是什么?
FastDFS是一个轻量级分布式文件系统。
能干嘛?
对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等。
在Linux上的安装连接
《FastDFS在Linux上的安装》
相关概念
一、网络拓扑图

对上图的基本了解,client是客户端,tracker和storage是FastDFS系统的俩个角色。
二、详细了解tracker和storage
Storage
是什么?
存储服务器
作用?
主要作用是文件存储
相关介绍
1、如上图,storage做集群时,以组[group]为单位(也可以将一个组看成一个卷[volume],不同材料称呼不同)。集群的总容量为所有组的总和。
2、 一个卷内storage server之间相互通信,文件进行同步,保证组内storage完全一致,所以一 个卷的容量以最小的服务器为准。不同的卷之间相互不通信。
3、当某个卷的压力较大时可以添加storage server(纵向扩展),如果系统容量不够可以添加卷(横向扩展)。
Tracker
是什么
调度服务器
作用?
负载均衡和调度,管理所有的卷[volume]包括其中的storage server
相关介绍
1、每个storage在启动后会连接Tracker,告知自己所属的group等信息,并保持周期性的心跳,tracker根据storage的心跳信息,建立group==>[storage server list]的映射表。
2、Tracker的集群中所有的tracker是平等的,客户端请求tracker server采用轮询的方法,如果请求的tracker不能提供服务就换另一个tracker。
工作流程
一、文件上传
流程图
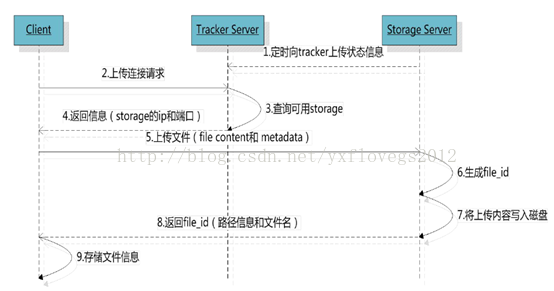
流程说明
1、选择tracker server:当集群中不止一个tracker server时,由于tracker之间是完全对等的关系,客户端 在upload文件时可以任意选择一个trakcer。
2、选择存储的group:当tracker接收到upload file的请求时,会为该文件分配一个可以存储该文件的 group。
支持如下选择group的规则:
(1) Round robin,所有的group间轮询
(2) Specified group,指定某一个确定的group
(3) Load balance,剩余存储空间多多group优先
3、选择storage server:当选定group后,tracker会在group内选择一个storage server给客户端。
支持如下选择storage的规则:
(1) Round robin,在group内的所有storage间轮询
(2) First server ordered by ip,按ip排序
(3) First server ordered by priority,按优先级排序(优先级在storage上配置)
4、选择storage path:当分配好storage server后,客户端将向storage发送写文件请求,storage将会为 文件分配一个数据存储目录(安装博客中的图片存储配置的路径是存储目录)
支持如下规则:
(1) Round robin,多个存储目录间轮询
(2) 剩余存储空间最多的优先
5、生成Fileid:选定存储目录之后,storage会为文件生一个Fileid。
规则:
由storage server ip、文件创建时间、文件大小、文件crc32和一个随机数拼接而成,然后将这个二 进制串进行base64编码,转换为可打印的字符串。
6、选择两级目录:每个存储目录下有两级256*256的子目录,storage会按文件fileid进行两次hash(猜 测),路由到其中一个子目录,然后将文件以fileid为文件名存储到该子目录下。

7、客户端upload file成功后,会拿到一个storage生成的文件名,接下来客户端根据这个文件名即可访问 到该文件。
二、文件下载
流程图:

流程说明:
1、选择tracker server:和upload file一样,在download file时随机选择tracker server。
2、选择group:tracker发送download请求给某个tracker,必须带上文件名信息,tracke从文件名中解析 出文件的group、大小、创建时间等信息,根据group信息选择对应的group
3、选择storage server:从group中选择一个storage用来服务读请求。由于group内的文件同步时在后台 异步进行的,所以有可能出现在读到时候,文件还没有同步到某些storage server上,为了尽量避免访问到 这样的storage,tracker按照一定的规则选择group内可读的storage。