1.使用连接池
建立连接代价昂贵 连接池:存放连接的池子 池子中的连接已经预先创建好 可以直接分配给应用使用 因此大大减少创建新连接所耗费的资源。
2.减少对MySQL访问
硬件资源有限 无法扩充
避免对同一数据做重复检查
例子
select old,gender from users where userid =231;
select address from users where userid=231;
select old,gender,address from users where userid=231;
使用查询缓存
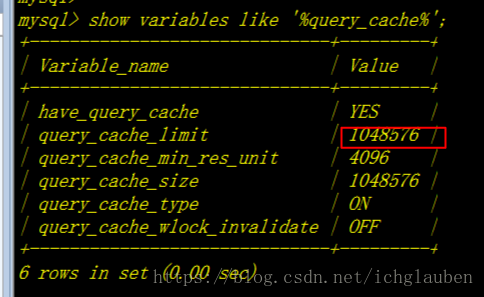

show variables like '%query_cache%';
have_query_cache:表明server在安装时是否配置了高速缓存
query_cache_size:缓存大小 MB
query_cache_type的变量从0-2 0 off(关闭) 1或者on(缓存打开 ) 2或者demand(只有带SQL_CACHE的select语句提供高速缓存)
增加CACHE层
在应用端增加cache层减轻数据库负担的目的 CACHE有很多种
把部分数据从数据库中抽取出来放到应用daunt文本方式存储 如果有查询 可以直接从这个CACHE中 检索
3.负载均衡 利用某种均衡算法 将固定的负载量分布到不同的server上 减轻单台服务器的负载 达到优化目的。用在系统中的各个层面 从前台的web服务器到中间层的应用服务器 最后到数据层的数据库服务器 都可使用。
利用复制分流查询操作
利用主从复制 有效分流更新操作和查询操作 具体实现是一个主服务器承担更新操作 多台服务器承担select操作 主从之间通过复制实现数据的同步 多台从服务器一方面用来确保可用性 一方面可用创建不同的索引以满足不同查询的需要
对于主从之间不需要复制全部表 可用通过在主服务器搭建一个虚拟的从服务器 将需要的表设置成BlackHole引擎 定义replicate-do-table参数只复制这些表 这样就过滤出需要复制的BINLOG 减少传输BINLOG的带宽 搭建的虚拟从服务器只起到过滤BINLOG的作用 没有实际记录数据
存在的问题:当主数据库上更新频繁或网络出现问题 主从之间数据可能存在比较大的延迟更新 从而造成查询结果和主数据库上有所差异。
采用分布式数据库架构
分布式数据库架构适合大数据量 负载高的情况 具有良好的扩展性和高可用性 通过多台服务器间分布数据 可以实现在多台服务器之间的负载均衡 提高访问的执行效率 具体实现 可以使用MySQL的CLUSTER功能 或者通过用户自己编写的程序来实现全局事务
注意:分布式事务只支持InnoDB存储引擎
4.其他优化操作
--1对于没有删除行操作的MyISAM表 插入操作和查询操作可以并行进行 因为没有删除操作的表查询期间不会阻塞插入操作 对于确实需要执行删除操作的表 尽量在空闲时间进行批量操作 并在进行删除后进行OPTIMIZE操作来消除由于删除操作带来的空洞 避免将来的更新操作阻塞其他操作
--2 利用列有默认 只有插入的值 不同于默认值 才能明确插入值 会减少MySQL需要做的语法分析从而提高插入速度
--3表的字段尽量不使用自增长变量 在高并发情况下 该字段的自增可能对效率有比较大的影响 推荐通过应用来实现字段的自增长