这是关于pandas中的一些基本操作的第一部分:
1.文件的读取的一些基本操作和计算:pd.read_csv
2.对数据进行排序:sort_values
3.一个小案例
4.对缺失值进行处理(求均值):mean()
5.1利用透视表(pivot_table)–数据分析工具:实现统计不同舱位的获救几率,以及平均年龄
5.2一个变量与其他两个变量的关系:三个码头各自的总舱位船票价格和总获救人数
6.将缺失值舍去,函数:dropna
7.定位到表中的某一个具体值;loc[ ]
8.排序:loc[ ]:通过行标签索引行数据
9.自定义函数:apply()
对于axis函数的解释:
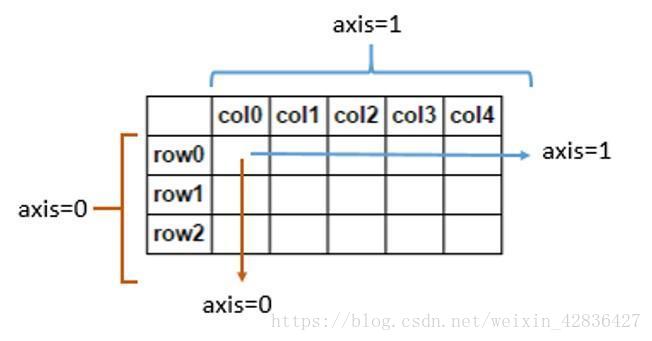
axis=0、axis=index,指的是遍历每个index、行号,即在纵向上遍历每列,所以做sum()、mean()等运算时,是对每列数据做操作,而drop(index, axis=0),传入的参数指定了某一行号,所以会在纵向上遍历每列,去掉行号对应位置的数据。
axis=1、axis=columns,指的是遍历每个columns、列名,即在横向上遍历每行,所以做sum()、mean()等运算时,是对每行数据做操作,而drop(col, axis=1),传入的参数指定了某一列名,所以会在横向上遍历每行,去掉列名对应位置的数据
import numpy as np
import pandas as pd
#1.文件的读取的一些基本操作和计算
food_info=pd.read_csv(r"D:\Python.code(4)\2-pandas\food_info.csv")
print(type(food_info))
print(food_info.dtypes)#查看数据类型
print(help(pd.read_csv))
print(food_info.head())#显示前5行
print(food_info.tail(4))#显示后4行
#print(food_info.column)#得到列名
print(food_info.shape )#8618个样本,每个样本有36个指标
print(food_info.loc[3:6])#进行切片,取出某一部分的数据
max_calories=food_info["Energ_Kcal"].max()#获取最大最小值
print(max_calories)
#2.对数据进行排序
food_info.sort_values ("Sodium_(mg)",inplace= True )#从小到大进行排序,是否生成新的
print(food_info['Sodium_(mg)'])
food_info.sort_values ("Sodium_(mg)",inplace= True ,ascending=False)#升序为Flase,则执行降序
print(food_info['Sodium_(mg)'])
#3.一个小案例
titanic_survival=pd.read_csv(r"D:\Python.code(4)\2-pandas\titanic_train.csv")#导入数据
print(titanic_survival.head())#打印前5行
age=titanic_survival["Age"]#获取Age列
print(age.loc[0:10])
age_is_null=pd.isnull(age)#找出其中的缺失值
print(age_is_null)
age_null_true=age[age_is_null]
print(age_null_true)
age_is_count=len(age_null_true)#缺失值个数
print(age_is_count)
#4.对缺失值进行处理(求均值)
good_ages=titanic_survival["Age"][age_is_null==False]#找到没有确实值的数据,通过Flase进行排除
correct_mean_age=sum(good_ages)/len(good_ages)#求平均值
print(correct_mean_age)
correct_mean_age =titanic_survival["Age"].mean()#通过函数:mean()实现求平均值
print(correct_mean_age)
#5.1利用透视表(pivot_table)--数据分析工具:实现统计不同舱位的获救几率,以及平均年龄,
passenger_survival=titanic_survival.pivot_table(index="Pclass",values="Survived",aggfunc= np.mean)
print(passenger_survival )#index:统计关系以什么变量为基准,value:统计的关系的另一个变量,aggfunc:进行处理的函数
passenger_age=titanic_survival .pivot_table (index= "Pclass",values="Age")
print(passenger_age)
#5.2一个变量与其他两个变量的关系:三个码头各自的总舱位船票价格和总获救人数
port_stars=titanic_survival.pivot_table (index= "Embarked",values=["Fare","Survived"],aggfunc=np.sum)
print(port_stars)#其中aggfunc参数没有指定函数的时候默认是求均值
#6.将缺失值舍去,函数:dropna
drop_na_column=titanic_survival.dropna(axis=1)
new_titanic_survival=titanic_survival.dropna(axis=0,subset=["Age","Sex"])
print(new_titanic_survival)
#7.定位到表中的某一个具体值
row_index_83_age=titanic_survival.loc[83,"Age"]#第83个样本的age值
row_index_1000_pclass=titanic_survival.loc[766,"Pclass"]#第766个样本的值
print(row_index_83_age)
print(row_index_1000_pclass)
#8.排序
new_titanic_survival =titanic_survival.sort_values("Age",ascending=False)
print(new_titanic_survival[0:10])
titanic_reindexed=new_titanic_survival.reset_index(drop=True)
print("----------------")
print(titanic_reindexed.loc[0:10])#loc:通过行标签索引行数据
#9.自定义函数:apply
def hundredth_row(column):
hundredth_item=column.loc[99]
return hundredth_item
hundredth_row=titanic_survival.apply(hundredth_row)
print(hundredth_row)
#自定义2:将年龄类型进行离散化自定义,利用apply
def generate_age_label(row):
age=row["Age"]
if pd.isnull(age):
return "unkown"
elif age<18:
return "minor"
else:
return "adult"
age_labels=titanic_survival.apply(generate_age_label,axis=1)
print(age_labels)参考:链接:https://www.jianshu.com/p/4f18e8327872
本文以唐宇迪老师机器学习讲解为基础进行编写,仅供学习和参考。