1.在集群上每台nginx服务器安装flume
2.配置flume
使用spooldir做为source,监控/soft/nginx/logs/flume文件夹。
创建eshop.conf配置文件 [/soft/flume/conf/eshop.conf]
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /soft/nginx/logs/flume //监听的文件夹
a1.sources.r1.fileHeader = true
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink //方式
a1.sinks.k1.kafka.topic = eshop //kafka创建的主题,将监听到的数据发往kafka
a1.sinks.k1.kafka.bootstrap.servers = s128:9092 s129:9092 s130:9092//kafka集群
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.分发eshop.conf 到每台机器的flume/conf下
4.a)因为kafka需要zk的支持,所以先使用zkServer.sh start 命令启动zk集群
b)启动kafka集群:kafka-server-start.sh /soft/kafka/config/server.properties
c)创建eshop主题:kafka-topics.sh --zookeeper s202:2181 --topic eshop --create --partitions 3 --replication-factor 3
d)启动flume:flume-ng agent -f eshop.conf -n a1
e)因为过后需要有hdfs消费者将kafka中的数据存储到hdfs,启动hdfs:start-dfs.sh
同时在项目的pom.xml文件添加依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.10.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
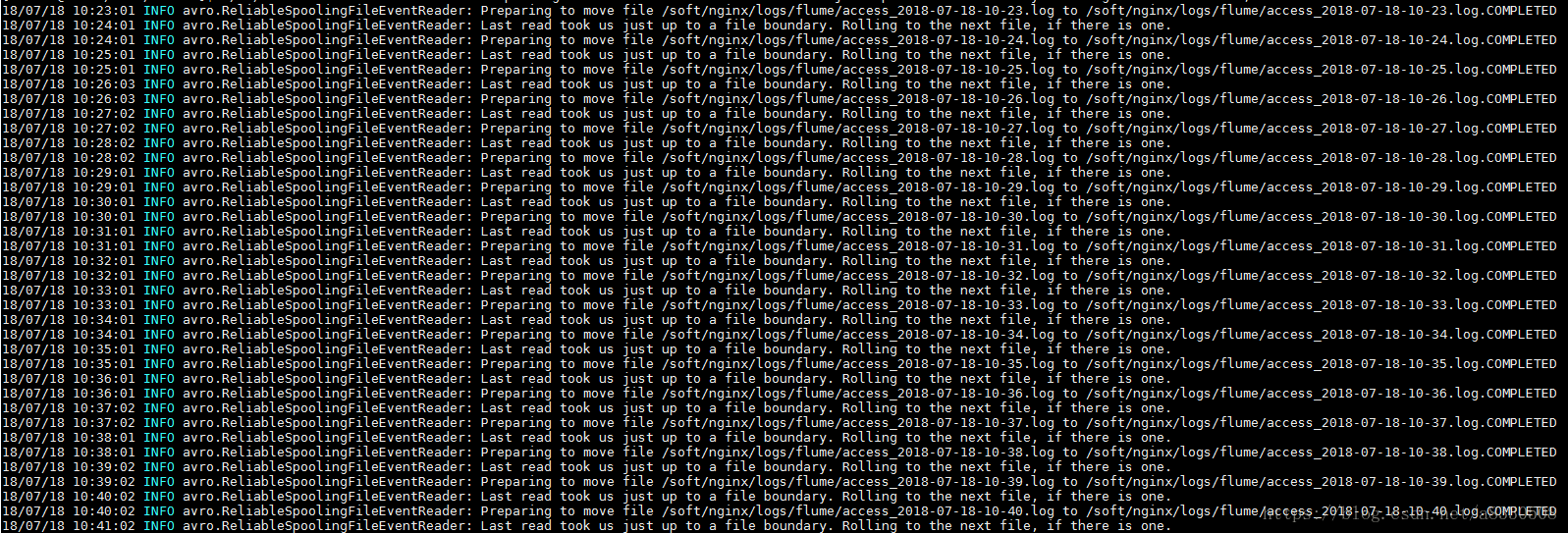
5.目前flume+kafka已经准备好,另外加上上一篇中的centos调度,每台机器每分钟会在flume会生成一个文件,并以当前时间命名:
6.在idea中创建一个idea消费者,目录如下:
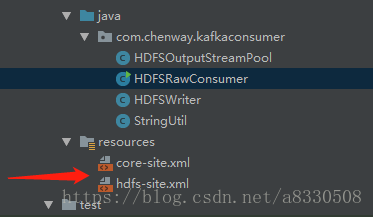
注意需要引入两个配置文件
从nginx获取到的数据格式如下:
s130|||192.168.23.1|||-|||18/Jul/2018:10:25:28 -0400|||GET /eshop/phone/iphone7.html HTTP/1.0|||200|||755|||-|||ApacheBench/2.3|||-
因为要从获取到的数据取出时间,作为hdfs中命名来存储文件,所以可以创建一个工具类StringUtil:
package com.chenway.kafkaconsumer;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
public class StringUtil {
//分
private static final String token = "\\|\\|\\|"; //分割符
public static String[] splitLog(String log){ //根据分割符得到数组
String[] arr = log.split(token);
return arr;
}
public static String getHostname(String[] arr){ //获取主机名
return arr[0];
}
public static String formatYyyyMmDdHhMi(String [] arr){//获取时间并转换为自己所需要的时间格式
try {
SimpleDateFormat sdf = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss",Locale.US);
Date d = sdf.parse(arr[3].split(" ")[0]);
System.out.println(d);
SimpleDateFormat localSdf = new SimpleDateFormat("yyyy/MM/dd/HH/mm",Locale.US);
return localSdf.format(d);
} catch (ParseException e) {
e.printStackTrace();
}
return null;
}
}
另外将每行获取到的数据写入hdfs中写到另外一个类HDFSWriter:
package com.chenway.kafkaconsumer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
/*
hdfs写入器
*/
public class HDFSWriter {
/*
写入log到hdfs文件
hdfs://mycluster/eshop/2018/07/18/s128.log | s129.log | s130.log
*/
public void writeLog2HDFS(String path,byte[] log) {
try {
FSDataOutputStream outputStream = HDFSOutputStreamPool.getInstance().getOutputStream(path);
outputStream.write(log);
outputStream.write("\r\n".getBytes());
outputStream.hsync();
outputStream.hflush();
} catch (IOException e) {
e.printStackTrace();
}
// FSDataInputStream in = fileSystem.open(new Path("hdfs://mycluster/user/centos/words.txt"));
// ByteArrayOutputStream baos = new ByteArrayOutputStream();
// IOUtils.copyBytes(in,baos,1024);
// System.out.println(new String(baos.toByteArray()));
}
}
注!!!在普通情况下,会通常需要打开流进行写操作然后再关闭流,这样太麻烦,不利于代码优化,可以使用输出流池化方式,意思就是当遇到的是新的流,就创建流,遇到的是旧的流就直接打开,不那么快关闭,再利用调度的方法,每隔一段时间清理一次池,创建HDFSOutputStreamPool类:
package com.chenway.kafkaconsumer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
/*
输出流池
*/
public class HDFSOutputStreamPool {
private FileSystem fs;
//存放所有的输出流
private Map<String, FSDataOutputStream> pool = new HashMap<String, FSDataOutputStream>();
private static HDFSOutputStreamPool instance;
private HDFSOutputStreamPool() {
try {
Configuration configuration = new Configuration();
fs = FileSystem.get(configuration);
} catch (Exception e) {
e.printStackTrace();
}
}
//单例设计模式
public static HDFSOutputStreamPool getInstance() {
if (instance == null) {
instance = new HDFSOutputStreamPool();
}
return instance;
}
public FSDataOutputStream getOutputStream(String path) {
try {
FSDataOutputStream out = pool.get(path);
if (out == null) {
Path p = new Path(path);
if (!fs.exists(p)) { //若不存在就创建
out = fs.create(p);
pool.put(path, out);
} else {
out = fs.append(p);//存在则直接追加
pool.put(path,out);
}
}
return out;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
最后创建HDFSRawConsumer关键类:
package com.chenway.kafkaconsumer;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/*
原生数据消费者
*/
public class HDFSRawConsumer {
private final ConsumerConnector consumerConnector;
private final String topic = "eshop";
private static HDFSWriter hdfsWriter = new HDFSWriter();
public HDFSRawConsumer(){ //配置信息
Properties properties = new Properties();
properties.put("zookeeper.connect","s128:2181,s129:2181,s130:2181");
properties.put("group.id","gg1");
properties.put("auto.offset.reset","smallest");
properties.put("zookeeper.session.timeout.ms","500");
properties.put("zookeeper.sync.time.ms","250");
properties.put("auto.commit.interval.ms","1000");
//创建消费者连接器
consumerConnector = Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
}
/*
处理log
*/
public void processMessage() throws IOException {
// 指定消费的主题
Map<String, Integer> topicCount = new HashMap<String, Integer>();
topicCount.put(topic, new Integer(1));
// 消费的消息流
Map<String, List<KafkaStream<byte[], byte[]>>> consumerStreams = consumerConnector.createMessageStreams(topicCount);
// 的到指定主题的消息列表
List<KafkaStream<byte[], byte[]>> streams = consumerStreams.get(topic);
for (final KafkaStream stream : streams) {
//
ConsumerIterator<byte[], byte[]> consumerIte = stream.iterator();
//迭代日志消息
while (consumerIte.hasNext()) {
byte[] msg = consumerIte.next().message();
//打印
System.out.println(new String(msg));
String log = new String(msg);
String arr[] = StringUtil.splitLog(log);
if (arr == null||arr.length<10){
continue;
}
//获取主机名
String hostname = StringUtil.getHostname(arr);
//获取时间
String dateStr = StringUtil.formatYyyyMmDdHhMi(arr);
//获取存入hdfs路径
String rawPath = "/user/centos/eshop/raw/"+dateStr+"/"+hostname+".log";
//写入数据
hdfsWriter.writeLog2HDFS(rawPath,msg);
}
}
}
public static void main(String[] args) throws IOException {
HDFSRawConsumer consumer = new HDFSRawConsumer();
consumer.processMessage();
}
}
最后通过在window10中,使用ab.exe -n 10000 -c 1000 http://localhost:80/eshop/phone/iphone7.html 进行压力测试
就是并发访问nginx静态资源,然后在nginx服务器上获取数据,然后将数据存储到文件中

flume监控到文件夹中有新文件的产生,将数据发往kafka,在idea中创建了hdfs消费者获取kafka中的数据,并打印:
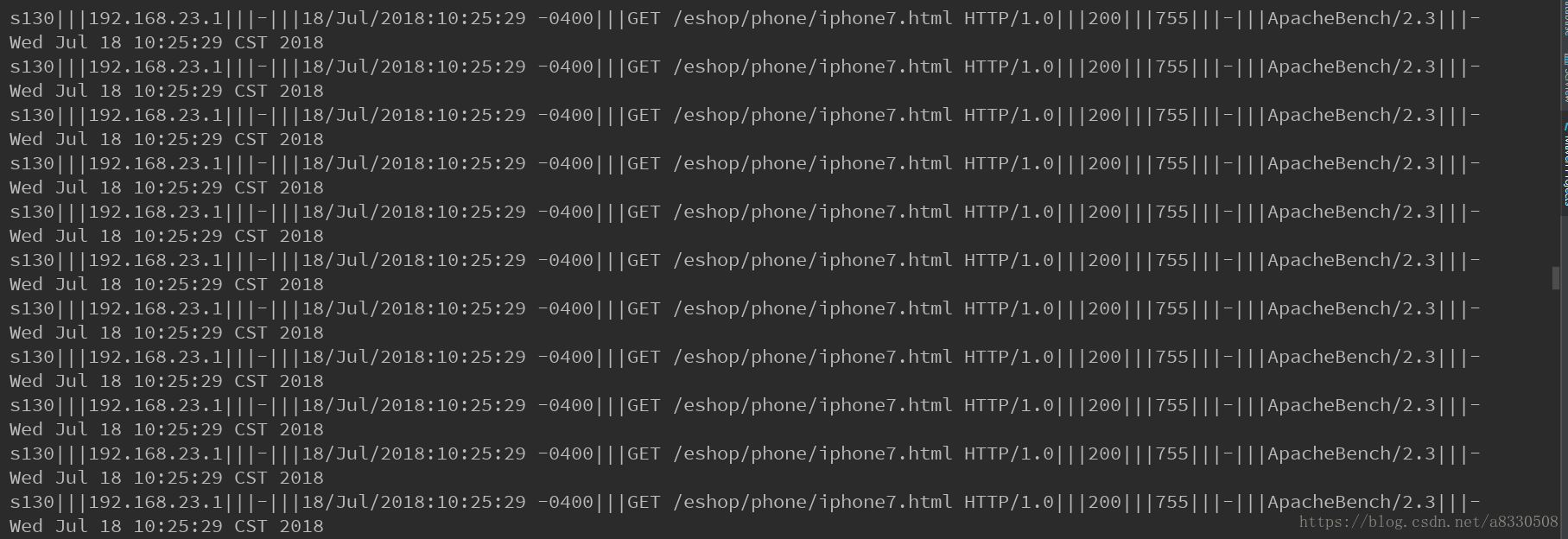
同时写入hdfs,并以时间命名:
