1.什么是网络流?
在一个有向图上选择一个源点,一个汇点,每一条边上都有一个流量上限(以下称为容量),即经过这条边的流量不能超过这个上界,同时,除源点和汇点外,所有点的入流和出流都相等,而源点只有流出的流,汇点只有汇入的流。这样的图叫做网络流。
就好比你家是汇点,自来水厂是源点.自来水厂通过许多的水管将水导入你家,水管的大小不一,所以口径不同最大流量(容量)也不同,虽然有的水管口径很大,但并不能一次性通过很多的水,这要受限于直接或间接连接他的上游水管的口径大小。你家能接多少水不受限于水厂而是这些水管,换句话说,水厂的出水量是∞的。
容量:相当于水管最多能通过多少水
流量:相当于水管实际能通过多少水
残量:容量-流量,就是还有多少没用。
虽然很明显但是不得不说:流入水管多少水,自然流出也是多少。
增广路径:找到一条从源点到汇点的路径,使得路径上任意一条边的残量>0。
如果找不到增广路径说明已经求出最大流了。打实
证明:如果该路径存在至少一条残量==0的边,说明这个水管已经满流,不能通过更多的水了。
dinic算法增广过程:
1.找到这条路径上最小的f[u][v](我们设f[u][v]表示u->v这条边上的残量即剩余流量),下面记为flow
2.将这条路径上的每一条有向边u->v的残量减去flow,同时对于起反向边v->u的残量加上flow(下面再讲反向边)
3.重复上述过程,直到找不出增广路.
最大流:相当于你家一次最多能接多少水。
最小割:如果说割掉一根水管的花费和他的口径是一样的,那么就要求花掉最少的钱让你家断水的花费。
在已经没有残量网络中,容量大于0表示可以走。 将从源点出发可以到达的点看作S集,剩下的看作T集。如果边(u,v)满足u属于S集,v属于T集,那么该边就是最小割边集中的边。
反向边的意义:
实际例子中(好比开头的水管例子)是不可能有逆流这种说法(即反向边).那么在网络流中的反向边实际上是一种拆分,等价于实际流向中的几个路径,也就是一条有反向边参与的路径实际是有几条没有反向边的实际路径可以相互等价的。它的意义是提供我们反悔的机会。好比一条路径上原本计划流6的水,但是发现这样不是最优的,要把它变少,这时就要用到反向边。看下图我们来分析一波:
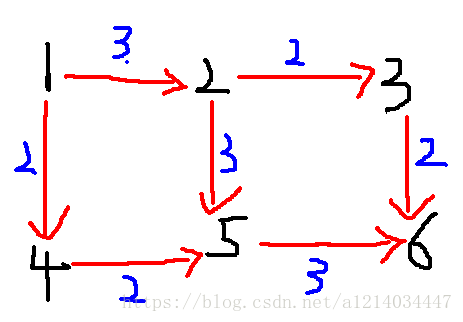
源点S = 1,汇点T = 6很明显我们知道此图的最大流5.分别由1->2->5->6(流量1),1->2->3->6(流量2),1->4->5->6(流量2)。为什么1->2->5->6不是最大流量3呢?我们来解析一下步骤,假设一开始先走1->2->5->6...①取最大流量3,那次此时正向边已经无路可走了,根据建立反向边的原则,此时有5->2边值为3的边,那么就可以有1->4->5->2->3->6...②流量值为2加起来刚好是5.我们知道实际是不存在这样的流的.一个很重要的现象就是反向边如果是正值,那么说明他的正向边已经参与了一条路径的流量。现在这条反向边又参与了一条路径的流就等价于将反向边参与的路径关于正向边拆开。由①可知源点可以到达2,由②知2可以到达汇点6,所以一定有1->2->3->6,同理也有1->4->5->6都是由2->5这条边的推出的。这两条路径流量等于②的流量,相当于1->2原来在①中参与了3现在退出2参与在1->2->3->6中,5->6退出2参与在1->4->5->6,所以原来的1->2->5->6只剩1了,就变成原先的三条路径。
总结:由反向边参与的路径一定可以等价于由此正向边之前参与的路径分成几个部分变成多条实际的路径。而此正向边并不参与其中,只是路径的拆分。所以反向边的意义实际就是等价关系,等价于实际正向边路径,这样就可以达成"反悔"的功能
dinic算法分层概念:
将原有向图dfs一遍残量不为0的边才可以走,顶点可以得到相应的dfs序号。那么在增广的时候u->v边必须满足dep[u]+1==dep[v]才可以走,dep就是他们的深度。
意义:为了防止在一条边上"反复反悔"(就是正向反向老是交替参与路径流)而降低效率,假设v->u是反向边,他参与了一条路径的流,那么最开始的dfs序dep[v]+1一定不等dep[u],简单的说就是将不需要"反悔"的路径先走完,再去考虑反向边的情况。这样就可以避免"反复反悔"的情况。
dinic算法优化:
int dfs(int x,int flow)
{
if(x==T || !flow) return flow;
int used = 0;
for(int& i=cur[x];~i;i=edge[i].nxt)
{
int y = edge[i].y;
if(dep[x]+1==dep[y]){
int w = dfs(y,min(flow-used,edge[i].v));
edge[i].v -= w;
edge[i^1].v += w;
used += w;
if(used==flow) return flow;
}
}
return used;
}
int maxflow()
{
int ans = 0;
while(bfs()){
copy(head,head+mx,cur);
ans += dfs(S,inf);
}
return ans;
}if(used==flow) return flow;那么已经参与的这些边之后就不用再考虑了,用引用随之去掉。
最后附上完整最大流代码:
#include<bits/stdc++.h>
#define inf 0x3f3f3f3f
using namespace std;
typedef long long ll;
const int mx = 1e3 + 10;
int n,m,S,T,tot,head[mx],cur[mx];
struct node
{
int y,v;
int nxt;
}edge[mx<<1];
void AddEdge(int x,int y,int v)
{
edge[tot].y = y;
edge[tot].v = v;
edge[tot].nxt = head[x];
head[x] = tot++;
}
int dep[mx];
bool bfs()
{
memset(dep,0,sizeof(dep));
queue<int> que;
que.push(S);
dep[S] = 1;
while(!que.empty())
{
int no = que.front();
que.pop();
for(int i=head[no];~i;i=edge[i].nxt)
{
int y = edge[i].y;
if(edge[i].v&&!dep[y]){
dep[y] = dep[no] + 1;
que.push(y);
}
}
}
return dep[T];
}
int dfs(int x,int flow)
{
if(x==T || !flow) return flow;
int used = 0;
for(int& i=cur[x];~i;i=edge[i].nxt)
{
int y = edge[i].y;
if(dep[x]+1==dep[y]){
int w = dfs(y,min(flow-used,edge[i].v));
edge[i].v -= w;
edge[i^1].v += w;
used += w;
if(used==flow) return flow;
}
}
//if(!used) dep[x] = 0;
return used;
}
int maxflow()
{
int ans = 0;
while(bfs()){
copy(head,head+mx,cur);
ans += dfs(S,inf);
}
return ans;
}
int main()
{
int t;
scanf("%d",&t);
while(t--){
scanf("%d%d",&n,&m);
scanf("%d%d",&S,&T);
int a,b,c;
tot = 0;
memset(head,-1,sizeof(head));
for(int i=1;i<=m;i++){
scanf("%d%d%d",&a,&b,&c);
AddEdge(a,b,c*(m+1)+1);
AddEdge(b,a,0);
}
int ans = maxflow()%(m+1);
printf("%d\n",ans);
}
return 0;
}