概述
日志系统ELK使用详解(一)–如何使用
日志系统ELK使用详解(二)–Logstash安装和使用
日志系统ELK使用详解(三)–elasticsearch安装
日志系统ELK使用详解(四)–kibana安装和使用
日志系统ELK使用详解(五)–补充
在开始之前先说一下Logstash的使用和熟悉路线图。接触ELK的时候不能图快,可以尝试着一部分一部分的安装起来熟悉,之后再逐个组装到一起,看效果。
Logstash的独立性很高,熟悉路线可以按照这样来:
1.最基本的就是接收控制台输入,然后解析输出到控制台。
2.从文件读入,解析输出到控制台。
3.从文件读入,解析输出到elasticsearch。
4.实际应用中需要打通的关节。
接下来一起看一下Logstash,这个系列使用的版本(Logstash5.3.0)下载地址是:https://www.elastic.co/cn/downloads
安装
1.安装JDK 1.8.0_65
2.下载logstash5.3.0
3.解压logstash
控制台—》控制台
1.在…/logstash-5.3.0/bin/目录中新建一个文件std_std.conf文件
2.录入如下内容:
input {
stdin{
}
}
output {
stdout{
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.在bin目录执行命令:./logstash -f std_std.conf
4.稍等片刻,看到如下信息,说明启动完成了:
5.输入hello logstash!!!!,logash会在控制台回写出来这条信息:

文件—-》控制台
这里使用的文件是tomcat输出的access日志文件,很常见,内容如下:
111.206.36.140 - - [10/Aug/2016:23:16:29 +0800] "GET /nggirl-web/web/admin/work/special/listSelectedWork/v1.4.0?workIds=780 HTTP/1.1" 200 78 "http://www.baidu.com/s?wd=www" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)"
111.206.36.140 - - [10/Aug/2016:23:16:29 +0800] "GET /nggirl-web/web/admin/work/special/listSelectedWork/v1.4.0?workIds=780 HTTP/1.1" 200 78 "http://www.baidu.com/s?wd=www" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)"- 1
- 2
1.在bin目录新建file_std.conf文件;
2.内容如下:
input{
file{
path =>"/Develop/Tools/apache-tomcat-8.0.30/webapps/nggirllog/access.log"
start_position=>"beginning"
}
}
filter{
grok{
match=>{
"message"=>"%{DATA:clientIp} - - \[%{HTTPDATE:accessTime}\] \"%{DATA:method} %{DATA:requestPath} %{DATA:httpversion}\" %{DATA:retcode} %{DATA:size} \"%{DATA:fromHtml}\" \"%{DATA:useragent}\""
}
remove_field=>"message"
}
date{
match=>["accessTime","dd/MMM/yyyy:HH:mm:ss Z"]
}
}
output{
stdout{
codec=>rubydebug
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
3.然后运行./logstash -f file_std.conf,就会看到文件中原有的内容被逐条的显示在命令行了。
这个配置文件相对比较复杂,而且我们一般在使用elk的时候logstash的配置文件基本也是和这个类似,大同小异了,这里对关键部分详细解说一下。更深入的内容和使用方式,大家可以到elastic官网或者到logstash的最佳实战页面去看,网址是:http://udn.yyuap.com/doc/logstash-best-practice-cn/index.html。
input/file/path:这里指定了要对哪个日志文件进行扫描。如果希望扫描多个文件,可以使用*这个路径通配符;或者使用多个日志路径以数组形式提供(path=>[“outer-access.log”,”access.log”]);或者直接给定一个目录,logstash会扫描所有的文件,并监听是否有新文件。
filter/grok/match/message:里面的DATA和HTTPDATE都是grok语法内置的正则表达式,DATA匹配任意字符,HTTPDATE匹配joda类型的日期格式字符。上例中”\[“是匹配“[”。
filter/grok/match/date: 是对HTTPDATE日期格式的解释,joda可以支持很多复杂的日期格式,需要在这里指明才能正确匹配。
remove_field=>”message”:用处是去掉原有的整个日志字符串,仅保留filter解析后的信息。你可以试着去掉这一句就明白他的用处了。
解析成功后会看到控制台中类似如下的内容:
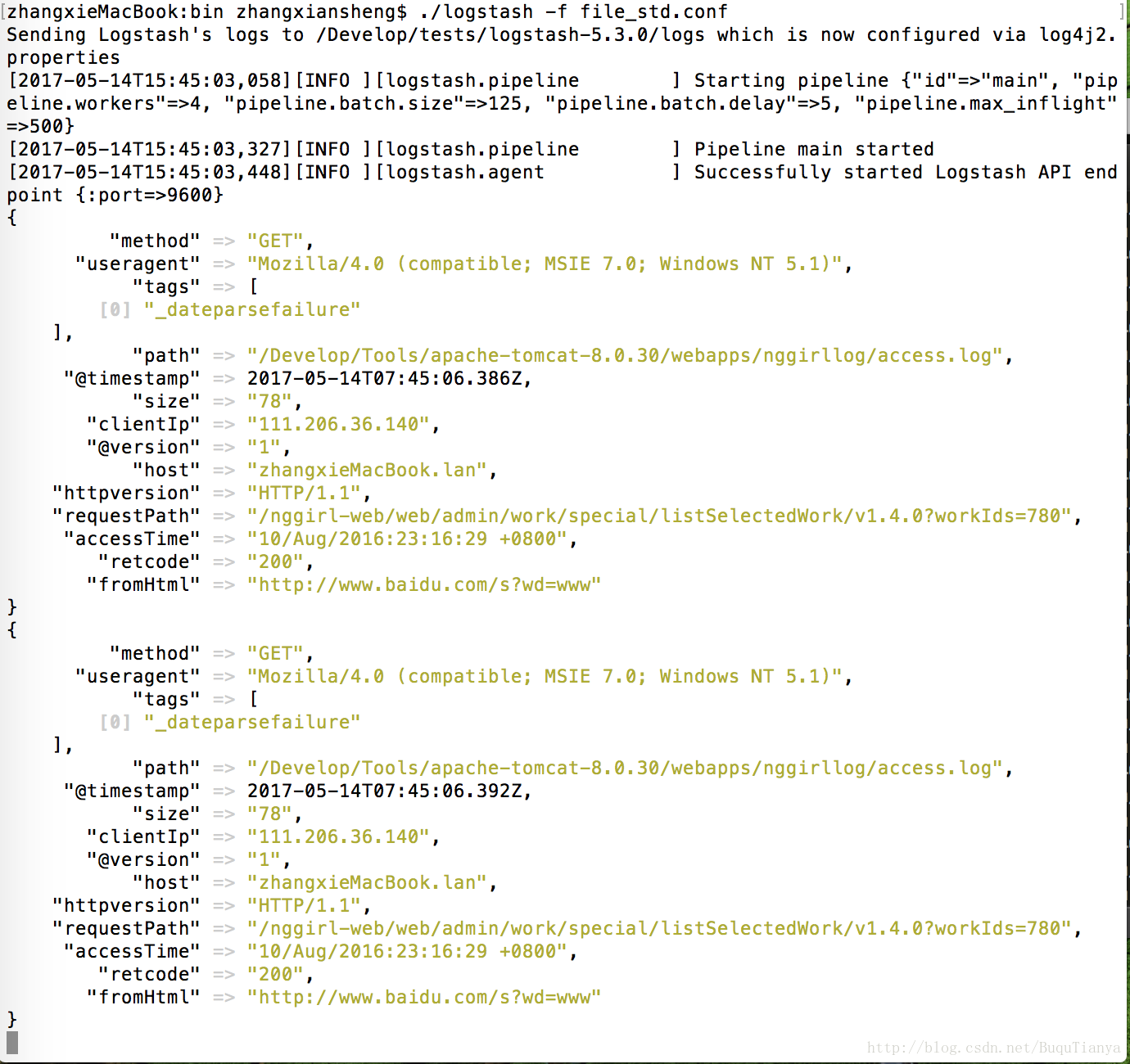
文件到elasticsearch
1.在bin目录新建file_es.conf文件
2.录入如下内容,和上一个例子的区别仅在于out部分:
input{
file{
path =>"/Develop/Tools/apache-tomcat-8.0.30/webapps/nggirllog/access*.log"
start_position=>"beginning"
}
}
filter{
grok{
match=>{
"message"=>"%{DATA:clientIp} - - \[%{HTTPDATE:accessTime}\] \"%{DATA:method} %{DATA:requestPath} %{DATA:httpversion}\" %{DATA:retcode} %{DATA:size} \"%{DATA:fromHtml}\" \"%{DATA:useragent}\""
}
remove_field=>["message"]
}
date{
match=>["accessTime","dd/MMM/yyyy:HH:mm:ss Z"]
}
}
output {
elasticsearch {
hosts => "127.0.0.1"
}
stdout { codec => rubydebug}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
3.执行./logstash -f file_es.conf
由于我们还没有开始部署elasticsearch,暂时不贴出效果,效果图将在下一个博客里面看到。
多行日志的处理
通过上面3步的熟悉,我们大概清楚了logstash的工作过程:
1.input读取指定文件里面的文本行,这里是一行一行读取的;
2.然后filter对读入的每一行进行解析,拆分成一组一组的key-value值;
3.out将解析后的结果输出写入到指定的系统。
但是,我们知道异常日志是一个多行文本,我们需要把多行信息输出到一行里面去处理,那么怎么办呢?
如果仍然按照单行文本的类似处理方式的话,我们需要在input部分添加配置项,如下:
input {
stdin {
codec => multiline {
pattern => "^\["
negate => true
what => "previous"
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这个配置是对每一个以”[“开头的行认作一个数据行的开始,后续不是以”[“开头的行都会认为是同一个数据的内容,当再次遇到”[“时结束这一个数据内容的读取,开始下一行。
这里有一个问题是,最后一个异常日志不能输出,因为logstash一直在等待下一个”[“的出现,但是一直没有出现,那么就不会输出了。
我们采用的处理多行文本的方式是自己实现了一个LogAppender,直接由程序日志类库以json串的形式输出到redis中,然后再由logstash读取。架构方式上属于第一篇中写的第二种架构方式。
以下是一些关键部分的代码片段:



补充:如果需要屏蔽不需要的日志,可以参见这里:http://www.tuicool.com/articles/Ubeiaea
#########################
转自:https://blog.csdn.net/buqutianya/article/details/72019264?utm_source=itdadao&ut