Spark特点:
- 大数据分布式计算框架,内存计算
- 分布式计算
- 内存计算 中间结果在内存 迭代
- 容错性
- 多计算范式
Spark SQL:Sql on hadoop系统,提供交互式查询、能够利用传统的可视化工具
在Spark上进行类似SQL的查询操作,报表查询等功能
GraphX:图计算引擎,大规模图运算,pagerank
MLlib:聚类分类 分类 推荐 等机器学习算法

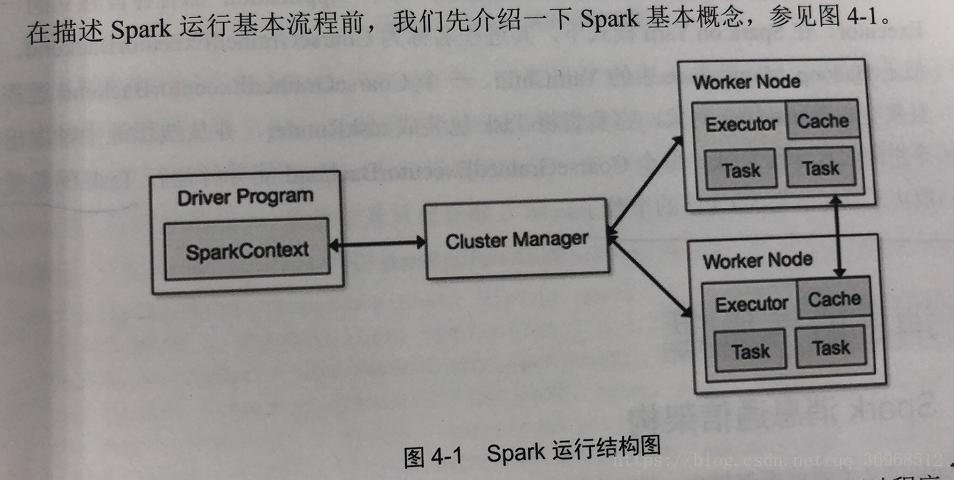
*Application(应用程序)
就是你自己的编写的程序代码,其中包含了驱动(Driver)部分和执行部分(Executor)这俩部分,注意!!一个spark集群可以同时有很多Application*Driver(驱动程序)
就是上一个概念的里的Application的mian函数(一定要有SparkContext),其中SC是为了准备程序的运行环境(主要与ClusterManager通信),进行资源的调度分配以及监控等。(Ps:一般的SparkContext就是代表Driver)。
*Worker(工作节点)
这个这是开始配置的slaves文件机器,是master的小弟,它里面放的是Executor
*Executor(执行进程)
Application就是运行在Worker节点的进程,这个进程负责运行Task,并且将数据存在内存或者磁盘上,在后面spark on yarn 进程名字是CoarGraineExecutorBackend,说白了就是真正执行的时候是在这个上面运行,然后将结果返回到写Application的机器上。
*Cluster Manager
根据字面理解就是资源管理器,一般的我们初学都是使用standalone就是spark的原生管理,还有hadoop yarn以后会用到,Mesos等资源管理器
************************介绍一个小白自己发现的细节(大佬忽略!!!)********************************
我在自己学习的时候有个时候文件比较大800M左右,最后我把它打印了,然后就报错了!!! ,后来了解到我们远程提交的job,集群会在结束之后看我们要不要求查看结果,如果你最就是是要求查看,输出数据量太大,内存容易爆掉!!如果以后开发输出结果一般很大我们应该避免使用直接打印结果,我们应该养成将计算结果持久化在硬盘上的好习惯
,后来了解到我们远程提交的job,集群会在结束之后看我们要不要求查看结果,如果你最就是是要求查看,输出数据量太大,内存容易爆掉!!如果以后开发输出结果一般很大我们应该避免使用直接打印结果,我们应该养成将计算结果持久化在硬盘上的好习惯