至是不同的开发人员实现,一旦出现不一致就很难发现问题所在。
所以,我们的做法是把线上做了特征变换后的样本值-样本快照,传到 kafka,落到 hdfs,用这部分数据和曝光点击表做 Join 获得到离线和线上一致的样本数据,实践证明有很明显的提升。
模型
如果问,有什么模型常常被同行投来鄙夷目光的,答案应该是逻辑回归(LR)吧;如果问,有哪些万金油模型甚至都被别人忽略她是机器学习模型的模型,那么应该也是 LR 吧。在很长一段时间里,系统都是一个 LR 模型,用它预测CTR、CVR。。
在特征工程发展到前文所提的所有内容后,开始朝着模型方向做很多尝试,首先尝试 GBDT,然后 GBDT+LR,再然后是 FM,FTRL,DNN(Deep & Wide)。其中模型部分提升很明显的有 GBDT+LR,和 FTRL。
关于GBDT、GBDT+LR可以参考我的另外一篇文章,从原理到实践都有深入的阐述:
GBDT的原理和应用
。这篇文章把我自行推导的时候不明白的地方都做了重点阐述,仔细阅读相信可以弄清楚 GBDT 的来龙去脉。
重点说一下 FTRL ,其实它并不是一个模型,而是一种在线学习的模型训练的方式。传统的模型训练和上线的方式一般都是隔天的,定时任务会拉取一定时间的区间的样本数据,训练后把模型推上线。而 FTRL,在线学习可以简单理解为根据线上用户的实时浏览和订单行为,不断更新模型。当初上线这个模型的时候,工程师们有一种养宝宝的感觉,随着时间的流逝发现AUC不断攀升。
FTRL 的训练也可以使用融合模型,类似于GBDT+LR的思想,例如使用预先训练好的 GBDT模型的叶子输出(相当于组合特征),作为FTRL的输入,然后实时更新 FTRL 部分的模型权重。线上使用同样的 GBDT 模型,然后用该GBDT模型在样本上的叶子输出和 FTRL 训练的权重计算出结果作为结果。下图反映的FTRL的在线学习框架。
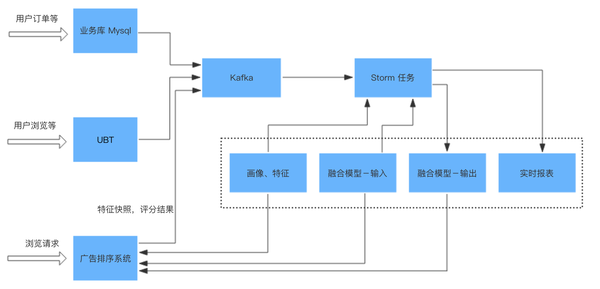
实时数据源主要来源两部分数据,UBT系统和业务数据,UBT的数据可以痛过消费 Kafka 的方式直接接入,业务数据可以通过 Canal 等组建(饿厂是自己的DRC)拉取 mysql binlog内容,然后把业务数据库读写发送到 Kafka 上。FTRL 使用 storm 部署,逐条消费实时数据,对模型更新,并把模型参数写入到 Redis 中。线上预测服务,根据需要读取画像数据、融合模型、以及FTRL的参数数据,进行预测。
既然打通了实时数据流,也可以做到实时的 AUC 监控。做法是线上每次执行一次排序,都会生成一个唯一随机数 rankId,然后把排序结果通过 kafka 传到 storm中。storm 通过消费 UBT 日志、对比评分结果就可以实时的计算出模型的 AUC,再把这些数据实时推到 Metrcs 系统。事实上,实时监控非常强大好用,可以极大的提高模型的反馈速度。
当然不得不提的是,对于模型预测出来的值,还需要使用校准获得逼近真实的点击率,这样使得计算 BID * CTR 真是反映营收期望,以便和其它指标融合的时候更有效。例如线上可能采用如下方式作为平台优化目标:
g = b*t + \beta *v
其中
b
代表商户出价,
t
代表预估点击率,
\beta
是一个系数可以配置,
v
代表预估转化率。有时候,广告营收和产品体验之间要做一些权衡,融合其它指标是个很好的方案。如果预测出来的点击率不是真实的点击率那么融合其它指标的时候,整体目标就会失效。校准部分一般采用保序回归校准的方式。
在线引擎
随着目标指标的增多,模型种类增多,融合的手段增多,线上部分也变得越来越复杂,下图展示了线上引擎部分的框架。
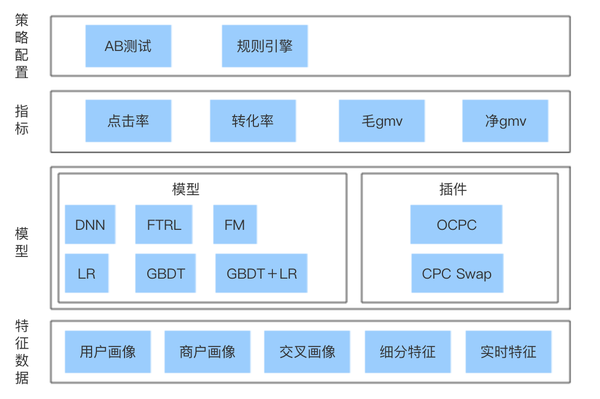
首先接入AB测试平台后,平台会为给用户分配要执行的策略。规则引擎部分配置了该策略需要使用的指标(预估点击率、转化率等),每个预测指标需要的基础数据以及每个指标需要采用的模型等。
然后按照规则引擎的定义,加载线上需要的各种基础数据,做特征转换,输入模型得到预测结果,然后进行校准。最后把各个指标的值,按照规则引擎的定义组合最后获得商户的排序分。
上图中多了一块插件模块,真对广告领域 CTR 预估,很多厂做了一些真对出价的优化,包括淘宝的OCPC等。这些部分可以真对所有指标预测都可以使用,可以做成插件的模式,可以做到随时插拔使用。
结论
竞价广告这款产品走到今天,无论从变现效率,还是营收体量都是一款很成功的产品了。而本文内容,对于流量大厂会显得一点也不陌生,甚至可能会略有初级。当然对于小厂或者刚刚尝试流量变现的流量巨头,依然是有借鉴意义的。