MySQL架构总览
MySQL的总体架构如下图所示
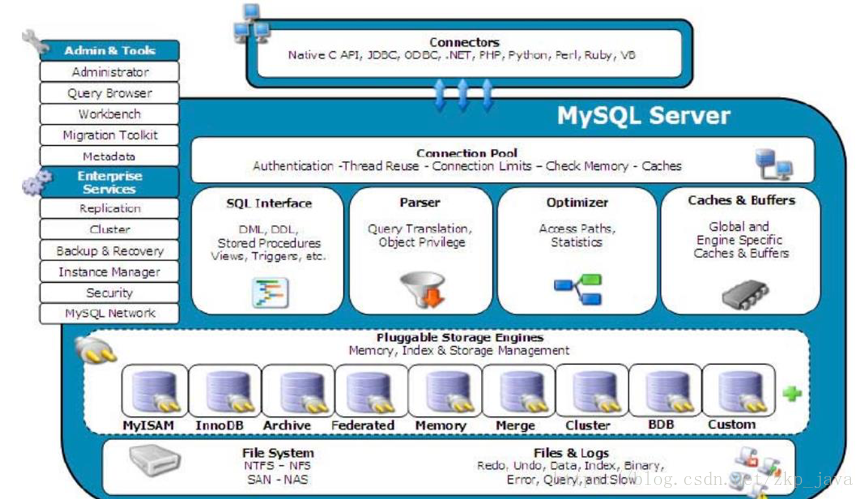
包括数据库连接器、连接池、SQL接口、解析器、优化器、缓存、存储引擎的等。其中常用的存储引擎为Innodb和MyISAM。Innodb有如下特点:
- 使用Table Space的方式进行数据存储,表现为
/var/lib/mysql/ibdata1文件和/var/lib/mysql/ib_logfile0文件; - 支持事物、外键约束等数据库特性;
- 支持行级锁(Row level lock),读写性能都非常优秀;
- 能够承载大数据量的存储和访问;
- 拥有自己独立的缓冲池,能够缓存数据和索引
- 在关闭自动提交的情况下,与MyISAM引擎的速度差异不大;
MyISAM存储引擎具有如下特点:
- 数据存储方式简单,使用B+ Tree进行索引;
- 使用三个文件定义一个表: .MYI .MYD .frm;
- 少碎片、支持大文件、能够进行索引压缩;
- 二进制层次的文件可以移植(Linux->Windows);
- 访问速度飞快,是所有MySQL文件引擎中速度最快的;
- 不支持一些数据库特性,比如事物、外键约束等;
- 表级别锁(Table level lock),性能稍差,更适合读多的操作;
- 表数据容量有限,一般建议单表数据量介于50W~200W之间;
- 增删改查操作完后要使用myisamchk检查优化表;
Innodb存储引擎
Innodb的块结构
Innodb的逻辑存储结构如下所示:
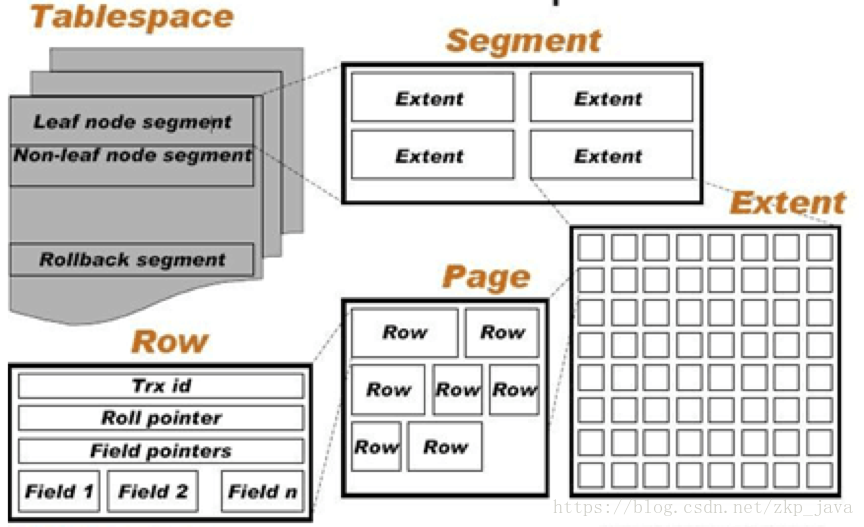
逻辑上所有数据都存放在一个表空间中(TableSpace);表空间管理的单元是段(Segment),分为数据段、索引段和回滚段等;每个段内有若干个区(Extent);每个区内有若干页(Page), B+Tree的一个叶子节点即为一个page,所有叶子节点组成了数据段,所有非叶子节点组成了非数据段;对于数据段来说每一个页内存储了数据库记录。
表空间(TableSpace)
- 在
innodb_file_per_table参数值为off的情况下,Innodb会将所有数据都存放到到一个共享的表空间内(物理上表现为所有数据都存放到共享的ibdata文件中,如/var/lib/mysql/ibdata1文件)。 - 参数值为on的情况下innodb会为每个表都建立一个独立的表空间,表的数据、索引和插入缓冲都是放在该独立的表空间内,而其他类型的数据,如undo信息、系统事物信息、二次写缓存等还是放在原来的共享表空间内(ibdata文件),默认情况下会在
/var/lib/mysql/数据库名/目录下生成表明.frm(表结构文件)和表名.ibd(表数据文件)两个文件用于存放数据、索引和插入缓冲。
段(Segment)
- 常见的Segment有数据段、索引段和回滚段,每一个段对应B+ Tree中的一个节点,其中数据段为B+ Tree的叶节点(leaf node segment),索引段为B+ tree的非叶节点(none-leaf node segment);
- 段的管理有引擎本身完成;
区(Extent)
- 区是由连续的64个页组成;
- 每个页大小为16k;
- 即每个区大小为(64*16k)=1MB;
- 对于大的数据段,MySQL每次最多可以申请4个区,以保证数据的顺序性能;
页(page)
- Innodb的页也称为块(Block);
- 页是Innodb磁盘管理的最小单位;
- Innodb每个页的默认大小是16KB;
- 可以通过参数innodb_page_size将页的大小设置为 4k/8k/16k;
- 每个页里面存储的是行信息;
行(Row)
- Innodb存储引擎是面向行的(row oriented),也就是说数据的存放按行进行存放;
- 每个page大小为16k,每64个连续的page组成一个extent(1MB),多个extent和page组成一个segment;
- segment初始化的时候,会先初始化32个page,之后会根据需要将extent分配给segment,单次最多会分配4个extent给segment;
- Innodb中一个索引(B+ Tree)由两个segment组成,其中所有叶子节点(数据节点)存放在一个segment,所有非叶子节点存放在一个segment钟;
- 行记录(row)存放在数据页(page)里,page由:page header、page trailer、page body组成;
Innodb行记录格式
Compact格式:Compact行记录是在MySQL5.0中引入的,其设计目标是搞笑的存储数据。简单来说,一个页中存放的行数据越多,就减少了读取磁盘块的次数,其性能就越高,Compact行记录的格式如下所示:
- 变长字段长度列表+NULL标志位+记录头信息+列1的数据+列2的数据+….
变长字段长度列表中,若列的长度小于255字节,用1个字节表示,若列的长度大于255字节,则用两字节表示;
Innodb存储引擎的数据页结构
Innodb存储引擎页类型
Innodb存储引擎的page结构如下图所示:
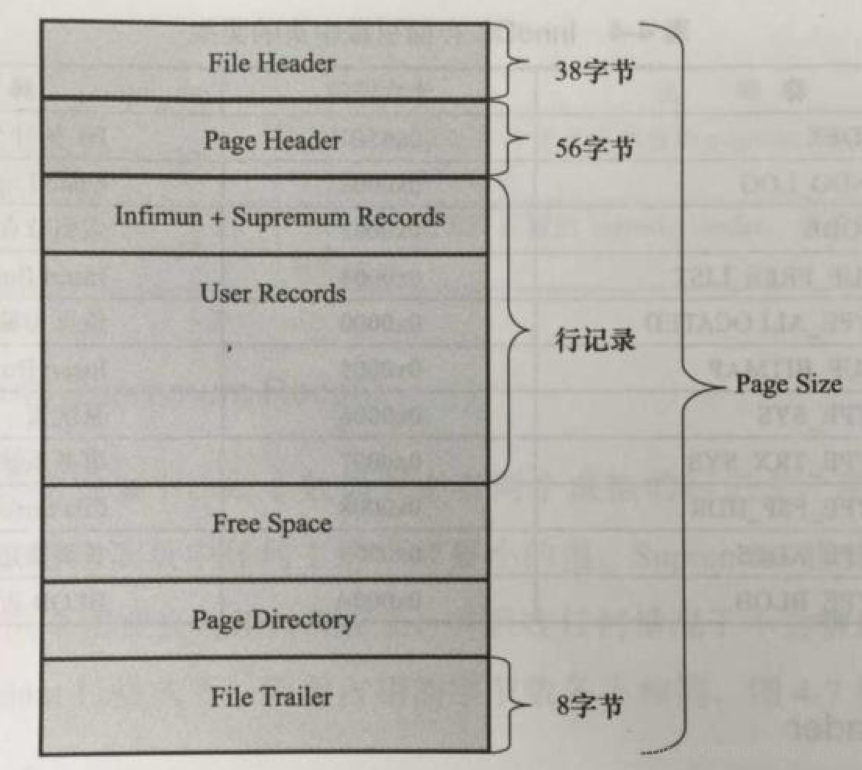
File Header
由8个字段组成,共38个字节,各部分所代表的含义如下所示:
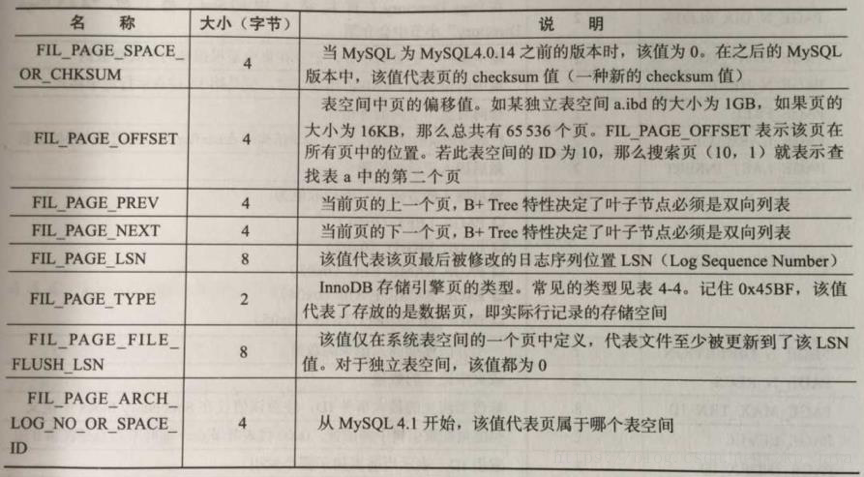
其中
PAGE_TYPE字段取值如下,代表当前页是什么类型的页:
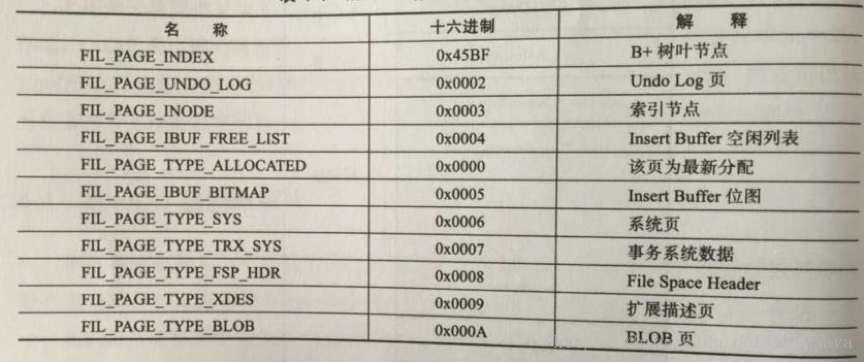
FIL_PAGE_INDEX表示该页是B+ Tree的页节点,用于存储数据库记录。
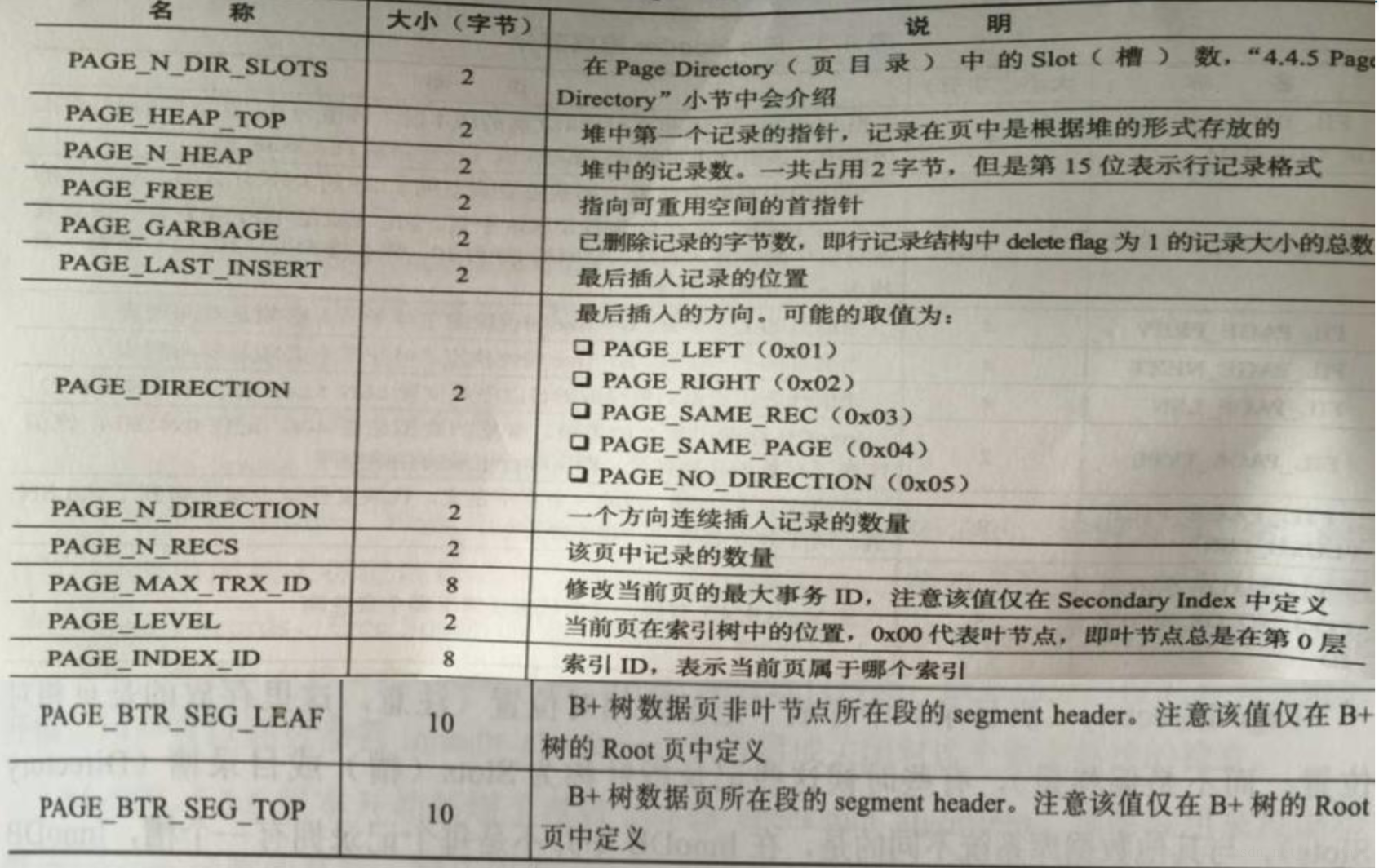
Page Header
Page Header由如下字段组成:
行记录部分
Infimum和Supermum record是虚拟的行记录,用于限定记录的边界,Infimum记录的是比页中任何主键都要小的值,Supermum记录的是比任何可能大的值还要大的值。两者在页创建时被创建,任何情况下不会被删除,在compact和redundant行格式下,占用的字节数不同。在B+Tree中的结构如下所示:

Free Space
该页中可用于存储数据的空闲空间,是一个链表结构,在一条记录被删除后,该空间会被加入到空闲链表中。
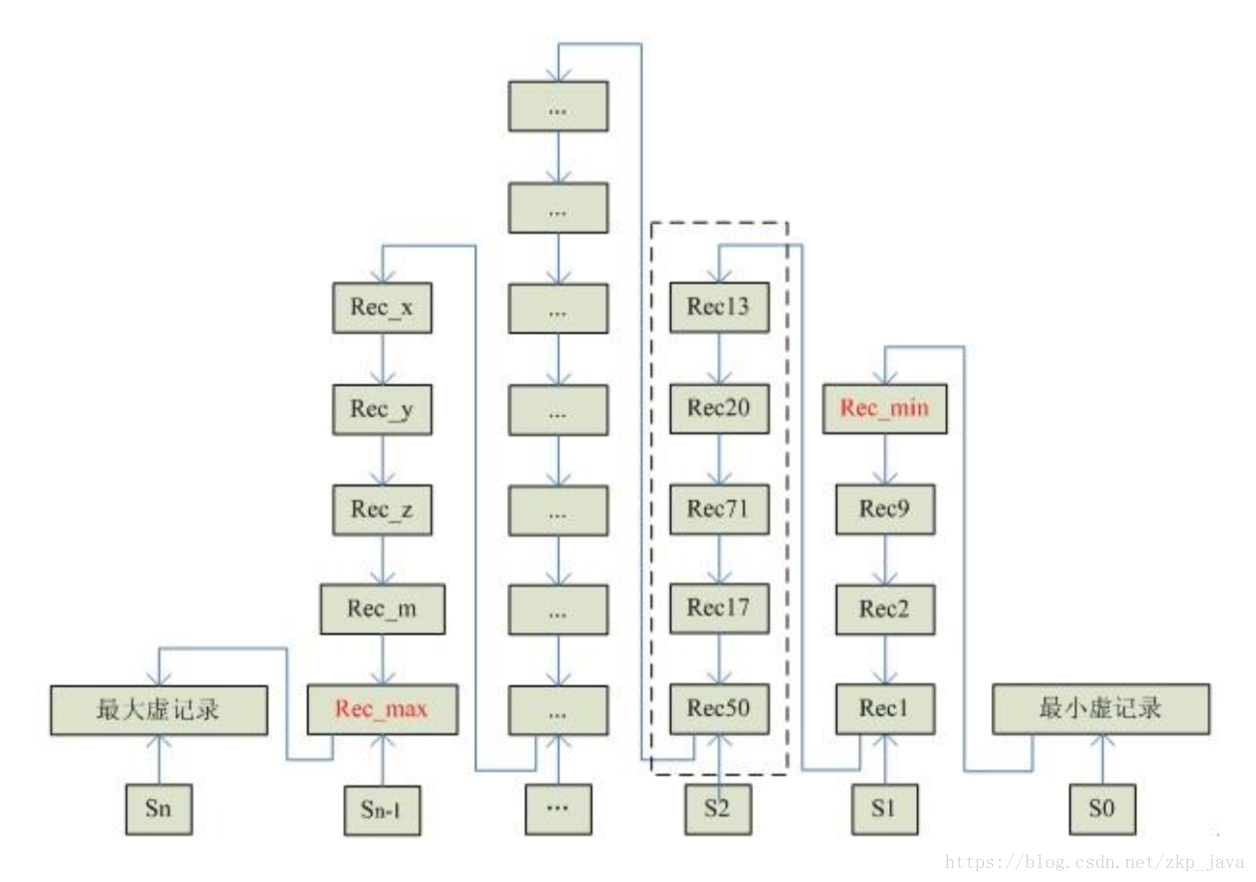
Page Directory
页目录,页称为槽(slot)或目录槽(Directory Slot),用于找该页中的记录,一个槽中可能包含多条记录。
note: B+Tree本省并不能找到一条具体的记录,只能找到该记录所在的页,数据库把页载入到内存当中,通过Page Directory再进行二叉查找。
如下图所示Si为Page Directory中第
个槽位,每个槽位链接了若干条记录,通过二分查找即可找到其中的某一条记录。
File Trailer
File Trailer用于检测页是否已经完整的写入了磁盘,如:写入过程发生磁盘损坏,机器关闭等)由FIL_PAGE_END_LSN组成,占用8字节,前4字节代表该页的checksum值,最后4字节和File Header中FIL_PAGE_LSN相同,通过与FIle Header中FIL_PAGE_OR_CHECKSUM和FIL_PAGE_LSN进行比较,看是否一致,来保证页的完整性。
Innodb页结构总结如下图所示
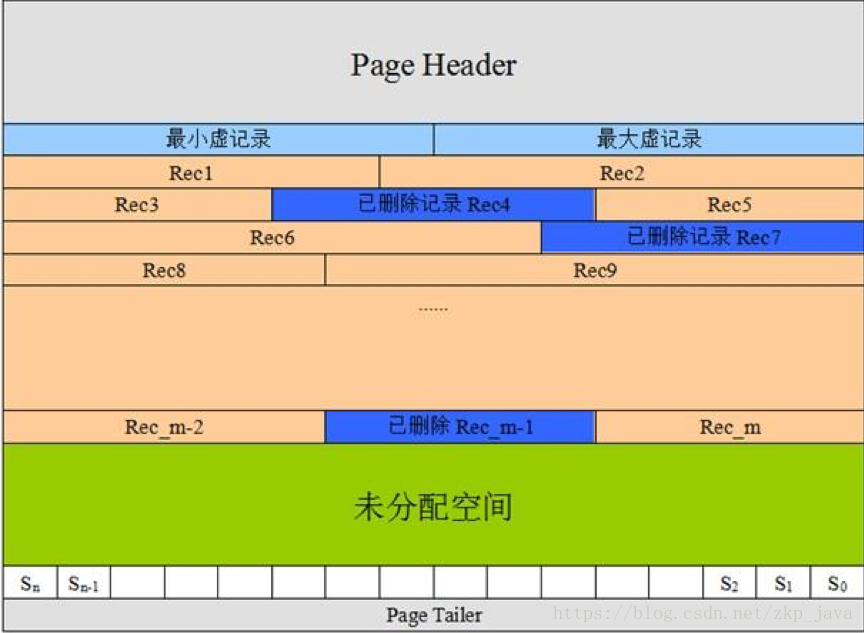
聚簇索引和二级索引
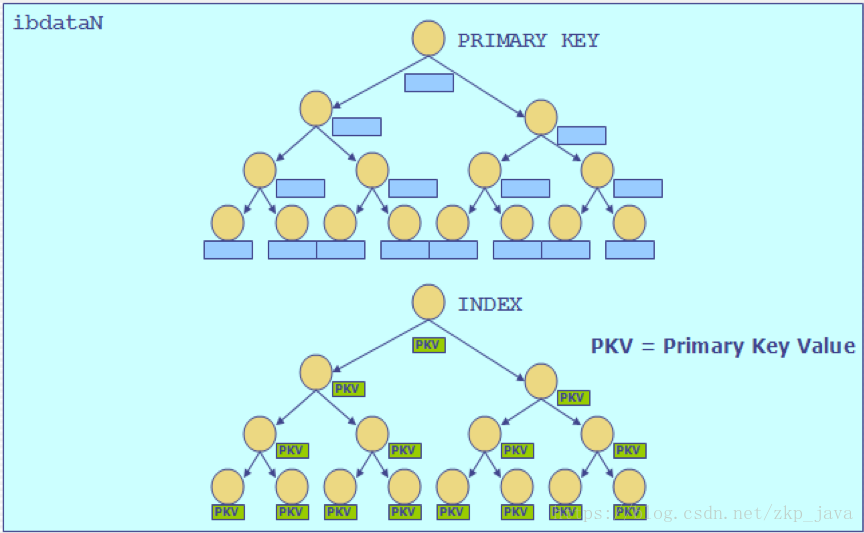
Innodb引擎的主键索引即为聚簇索引,存储了主键索引的记录,二级索引存储的是记录的主键,而不是数据存储的地址;MyISAM使用非聚簇索引,索引数据和记录是分离的。如下图所示为Innodb的存储结构:
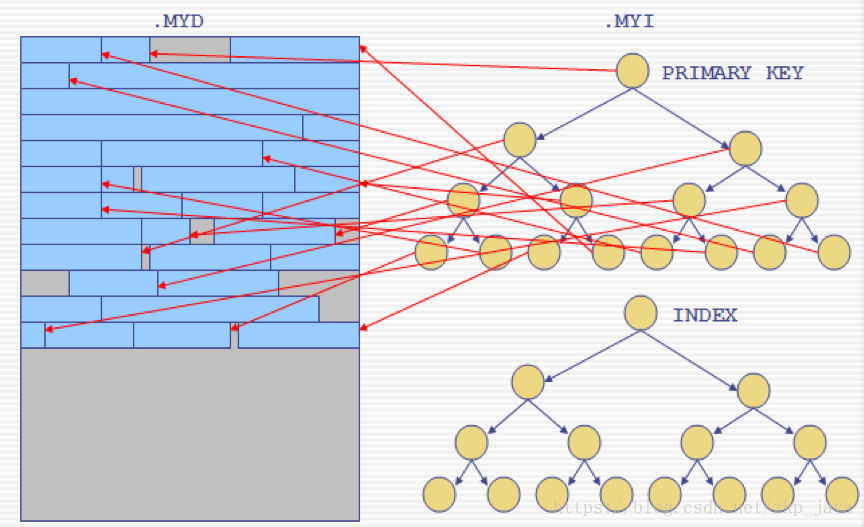
如下图所示为MyISAM的存储结构:
Innodb存储示例
下面我们通过一个具体的示例进行演示聚集索引和二级索引,我们一pl_ranking(编程语言排行榜)表为例:
| id(主键) | plname(编程语言名称,普通索引) | ranking(排名) |
|---|---|---|
| 15 | C | 2 |
| 16 | Java | 1 |
| 18 | Php | 6 |
| 23 | C# | 5 |
| 26 | C++ | 3 |
| 29 | Ada | 17 |
| 50 | Go | 12 |
| 52 | Lisp | 15 |
| … | … | … |
该表对应的聚簇索(主键索引)引如下所示:
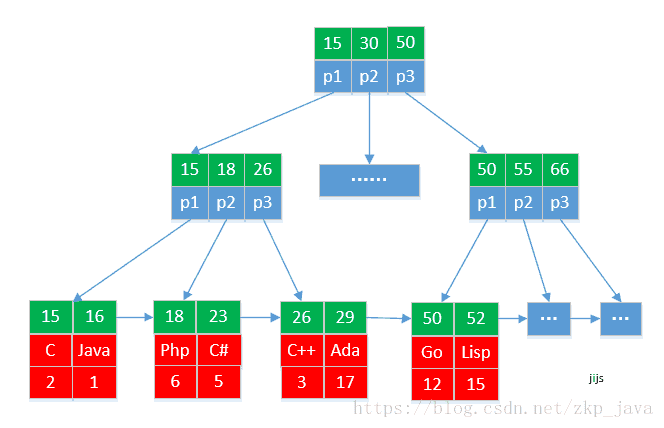
从图中我们可以看出,索引和记录都是存放在一颗树上,通过定位索引就可以直接查找到数据,这颗树是根据主键创建的,如果查找id=16的编程语言,
select id, plname, ranking from pl_ranking where id=16;,则只需要读取3个磁盘块,就可以获取到数据。
该表的二级索引结构如下图所示:
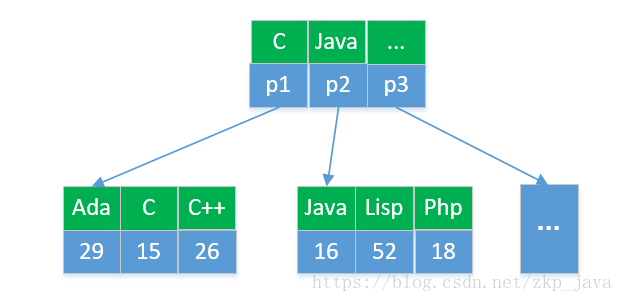
该B+Tree是根据plname列构建的,只存储索引数据,plname和id的映射。比如查找编程语言为Java的数据,
select id, plname, ranking from pl_ranking where plname=’Java’;,首先通过二级索引树找到Java对应的主键id为16(需要读取两个磁盘块),然后去主键索引中查找id为16的数据(需要读取三个磁盘块),据此我们可以得到如下的数据库优化方法:
- 尽量使用主键索引查找记录,因为主键索引(聚餐索引)查询效率比非主键索引查询效率更高(需要读取的磁盘块数更少);
- 定义主键的长度应尽可能的小,因为主键定义的长度越小,二级索引的大小就越小,这样每个磁盘块存储的索引数据越多,查询效率就越高;
MySQL的执行计划
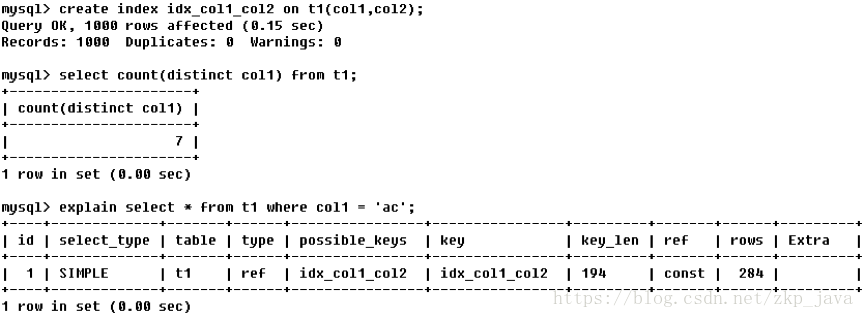
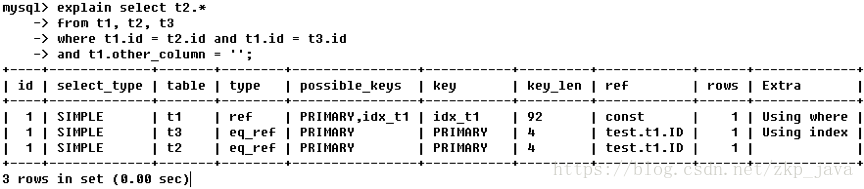
可以使用explain关键字来查看一条SQL语句的执行计划,如下图所示的一条SQL语句的执行计划:

执行计划输出中包含
id、
select_type、
type、
key、
key_len、
ref、
rows、
Extra字段。接下来我们一一来了解这些字段的含义。
id字段
id字段是一组数字,表示查询中执行select子句或操作表的顺序:
- 如果id相同,则执行顺序由上至下;
- 如果是子查询,id的序号会递增,id值越大1越高,越先被执行;
- 如果id相同,可以认为是一组,从上往下顺序执行,在所有组中,id值越大,优先级越高,越先执行;
select_type字段
select_type字段表示每个select子句的类型(简单OR复杂),select_type取值如下:
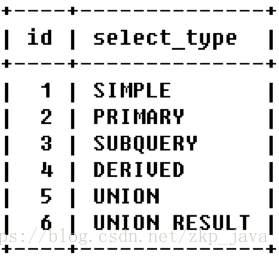
- SIMPLE:查询中不包含子查询或者UNION;
- 查询中包含任何复杂的子部分,最外层查询则被标记为:PRIMARY
- 在SELECT或WHERE列表中包含了子查询,该子查询被标记为:SUBQUERY
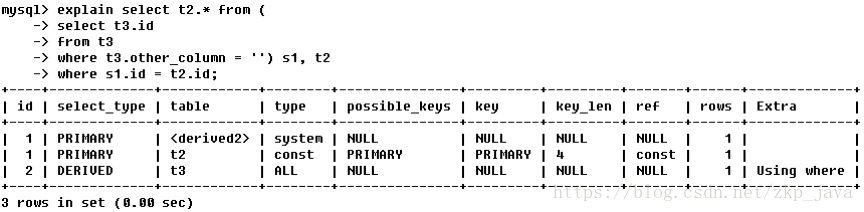
- 在FROM列表中包含的子查询被标记为:DERVIED(衍生)
- 若第二个SELECT出现在UNION之后,则被标记为UNION,若UNION包含在FROM子句的查询当中,外层SELECT将被标记为:DERIVED
- 从UNION表获取结果得SELECT被标记为:UNION RESULT
示例
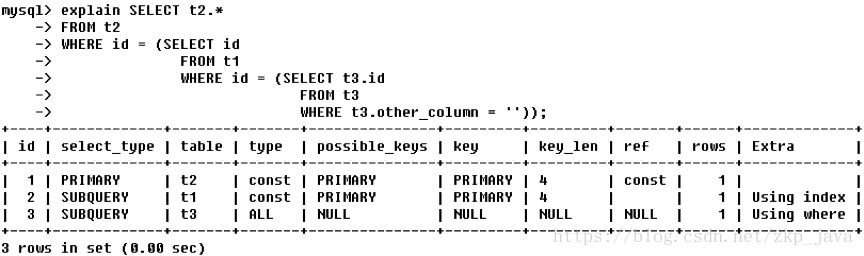
如下图所示的查询:
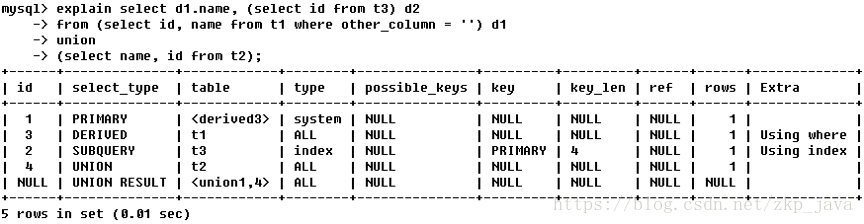
- 第一行:id列为1,表示第一个select,select_type列的primary表示该查询为外层查询,table列被标记为derived3,表示查询结果来自一个衍生表,其中3代表该查询衍生自第三个select查询,即id为3的select;
- 第二行:id为3,表示该查询的执行次序为2(4→3),是整个查询中第三个select 的一部分,因查询包含在from中,所以为derived;
- 第三行:select列表中的子查询,select_type为subquery,为整个查询中的第二 个select;
- 第四行:select_type为union,说明第四个select是union里的第二个select,最先 执行;
- 第五行:代表从union的临时表中读取行的阶段,table列的union1,4表示用第一个和第四个select的结果进行union操作;
type字段
表示MySQL在表中找到所需行的方式,又称“访问类型”,常见类型如下:
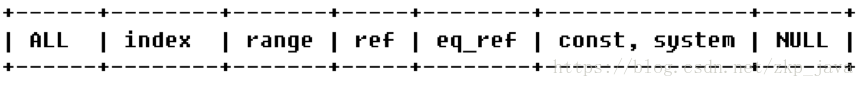
由左至右,由最差到最好,各类型代表的意义如下所示:
- ALL: FullTableScan,MySQL将遍历全表以找到匹配的行;
- index: FullIndexScan,index与ALL区别为index类型只遍历索引树;
- range: 索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行,常见于between、<、>等的查询;
- ref: 非唯一性索引扫描,返回匹配某个单独值的所有行,常见于使用非唯一索引即唯一索引的非唯一前缀进行的查找;
- eq_ref: 唯一性索引扫描,对于每个索引键,表中只有一条记录与之 匹配,常见于主键或唯一索引扫描;