一,面向对象与面向过程
1.1,面向对象与面向过程的区别
面向过程:面向过程是一件事“该怎么做”,是分析解决问题的步骤,然后用函数把这些步骤一步一步的实现,然后在使用的时候一一调用则可。
面向对象:面向对象是一件事“该谁来做”,然后那个“谁”就是对象。是以对象为核心,关注需要哪些对象,对象需要具备哪些功能,然后创建出解决问题的对象,利用对象调用相应的方法即可。采用OOP方法时,首先从用户的角度考虑对象,描述对象所需的数据以及描述用户与数据交互所需的操作。完成对接口的描述后,需要确定如何实现接口及存储数据。
1.2,面向过程的优缺点
优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源。比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
缺点:没有面向对象易维护、易复用、易扩展。
1.3,面向对象的优缺点
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出高内聚低耦合的系统,使系统更加灵活、更加易于维护。
缺点:性能比面向过程低。
1.4,面向对象的精髓
面向对象的精髓在于封装,面向对象要求数据应该尽可能被封装,越多的东西被封装,就越少的人可以看到他,而越少的人可以看到他,我们就有越大的弹性去改变他。因此,越多的东西被封装,我们改变那些东西的能力就越大。这就是我们推崇封装的原因,他使我们改变事物而只影响有限客户。
二,面向对象五大原则
2.1,理解设计原则与设计模式
软件设计原则:原则为我们提供指南,它告诉我们什么是对的,什么是错的。它不会告诉我们如何解决问题。它仅仅给出一些准则,以便我们可以设计好的软件,避免不良的设计。
软件设计模式:模式是在软件开发过程中总结得出的一些可重用的解决方案,它能解决一些实际的问题。一些常见的模式,比如工厂模式、单例模式等等。
封装、继承、多态只是类的三大特性,在程序设计时并不是说使用到了这三个特性就是面向对象,真正的面向对象的设计要满足下面五个原则。
2.2,单一功能原则
原理:单一职责原则可以看作是低耦合、高内聚在面向对象原则上的引申,将功能定义为引起变化的原因,功能过多可能引起它变化的原因就越多,这将导致功能依赖,相互之间就产生影响,从而极大的损伤其内聚性和耦合度。因此不要为类实现过多的功能,以保证一个类只有一个引起它变化的原因。
实例:做一个数据库管理系统,根据不同的权限对数据库进行数据删改查的操作,下面是一个很low的设计。
class DBManager{
private:
string userId;
public:
DBManager(const string &str):userId(str){}
void add(){
if(userId == "chongchong"){
//执行往数据库里添加数据的操作
}
}
};程序分析
上面这个是很low的设计,如果验证用户权限的规则或数据库的操作发生改变,那就必须对DBManager类进行修改。权限判断的功能和数据库操作的功能被放在一个类中。我们可以使用Proxy模式,来实现功能的分离,下面这个是比较高大上的设计。
class Protocal{
public:
virtual void add();
};
class DBManager : public Protocal{
private:
string userId;
public:
DBManager(const string &str):userId(str){}
void add(){
//添加一条记录到数据库中
}
};
class Proxy : public Protocal{
private:
DBManager &manager;
public:
Proxy(const DBManager &db):manager(db){}
void add(){
//先对用户的权限进行验证,然后再执行往数据库添加数据的操作
manager.add();
}
};
int main() {
DBManager manager("123456");
Proxy delegate(manager);
delegate.add();
return 0;
}程序分析
使用代理模式,实现权限判断与数据库操作功能的分离。DBManager类实现数据库操作,代理Proxy类里面进行权限判断。
2.3,开放封闭原则
原理:对扩展是开放的,对修改是封闭的。开放封闭原则主要体现在下面两个方面,一是:对扩展开放意味着,软件有新的需求或变化时,可以对现有的代码进行扩展,以满足新的需求。二是:对修改封闭意味着,类一旦设计完成,就不要对类进行任何的修改。“需求总是变化”、“世界上没有一个软件是不变的”,这些言论是对软件需求最经典的表白。对于软件设计者来说,必须在不需要对原有的系统进行修改的情况下,实现灵活的系统扩展。而如何能做到这一点呢? 要面向接口编程,而不是面向实现编程。实现开放封闭的核心思想就是对抽象编程,而不对具体编程,因为抽象相对稳定。让类依赖于固定的抽象,所以对修改就是封闭的;而通过面向对象的继承和对多态机制,通过接口可以派生出新的类,实现新功能的扩展,所以对于扩展就是开放的,这是实施开放封闭原则的基本思路。
实例:我们要设计一款射击游戏,在这个游戏中会出现不同的人物角色以及不同的枪支,人物与枪支是最容易扩展的部分,我们把他们隔离开来,形成统一的接口处理。具体的人物角色与枪支都是依赖于这些接口,此时对接口的修改就是封闭的,而通过继承从抽象类派生出新的类,就是对扩展的开放。下面就是类的设计
class Gun{
public:
virtual void kill();
};
class MachineGun : public Gun{
public:
void kill(){
cout<<"MachineGun."<<endl;
}
};
class Character{
public:
virtual void shoot(){}
};
class BadGuy : public Character{
private:
Gun &weapon;
public:
BadGuy(Gun &gun):weapon(gun){}
void shoot(){
cout<<"BadGuy use ";
weapon.kill();
}
};
int main() {
MachineGun machineGun;
BadGuy badGuy(machineGun);
badGuy.shoot();
return 0;
}输出结果
BadGuy use MachineGun.
Process returned 0 (0x0) execution time : 0.006 s
Press any key to continue.程序分析
所有的具体类都是依赖于接口,具体类之间没有耦合在一起。例如:所有的Character的派生类,都是与接口Gun耦合在一起,都使用的是接口中提供的方法。
2.4,替换原则
原理:子类应当可以替换父类,并能出现在父类能出现的任何位置上,主要就是继承的体现。继承是一项非常优秀的语言机制,它可以提高代码复用性与代码的可扩展性。这个原则的核心思想就是,良好的继承定义了一个规范。
实例: CS是一款经典的射击游戏,我们描述一下里面枪类的实现。
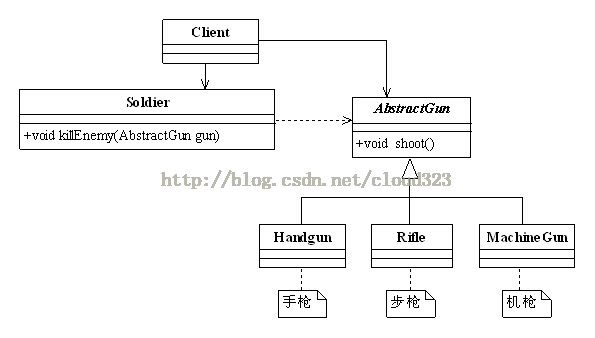
2.5,依赖倒转原则
原理: 抽象不能依赖于具体,具体应该依赖于抽象。就是要面向接口编程,而不是面向实现编程。
实例:假设我们现在要做一个电商系统,会遇到这样一个问题:订单入库。假设系统设计初期,用的是SQL Server数据库。通常我们会定义一个SqlServer类,用于数据库的读写。
class SqlServer{
public:
void add(){
cout<<"往数据库添加一个订单."<<endl;
}
};然后我们定义一个Order类,负责订单的逻辑处理。由于订单要入库,需要依赖于数据库的操作。因此在Order类中,我们需要定义SqlServer类的变量并初始化。
class Order{
private:
SqlServer *p;
public:
Order(){
p = new SqlServer;
}
void add(){
//先进行订单的逻辑处理,再把这个订单放到数据库
p->add();
}
};定义上面两个类很容易实现我们想要的功能,但是可能有一天,我们不想使用SQL Server数据库,要使用Oracle数据库,那么我们要重新写一个OracleServer类,然后对Order类进行修改。如果我们的底层数据库换成Mysql,又要进行类似的操作,所以我们做的系统的扩展性不强。主要的原因有两个,一是:Order直接依赖于一个具体的类,二是:Order依赖的对象的创建与绑定是在它的内部实现的。高层模块Order类不应该依赖于低层模块SqlServer,两者应该依赖于抽象。我们可以使用IoC(控制反转)来解决上面的问题。IoC有2种常见的实现方式:依赖注入和服务定位。其中,依赖注入是使用最为广泛,下面我们将深入理解依赖注入(DI)。
2.5.1,依赖注入(DI)
控制反转(IoC)一种重要的方式,就是将依赖对象的创建和绑定转移到被依赖对象类的外部来实现。在上述的实例中,Order类所依赖的对象SqlServer的创建和绑定是在Order类内部进行的。事实证明,这种方法并不可取。既然,不能在Order类内部直接绑定依赖关系,那么如何将SqlServer对象的引用传递给Order类使用呢?依赖注入(DI),它提供一种机制,将需要依赖(低层模块)对象的引用传递给被依赖(高层模块)对象。通过DI,我们可以在Order类的外部将SqlServer对象的引用传递给Order类对象。那么具体是如何实现呢?
使用构造函数来实现注入
构造函数函数注入,毫无疑问通过构造函数传递依赖。因此,构造函数的参数必然用来接收一个依赖对象。那么参数的类型是什么呢?具体依赖对象的类型?还是一个抽象类型?根据DIP原则,我们知道高层模块不应该依赖于低层模块,两者应该依赖于抽象。那么构造函数的参数应该是一个抽象类型。首选,我们需要定义SqlServer的抽象类型DataAccess。
class DataAccess{
public:
virtual void add(){}
} ;
class SqlServer : public DataAccess{
public:
void add(){
cout<<"往 SQL 数据库添加一个订单."<<endl;
}
};
class Oracle : public DataAccess{
public:
void add(){
cout<<"往 Oracle 数据库添加一个订单."<<endl;
}
};修改Order类
class Order{
private:
DataAccess &re;
public:
Order(DataAccess &re):re(re){}
void add(){
//先进行订单的逻辑处理,再把这个订单放到数据库
re.add();
}
};下面是main函数
int main() {
SqlServer sql; //在外部创建依赖对象
Order order1(sql); //通过构造函数注入依赖
order1.add();
Oracle oracle; //在外部创建依赖对象
Order order2(oracle); //通过构造函数注入依赖
order2.add();
return 0;
}输出结果
往 SQL 数据库添加一个订单.
往 Oracle 数据库添加一个订单.
Process returned 0 (0x0) execution time : 0.009 s
Press any key to continue.程序分析
显然,我们不需要修改Order类的代码,就完成了Oracle数据库的移植,这无疑体现了IoC的精妙。
2.6,接口分离原则
原理:使用多个专门的接口,而不使用单一的总接口,即类不应该依赖那些它不需要的接口。
class Worker{
public:
virtual void eat();
virtual void work();
};现在有两个类实现了这个接口,一是Manager,另一个是ChengXuYuan,下面是这两个类的实现
class Manager : public Worker{
public:
void eat(){
cout<<"Manager eat."<<endl;
}
void work(){
cout<<"Manager work."<<endl;
}
};
class ChengXuYuan : public Worker{
public:
void eat(){
cout<<"ChengXuYuan eat."<<endl;
}
void work(){
cout<<"ChengXuYuan work."<<endl;
}
};那我们现在引入一个Robot,来实现上面的Worker接口,work行为对机器人来说是可以接受的,但是eat行为对机器人来说,就非常的不合理。如果我们直接让Robot实现Worker接口,此时的Robot就被迫使用它用不到的接口,当接口Worker发生变化时,它同样也要跟着改变。我们使用适配器模式解决上面的问题,下面是代码
class EatAdapter : public Worker{
void eat();
};
class WorkAdapter : public Worker{
void work();
};使用适配器模式,把一个大的接口,分成几个小的接口。
三,类基础知识
3.1,抽象与类
生活中充满复杂性,处理复杂性的方法之一是简化与抽象。抽象就是将问题的本质提取出来,并根据特征来描述问题。C++中的类是一种将类转化为用户定义类型的C++工具,它将数据表示与操作数据的方法合成一个完整的包。类是对象的抽象,对象是类的具体化。
3.2,访问控制
C++提供了三个关键字public、private、protected,它们描述了对类成员的访问控制。
- private:只能由该类中的函数或其友元函数访问。在类外不能访问,该类的对象也不能访问。
- protected:可以被该类中的函数、子类的函数或其友元函数访问。在类外不能访问,该类的对象也不能访问。
- public:可以被该类中的函数、子类的函数或其友元函数访问,也可以由该类的对象访问。
3.3,结构体与类之间的区别
实际上,C++对结构体进行了扩展,使之具有与类相同的特征。它们之间的唯一的区别就是,结构的默认访问类型是public,而类的默认访问类型是private。C++程序员通常使用类来实现类描述,而把结构限制为只表示纯粹的数据对象。
3.4,构造函数
下面提供了一个类的定义:
class Person{
private:
string name;
int age;
public:
Person();
Person(const string &name, int age);
~Person();
};构造函数语法:
构造函数名与类名相同,并且没有返回值,可以进行重载。
构造函数作用:
创建类对象并对类对象的非静态数据成员进行初始化。
注意事项:
1,无法使用对象来调用构造函数,因为在构造函数构造出对象之前对象是不存在的。因此,构造函数被用来创建对象,而不能通过对象来调用。
2,如果没有提供任何构造函数,C++将提供默认的构造函数。它是默认构造函数的隐式版本,不做任何工作。如果为类提供了构造函数,此时编译器不会生成默认的构造函数。因此,为类定义了构造函数,就要为它提供默认的构造函数。
3,调用默认构造函数,不能使用圆括号。
Person zhangsan(); //定义了一个返回值类型为Person的方法
Person lisi; //调用默认的构造函数
4,成员初始化列表只能应用于构造函数。
3.5,析构函数
析构函数语法:
在类名前加~,没有返回值,也没有参数。
析构函数作用:
当一个对象的生命周期结束时,程序会自动的调用一个特殊的成员函数–析构函数,来完成一些清理工作。如果程序员没有提供析构函数,编译器将隐式地声明一个默认的析构函数。
3.6,this指针
3.6.1,什么是this指针?
this是指向实例化对象的一个指针,里面存储的是对象的地址,通过this可以访问内部的非静态成员变量与方法。每个非静态成员函数都有一个this指针(包括构造函数与析构函数),this指向调用对象。
3.6.2,this指针的作用
this的作用域是在类的内部,声明类时还不知道实例化对象的名字,所以使用this来使用对象。this指针指向用来调用成员函数的对象,在调用对象的非静态函数时,this作为隐藏的参数传给该方法。
obj.fun(1); 等价于 obj.fun(&obj, 1);3.6.3,在什么地方使用this指针
- 在类的非静态成员函数中返回对象本身时,直接使用return *this。(常用于运算符重载、赋值构造函数、拷贝构造函数)。
- 函数的形参名与成员变量名相同时。
Person::Person(const string &name, int age){
this->name = name;
this->age = age;
}3.7,类作用域
在C++中引入了一种新的作用域即类作用域。在类中定义的名称的作用域(成员函数与数据成员)都为整个类,作用域为类的名称在类中是可见的,但是在类的外面是不可见的。因此,可以在不同的类中使用相同的名称,而不会引起冲突。类作用域意味着不能从类的外面直接访问类成员,公有的成员函数也是如此。也就是说,要调用公有的成员函数,必须通过类对象。同样,在定义成员函数时,必须使用作用域解析运算符。
3.7.1,声明作用域为类的常量
下面的声明方式是错误的:
class Person{
private:
const int Months = 12;
double cost[Months];
string name;
int age;上面的做法是错误的,类声明只是描述了对象的形式,并没有创建对象。因此,将没有用于存储的空间。C++11提供了成员初始化,但是不适用于前面的数组声明。可以使用下面2种方式实现这个目标,效果相同。
方法一:在类中声明一个枚举
在类声明中声明的枚举的作用域为整个类,因此可以用枚举为整型常量提供作用域为整个类的符号名称。
class Person{
private:
enum {Months = 12};
double cost[Months];
string name;
int age;使用上面的方式声明枚举并不会创建类数据成员,也就是说,所有对象中都不包含枚举。另外,Months只是一个符号名称,在作用域为整个类的代码中遇到它时,编译器将使用12来代替它。
方法二:使用static关键字
class Person{
private:
static const int Months = 12;
double cost[Months];
string name;
int age;上面创建一个名为Months的常量,该常量将与其它静态变量存储在一起,而不是存储在对象中。