前言:
这个系列我分四个部分来分别接触四块知识,最后再串起来:
Java爬虫入门(一)——项目介绍
Java爬虫入门(二)——HttpClient请求
Java爬虫入门(三)——正则表达式
Java爬虫入门(四)——线程池和连接池
Java爬虫入门(五)——缓冲流写入
GitHub地址:
https://github.com/jjc123/Java-Crawler/blob/master/README.md简而言之,这一块内容可以直接Google ,网上资料很多,我就不在这里多累赘了
线程池:
总结:
这次项目中线程池的目的是:
1. A线程池多并发爬取小说网站的小说链接,
加入到另一个线程池(实现分页爬取整个网站)
2. 多并发爬取获取到的小说简单来说:
页面层面获取小说是多并发,
小说下载是多并发,
小说内容的章节下载是单线程。
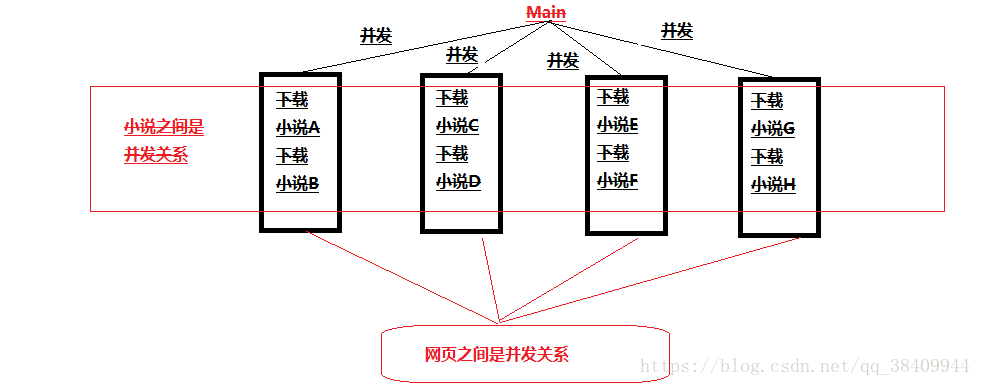
看图理解下,不知道我的表述是否完整。
注意:这里线程要继承 Runnable接口。
因为线程池加入需要的是 Runnable接口而不是Thread
默认当你加入线程池的时候 就不需要启动了,不像Thread需要Thread.start()自己启动。
还有线程的join()可以了解下:
将该线程加入到所在线程,只有该线程执行完毕后 所在线程才可以继续执行。
我是使用newFixedThreadPool创建固定的100个线程。
ExecutorService executorServiceBook =
Executors.newFixedThreadPool(100);核心代码:
添加线程到线程池:
executorServiceBook .execute
(new AddBookUrlThread(url));等待线程池中的线程全部执行完毕退出:
//等待加入线程全部执行完毕
executorServiceBook .shutdown();
//awaitTermination限制每10秒循环一次检查是否全部结束,
while (!executorServicePage.awaitTermination
(5, TimeUnit.SECONDS));
//如果线程全部结束isTerminated则为true
boolean PageEnd = executorServicePage.isTerminated();
if(PageEnd) {
System.out.println("获取小说书名信息和链接成功!");
} 连接池:
为什么使用连接池呢?
因为多并发 访问一个网站,意思就是同一段时间内发送了过多的请求访问网站,如果并发数过大,就需要创建连接池。
这里我也不累赘了,具体的可以网上搜资料。
核心代码:
创造连接池:
public static CloseableHttpClient httpClient = null;
PoolingHttpClientConnectionManager cm1 = new PoolingHttpClientConnectionManager();
cm1.setMaxTotal(200);// 设置最大连接数
cm1.setDefaultMaxPerRoute(200);// 对每个指定连接的服务器(指定的ip)可以创建并发20 socket进行访问
httpClient = HttpClients.custom().setRetryHandler(new DefaultHttpRequestRetryHandler())// 设置请求超时后重试次数
.setConnectionManager(cm1).build();注意:
这里的连接池 跟线程池不一样 ,不需要关闭