近期在写一个小玩意,需要保存一些图片,以前我采用的是FTP或者直接数据库保存文件,用FTP来保存文件感觉比较麻烦,用数据库吧,还要改字段类型,修改代码,修改查询语句,懒得改。
以前看过mongonDb的文章,随就打算用Mongon来存储文件,然后打算百度一下看看,C#操作mongoDb的文章,全是互相抄袭,而且年代久远,很多东西mongoDb都没有了,随就魔法上网。
不在介绍MongoDb是什么,怎么安装,具体百度
一:使用前准备
1:安装MongoDb,百度安装 ,并下载任意一个mongonDb的可视化软件
我mongoDb是装在的linux服务器上,具体的安装平台有读者自己决定
可视乎软件我推荐Robo
2:新建一个winfrom项目
右键项目Nuget包管理器,下载


安装这两个包
二:文件上传
这里先用图片来做测试
mongonDb有2种方式来存储,1:普通的document来存储文件,最大为16MB,2:gridFs存储,

1:普通document存储
示例代码
引用命名空间
using MongoDB.Bson; using MongoDB.Driver;
定义数据库名和地址字
private string connStr = "mongodb://xx.93.232.xx:27017"; private string dbName = "xxxx"; private IMongoDatabase database;
获得dataBase
var client = new MongoClient(connStr); if (client != null) { database = client.GetDatabase(dbName); bucket = new GridFSBucket(database); //这个是初始化gridFs存储的 }
创建文档集合
private void CheckAddCreateCollection(string collectionName) { var collectionList = database.ListCollections().ToList(); var collectionNames = new List<string>(); //获得所有集合的名称 collectionList.ForEach(x => { collectionNames.Add(x["name"].AsString); }); //如果没有这个集合就创建一个 (相当于创建一个表) if (!collectionNames.Contains(collectionName)) { database.CreateCollection(collectionName); } }
写一个关于图片信息的类,这里就用用户头像来表示了
public class UserAvatar { public int AvatarId { get; set; } public byte[] Avatar { get; set; } }
如果你感到疑惑为什么要创建一个类呢,因为mongon的任何crud操作都需要一个
IMongoCollection<TDocument>
的类型来进行操作。可以理解成ef中DbSet<xxxx>
获取前面创建好的集合
private IMongoCollection<UserAvatar> GetUserCollection(string name) { return database.GetCollection<UserAvatar>(name); //传入集合的名字 }
读取图片的字节流
var bytes = File.ReadAllBytes(@"C:\Users\哈哈哈\Desktop\test.jpg");
向mogoDb插入一条数据
private async Task< bool> AddAvater(UserAvatar avatar, IMongoCollection<UserAvatar> userAvatar) { await userAvatar.InsertOneAsync(avatar); //插入一条数据
//一下代码是判断了是否插入成功。 var result = userAvatar.AsQueryable().Where(x => x.AvatarId == avatar.AvatarId).Select(x => new UserAvatar { Avatar = x.Avatar, AvatarId = x.AvatarId }).ToList(); if (result.Count > 0) { this.textBox1.Text = result[0].AvatarId.ToString(); return true; } return false; }
让我们到robo里面看看是否插入成功了。

可以看到有数据了
从MogoDb取出一条数据
private Task<UserAvatar> GetUserAvatar(int avatarId,string collectionName) { var task = Task.Run(() => { var userAvatar = GetUserCollection(collectionName); var result = userAvatar.AsQueryable().Where(x => x.AvatarId == avatarId).Select(x => new UserAvatar { Avatar = x.Avatar, AvatarId = x.AvatarId }).ToList(); if (result.Count > 0) { return result[0]; } return null; }); return task; }
为什么上面的代码不在where后面直接toList呢?
答:MongoDb在文档里面会自动添加一个_id的字段,这个时候反序列话,就不会成功了,报异常id不匹配。
让我们来看下效果
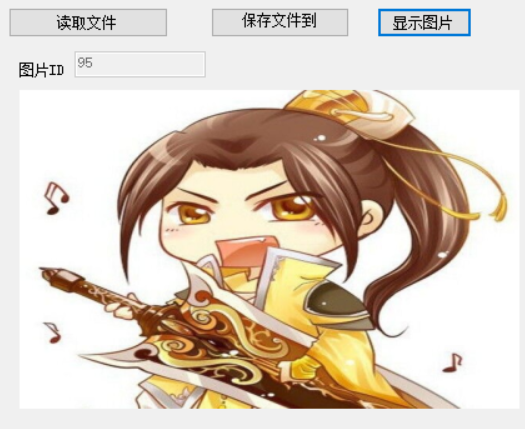
显示图片的代码
private void ShowImage(byte[] imageBytes) { pictureBox1.Image = null; MemoryStream memoryStream = new MemoryStream(imageBytes); Image image = Image.FromStream(memoryStream); Bitmap bitMap = new Bitmap(image, new Size(pictureBox1.Width, pictureBox1.Height)); pictureBox1.Image = bitMap; }
看看数据库图片ID为95的在不在。

2:grifFs存储文件。按照Mongodb最新的文档来说,基本上百度到一些C#使用gridFs来存储文件的文章已经没有用用了。
根据Mongon文档的介绍,GirdF是用来存储大于16m的文件。
GridFS是一种存储大于最大文档大小(目前为16MB)的二进制信息的方法。当您将文件上传到GridFS时,文件会分成多个块并上传各个块。从GridFS下载文件时,将从块中重新组合原始内容。
初始化
private GridFSBucket bucket; bucket = new GridFSBucket(database);
根据官方文档说明,GridFS文件使用两个集合存储在数据库中,通常称为“fs.files”和“fs.chunks”。上传到GridFS的每个文件在“fs.files”集合中都有一个文档,其中包含有关该文件的信息以及“fs.chunks”集合中用于存储文件内容的必要数量的块。
GridFS“bucket”是“fs.files”和“fs.chunks”集合的组合,它们共同代表可以存储GridFS文件的存储桶。
GridFSBucket对象是表示一个GridFS的桶的根对象。
可以看来使用GirdFSBucket来管理所有的文件。
上传文件非常的简单
var id = bucket.UploadFromBytes("filename", source); //source字节数组 var id = await bucket.UploadFromBytesAsync("filename", source);
如果上传成功我们就会在robo中可以看到在collection分组下面会出现
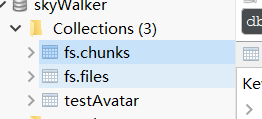
fs.chunks,和fs.files两个集合
先看看fs.files里面存储了

其中objectId,就是上面上传代码返回值,toString之后的结果,
下载文件 通过id来下载
public Task<byte[]> DownLoadFileFromGirdFs(ObjectId id) { return bucket.DownloadAsBytesAsync(id); }
如果不知道Id怎么办?
就要先查找文件了用文件名,上传时间呀也可以来查找
我是用文件名来查找的。如果你要问用那个objectId可以不可以查找?
可以很清楚的告诉你,我没有实验成功,直接就会报异常,给我报Unable to determine the serialization information(无法确定的序列化信息)
查找代码
public ObjectId GetUploadFileId(string fileName) { var filter = Builders<GridFSFileInfo>.Filter.Eq(x => x.Filename, fileName); //eq方法,就是等于,还有其他的方法,具体看Mongo的api文档 var sort = Builders<GridFSFileInfo>.Sort.Descending(x => x.UploadDateTime); //按上传时间来倒叙一下 var options = new GridFSFindOptions { Limit = 1, Sort = sort }; using (var cursor = bucket.Find(filter,options)) { var fileInfo = cursor.ToList().FirstOrDefault(); if (fileInfo != null && fileInfo.Length > 0) { return fileInfo.Id; } return new ObjectId(); } }
现在来结合下下载与查找代码来看下效果
private async void button5_Click(object sender, EventArgs e) { var id = GetUploadFileId("yemobaiAvatar"); byte[] imageBytes= await DownLoadFileFromGirdFs(id); ShowImage(imageBytes); }
结果

最后附上官方文档地址 http://mongodb.github.io/mongo-csharp-driver/