-- 1.MySQL 数据导入导出介绍
从外面导入大量的数据到数据库中,比如文本,表格,如何快速导入导出?
load data:加载数据
outfile:导出数据
mysqlimport:导入导出
使用mysql 里面导入导出,3 个注意事项:
01.需要数据库能够识别一个目录:
mkdir -p /mysql/dataload
chown mysql:mysql /mysql/dataload
就是在my.cnf 文件中加一个参数,需要重启mysql:
secure-file-priv=/mysql/dataload
02.同时还要开启my.cnf 自动数据提交,需要重启mysql:
autocommit=1
03.解决乱码的问题:
echo "export LANG=en_US.UTF8" >>~/.bash_profile
source ~/.bash_profile
04.如果是源码编译的mysql,需要在cmake 的时候,添加参数:-DENABLED_LOCAL_INFILE=1
-- 2.LOAD DATA INFILE 导入方法与案例
load data:加载数据,高速的方法
-- 2.1 load data 语法命令
load data [low_priority | concurrent] [local] infile 'file_name'
[replace | ignore]
into table tbl_name
[partition (partition_name,...)]
[character set charset_name]
[{fields | columns}
[terminated by 'string']
[[optionally] enclosed by 'char']
[escaped by 'char']
] [
lines
[starting by 'string']
[terminated by 'string']
] [
ignore number {
lines |
rows}]
[(col_name_or_user_var,...)]
[set col_name = expr,...]
-- 2.2 load data 数据加载参数说明
01.low_priority
如果指定这个参数,运行加载命令后,mysql 将会等别人没有读这个表的时候,才加载数据。
02.concurrent
只要满足条件,现在就加载数据。
03.local
表明从客户主机读文件,如果没有指定,则文件必须放在服务器上。
04.replace | ignore
replace:新行替换表里面唯一索引相同的行。
ignore:跳过有唯一索引的行,避免数据重复插入
如果不指定,就会报错。除非没有唯一索引,就会重复插入。
05.分隔符
1)fields
指定文件的分隔的格式
terminated by 'string',分隔符,是什么字符作为分隔符,比如: 1,2,3,默认情况用tab 键(\t)
enclosed by 'char',字段括起来的字符, 比如:"itpux01","itpux02"
escaped by 'char',转义字符,默认就是/
columns:指定哪些列,比如:表有9 列,文件只有3 列,那我要导入进哪些列
[{fields | columns}
[terminated by 'string']
[[optionally] enclosed by 'char']
[escaped by 'char']
2)lines
指定了每条记录的分隔符默认'\n'即为换行符
[lines
[starting by 'string'] 以什么开头
[terminated by 'string'] 以什么结尾,换行。
-- 2.3 load data 数据加载txt 文本使用案例
1.建表
use itpux;
create table itpux_member (
id int(20) not null auto_increment,
name varchar(60) not null,
age int (10) not null,
member varchar(60) not null,
primary key (id),
unique key idx_name(name)
) engine=innodb default charset utf8;
2.准备txt 文件(和表名一样),并上传到/mysql/dataload
itpux_member.txt
"itpux01","21","1 级会员"
"itpux02","22","2 级会员"
"itpux03","23","3 级会员"
"itpux04","24","4 级会员"
"itpux05","25","5 级会员"
"itpux06","26","6 级会员"
"itpux07","27","7 级会员"
"itpux08","28","8 级会员"
"itpux09","29","9 级会员"
"itpux10","30","特级会员"
3.准备load data 语句
load data infile '/mysql/dataload/itpux_member.txt' ignore into table itpux.itpux_member character set utf8 fields terminated by ',' enclosed by '"' lines terminated by '\n' (`name`,`age`,`member`);
` ~的注意
可以用文本文件替换","


4.验证数据
mysql> select * from itpux.itpux_member;
-- 2.4 load data 数据加载时增加一些时间列
先增加一个时间列
alter table itpux_member add update_time timestamp not null;
清空数据
select * from itpux_member;
truncate table itpux_member;
重新导入:
load data infile '/mysql/dataload/itpux_member.txt' ignore into table
itpux.itpux_member
character set utf8 fields terminated by ',' enclosed by '"' lines terminated
by '\n' (`name`,`age`,`member`) set update_time=current_timestamp;
测试:
mysql> select * from itpux.itpux_member;

-- 2.5 快速加载大量数据的优化方案1
场景:某些数据文本比较大,1 千万行数据,一个文件2G 左右。
这种情况导入的参数注意:
1.从文件大小上处理:
一个文件单线程导入比较慢,linux 有一个split 分离文件的命令,将文件切成100 万行一10个小文件,然后启动10 个线程,分别执行load data infile 语句。
split 使用方法:
-b 分离后的文件大小,byte
-C 单行最大的大小,byte
-d 分离后的文件以数字为后缀
-l 每一个文件存多少行
-a 后缀的名字长度
案例:
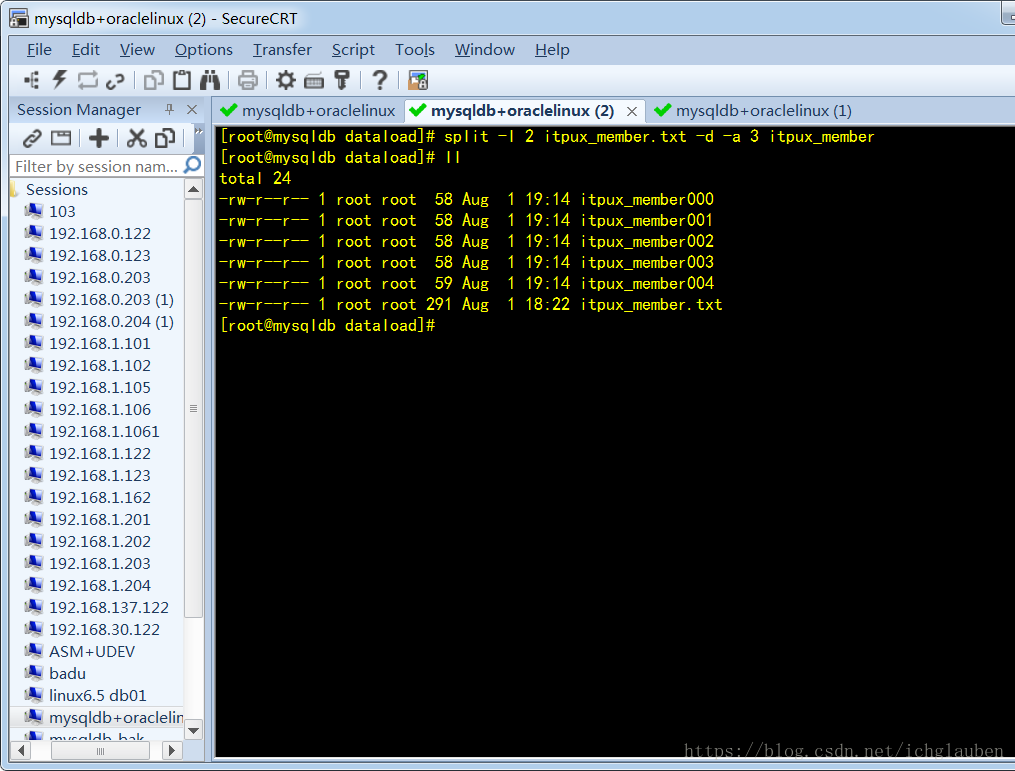
按行数:split -l 2 itpux_member.txt -d -a 3 itpux_member
按大小:split -b 10k itpux_member.txt -d -a 3 itpux_member
[root@itpuxdb dataload]# split -l 2 itpux_member.txt -d -a 3 itpux_member
[root@itpuxdb dataload]# ls -lsa
total 32
4 drwxr-xr-x 2 mysql mysql 4096 May 15 03:57 .
4 drwxr-xr-x. 7 mysql mysql 4096 May 14 23:08 ..
4 -rw-r--r-- 1 root root 56 May 15 03:57 itpux_member000
4 -rw-r--r-- 1 root root 56 May 15 03:57 itpux_member001
4 -rw-r--r-- 1 root root 56 May 15 03:57 itpux_member002
4 -rw-r--r-- 1 root root 56 May 15 03:57 itpux_member003
4 -rw-r--r-- 1 root root 57 May 15 03:57 itpux_member004
4 -rw-r--r-- 1 root root 281 May 15 03:36 itpux_member.txt
2.从数据库参数上处理
show variables like 'innodb_log_%';
innodb_file_per_table=1
innodb_flush_method=O_DIRECT
innodb_flush_log_at_trx_commit=0
innodb_buffer_pool_size=20000M
innodb_lock_wait_timeout=1000
innodb_log_file_size=2048M
innodb_log_buffer_size=2048M
-- 2.6 快速加载大量数据的优化方案2(改存储引擎)
场景:某些数据文本比较大,1 千万行数据,一个文件2G 左右。
01.主要是改表的存储引擎,导入的时候改为myisam,导入后再改回innodb,否则的话1000W可能导1 个小时。
02.导入前修改参数和禁止索引更新
show variables like '%BUFFER_SIZE%';
bulk_insert_buffer_size=256217728
myisam_sort_buffer_size=256217728
key_buffer_size=256217728
alter table 表名disable keys;
03.再导入数据
04.alter table 表名enable keys;
-- 3.SELECT INTO OUTFILE 导出方法与案例
-- 3.1 SELECT INTO OUTFILE 数据导出语法
-- 语法:
select ... into outfile 'file_name'
[character set charset_name]
[export_options]
export_options:
[{fields | columns}
[terminated by 'string']
[[optionally] enclosed by 'char']
[escaped by 'char']
] [
lines
[starting by 'string']
[terminated by 'string']
]
-- 3.2 outfile 数据导出txt 文件使用案例
方法1:
select * into outfile '/mysql/dataload/out01.txt' from itpux.itpux_member where id < 10;
方法2:
select * into outfile '/mysql/dataload/out02.txt' fields terminated by ',' enclosed by '"' lines terminated by '\n' from itpux.itpux_member;

[root@itpuxdb dataload]# cat out01.txt
1 itpux01 21 1 级会员2018-05-15 03:43:45
2 itpux02 22 2 级会员2018-05-15 03:43:45
3 itpux03 23 3 级会员2018-05-15 03:43:45
4 itpux04 24 4 级会员2018-05-15 03:43:45
5 itpux05 25 5 级会员2018-05-15 03:43:45
6 itpux06 26 6 级会员2018-05-15 03:43:45
7 itpux07 27 7 级会员2018-05-15 03:43:45
8 itpux08 28 8 级会员2018-05-15 03:43:45
9 itpux09 29 9 级会员2018-05-15 03:43:45
[root@itpuxdb dataload]# cat out02.txt
"1","itpux01","21","1 级会员","2018-05-15 03:43:45"
"2","itpux02","22","2 级会员","2018-05-15 03:43:45"
"3","itpux03","23","3 级会员","2018-05-15 03:43:45"
"4","itpux04","24","4 级会员","2018-05-15 03:43:45"
"5","itpux05","25","5 级会员","2018-05-15 03:43:45"
"6","itpux06","26","6 级会员","2018-05-15 03:43:45"
"7","itpux07","27","7 级会员","2018-05-15 03:43:45"
"8","itpux08","28","8 级会员","2018-05-15 03:43:45"
"9","itpux09","29","9 级会员","2018-05-15 03:43:45"
"10","itpux10","30","特级会员","2018-05-15 03:43:45"

-- 4.mysql 导入导出csv 表格的案例
-- 4.1 mysql 导入csv 表格到数据库中
01.创建帐单表
use itpux;
create table itpux_zd (
id int(100) not null,
name varchar(30) not null,
date datetime not null,
expend int(100) not null,
income int(100) not null,
store varchar(30) not null,
primary key (id)
) engine=innodb default charset utf8;
02.准备表格itpuxzd.csv(把excel 保存为csv 格式)
把itpuxzd.csv 文件上传到/mysql/dataload 目录,文件名要用.csv,建议用utf8 格式,
文件名不能用中文
流水ID 姓名日期支出收入商家
1234567891itpux01 2017/7/14 21:12:00 2345 0 淘宝
1234567892itpux02 2017/7/15 21:12:00 2346 0 天猫
1234567893itpux03 2017/7/16 21:12:00 2347 0 京东
1234567894itpux04 2017/7/17 21:12:00 2348 0 淘宝
1234567895itpux05 2017/7/18 21:12:00 2349 0 天猫
1234567896itpux06 2017/7/19 21:12:00 2350 0 京东
1234567897itpux07 2017/7/20 21:12:00 2351 0 淘宝
1234567898itpux08 2017/7/21 21:12:00 2352 0 天猫
1234567899itpux09 2017/7/22 21:12:00 2353 0 京东
准备load data 语句,上传
load data infile '/mysql/dataload/itpuxzd.csv' into table itpux.itpux_zd character set utf8 fields terminated by ',' enclosed by '"' ignore 1 lines (id,name,date,expend,income,store);
如果报错,肯定是字符集有问题:
ERROR 1300 (HY000): Invalid utf8 character string: ''
以源字符集导入就能解决问题:
load data infile '/mysql/dataload/itpuxzd.csv' into table itpux.itpux_zd character set GBK fields terminated by ',' enclosed by '"' ignore 1 lines
(id,name,date,expend,income,store);
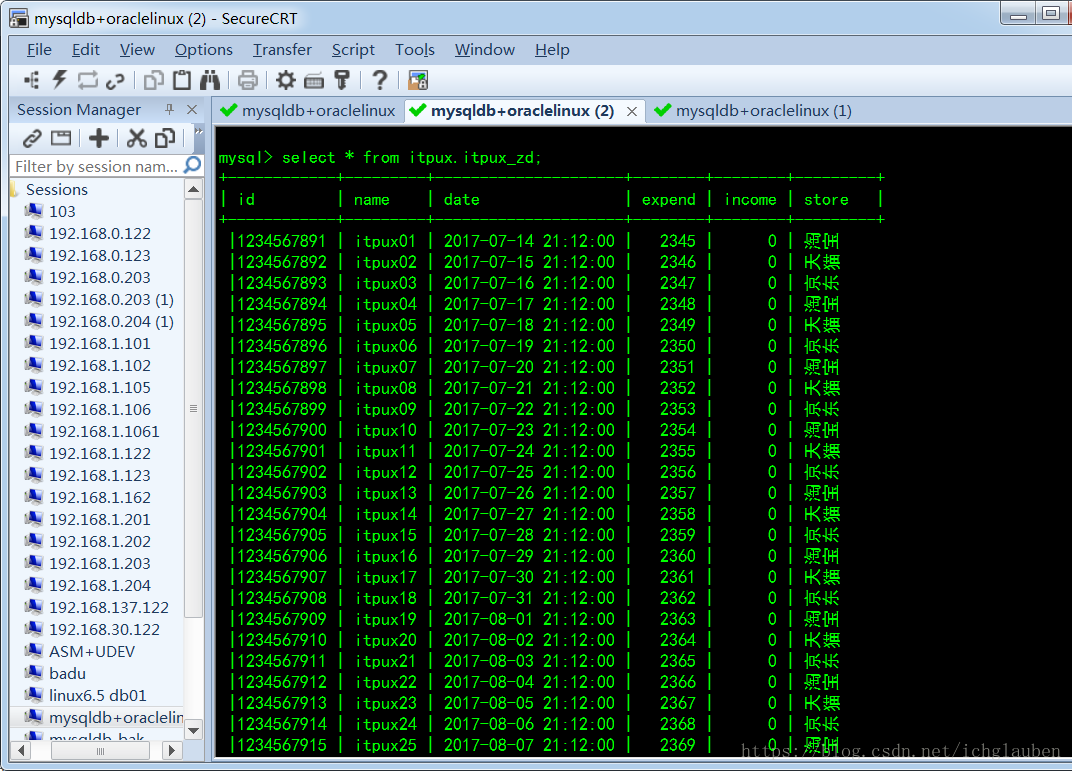
验证数据:
mysql> select * from itpux.itpux_zd;
-- 4.2 mysql 从表中导出csv 表格
select * into outfile '/mysql/dataload/itpuxzd_out.csv' fields terminated by ',' optionally enclosed by '"' escaped by '"' lines terminated by '\n' from itpux.itpux_zd;
-- 5.mysqlimport 导入数据的方法与案例
mysqlimport 工具,跟load data 一样的功能。从文本/表格里面导入到数据库中,两个方法
不参数差不多。
由select into outfile 导出,可以由mysqlimport/load data 导入。
https://dev.mysql.com/doc/refman/8.0/en/mysqlimport.html
语法:
mysqlimport -uroot -ppassword dbname filename.txt [option]
--local:指定的话就从当前主机上找文件,不指定就从服务器上找文件
--fields-enclosed-by:设置字符来把字段的值括起来'"'
--fields-escaped-by: 转义符
--fields-optionally-enclosed-by:设置字符括住char,varchar,text 这些字符型字段。
--fields-terminated-by:分隔符','
--lines-terminated-by: 每行数据结尾的字符
--ignore-lines:忽略多少行
--ignore:如果有相同的数据,针对唯一索引的忽略,不用插入重复的数据
--replace:如果有相同的数据,针对唯一索引的先替换再插入,不用插入重复的数据
--columns:针对导入表的列
-- 5.2 mysqlimport 导入txt 文本数据的案例
1.建表
use itpux;
drop table itpux_member;
create table itpux_member (
id int(20) not null auto_increment,
name varchar(60) not null,
age int (10) not null,
member varchar(60) not null,
primary key (id),
unique key idx_name(name)
) engine=innodb default charset utf8;
2.准备txt 文件(和表名一样),并上传到/mysql/dataload
itpux_member.txt
"itpux01","21","1 级会员"
"itpux02","22","2 级会员"
"itpux03","23","3 级会员"
"itpux04","24","4 级会员"
"itpux05","25","5 级会员"
"itpux06","26","6 级会员"
"itpux07","27","7 级会员"
"itpux08","28","8 级会员"
"itpux09","29","9 级会员"
"itpux10","30","特级会员"
3.mysqlimport
mysqlimport -uroot -proot itpux /mysql/dataload/itpux_member.txt --fields-terminated-by=',' --fields-enclosed-by='"' --lines-terminated-by='\n' --columns=name,age,member
-- 备注:文件名一定要和表名一样

-- 5.3 mysqlimport 导入csv 表格数据的案例
01.创建帐单表
use itpux;
drop table itpux_zd
create table itpux_zd (
id int(100) not null,
name varchar(30) not null,
date datetime not null,
expend int(100) not null,
income int(100) not null,
store varchar(30) not null,
primary key (id)
) engine=innodb default charset utf8;
02.准备表格itpux_zd.csv(把excel 保存为csv 格式)把itpuxzd.csv 文件上传到/mysql/dataload 目录,文件名要用.csv,建议用utf8 格式,
文件名不能用中文
流水ID 姓名日期支出收入商家
1234567891itpux01 2017/7/14 21:12:00 2345 0 淘宝
1234567892itpux02 2017/7/15 21:12:00 2346 0 天猫
1234567893itpux03 2017/7/16 21:12:00 2347 0 京东
1234567894itpux04 2017/7/17 21:12:00 2348 0 淘宝
1234567895itpux05 2017/7/18 21:12:00 2349 0 天猫
1234567896itpux06 2017/7/19 21:12:00 2350 0 京东
1234567897itpux07 2017/7/20 21:12:00 2351 0 淘宝
1234567898itpux08 2017/7/21 21:12:00 2352 0 天猫
1234567899itpux09 2017/7/22 21:12:00 2353 0 京东
3.mysqlimport
以源字符集导入就能解决问题:
[root@mysqldb dataload]# cp itpuxzd_out.csv itpux_zd.csv
mysqlimport -uroot -proot itpux /mysql/dataload/itpux_zd.csv --fields-terminated-by=',' --fields-enclosed-by='"' --ignore-lines=1 --columns=id,name,date,expend,income,store --default-character-set=gbk
or:
mysqlimport -uroot -proot itpux /mysql/dataload/itpux_zd.csv --fields-terminated-by=',' --fields-enclosed-by='"' --columns=id,name,date,expend,income,store --default-character-set=utf8
-- 备注:文件名一定要和表名一样
保存cvs-工具-web选项-编码-utf8 保存

--出现这个问题 说明表里面有重复的数据 需要truncate表 将其导入
--6.第三方工具导入导出案例
truncate table itpux.itpux_zd;