HIVE是基于Hadoop的一个数据仓库,可以将结构化的数据文件映射成一张表,并提供类SQL的查询语句,其SQL操作的基本原理是MapReduce,在本文最后的例子中,可以发现在某些操作时,Hive SQL其实是调用了MapReduce过程进行处理,因此使用Hive可以完成数据处理的操作,避免编写MapReduce的业务逻辑,提高开发效率。
其实大部分数据库都是以文件映射的形式保存到磁盘中,对外提供SQL操作,然后通过业务逻辑去磁盘中读写对应的数据。Hive的数据是保存在HDFS中的,元数据等信息是保存到mysql中,因此安装Hive需要依赖mysql.
Linux中安装mysql5.6
- 查找当前的Linux系统中是否有mysql及其依赖,如有则需要删除
# rpm -qa | grep mysql
# sudo yum -y remove mysql-libs.x86_64- 设置rpm安装源,前提需要安装
wget
# wget dev.mysql.com/get/mysql-community-release-el6-5.noarch.rpm
# sudo yum localinstall mysql-community-release-el6-5.noarch.rpm- 查看需要安装的版本,本例安装mysql5.6版本。其中enable=1表示要安装的,enable=0表示不安装。
查看命令:
# yum repolist enabled | grep mysql配置安装,通过以下命令修改文件可设置需要安装的版本。
# vi /etc/yum.repos.d/mysql-community.repo- 安装
# yum -y install mysql-server mysql- 启动
# service mysqld start
# 设置开机启动
# chkconfig mysqld on如果启动失败,报错文件写入的问题。第一个命令是查看SELinux是否启动,第二个命令是关闭SELinux。
# getenforce
# setenforce 0- 设置密码
# mysqladmin -u root password 'root'- 开启远程访问,开启后可从其它主机访问该数据库。
# mysql -u root -p
mysql>use mysql;
mysql>update user set host = '%' where user = 'root';
mysql>select host, user from user;
mysql>FLUSH PRIVILEGES;
mysql>quit- 其它设置,允许用户远程连接
/usr/bin/mysql_secure_installation
Hive安装
Hive的文件系统是HDFS,因此在安装之前需要确保Hadoop集群已经安装成功的。Hive不存在集群安装的说法,Hive的文件是以Hadoop(HDFS)为基础的,因此只需要在集群中的一个主机上安装即可。
- 解压hive安装包
tar包下载路径apache-hive-1.2.2-bin.tar.gz
# tar -zxvf apache-hive-1.2.2-bin.tar.gz- 配置hive环境变量,
vi /etc/profile加入export HIVE_HOME路径 vi conf/hive-env.sh(将hive-env.sh.template文件更改过来)配置其中的$hadoop_home,即Hadoop路径- 在hive包的conf文件夹下
vi hive-site.xml添加mysql元数据的配置。
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>- 启动
# bin/hive启动可能会产生的问题:
1.如果提示无法加载com.mysql.jdbc.Driver类,则需要将mysql驱动jar放到/hive/lib中,本文使用mysql-connector-java-5.1.34.jar版本的;
2.Jline包版本不一致的问题,需要拷贝hive的lib目录中jline.2.12.jar的jar包替换掉hadoop中的
/home/hadoop/app/hadoop-2.6.4/share/hadoop/yarn/lib/jline-0.9.94.jar;
至此,hive安装成功。启动后即可进行测试使用。
Hive使用
通过命令nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &后台启动hive服务。
客户端连接,sql增删改查与标准的SQL相差无几,对于mysql或Oracle比较熟悉的同学上手起来很快。

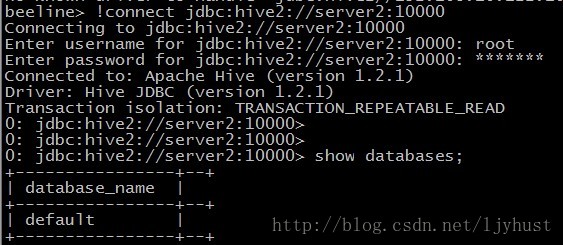
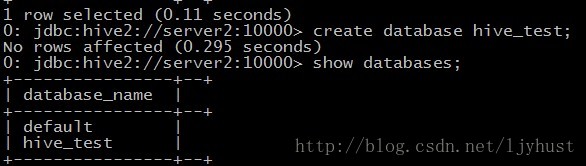
创建数据库
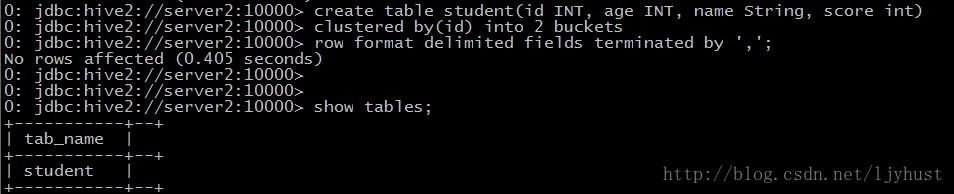
- 创建一个带分桶的表,分桶表的作用:最大的作用是用来提高join操作的效率;但是两者的分桶数要相同或者成倍数。
为什么可以提高join操作的效率呢?因为按照MapReduce的分区算法,是Id的HashCode值模上ReduceTaskNumbers,所以一个ID会分到同一个桶中,这样合并就不用整个表遍历求笛卡尔积了,对应的桶合并就可以了。
- 插入一条数据,会启动MapReduce,影响速度
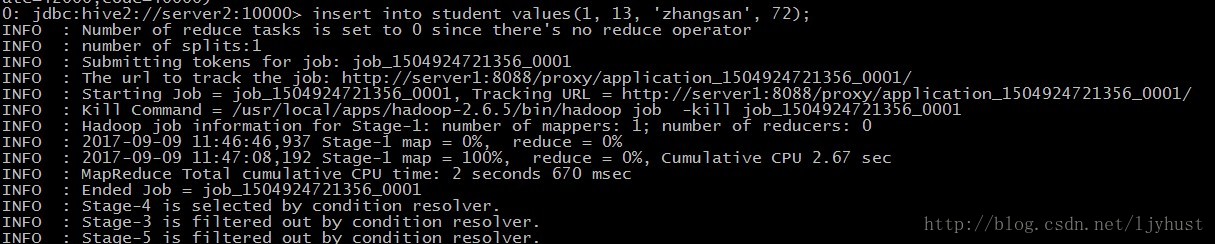
- 批量传入数据
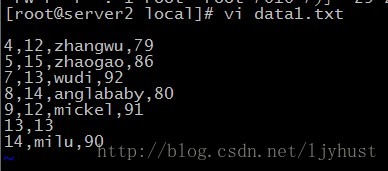
load命令只是将本地文件复制到hdfs文件中,因此不会涉及到MapReduce运行,速度相对来说比较快。
load data local inpath '/usr/local/data1.txt' into table student;select查询
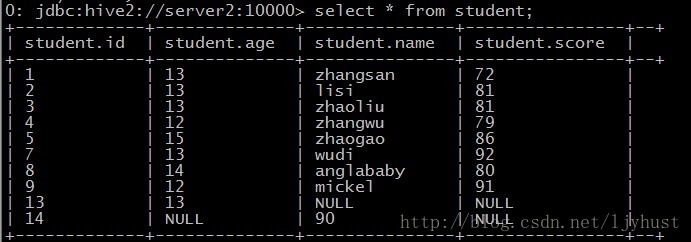
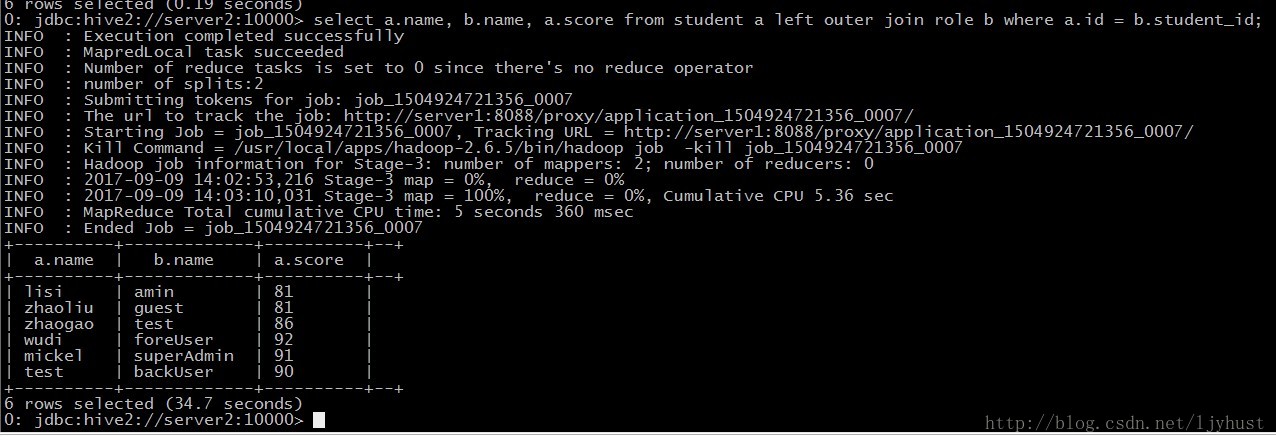
- Join查询