最近有个项目需要用到拼音搜索并高亮显示所匹配的中文,其实拼音搜索可以通过将中文转化为拼音存储在库表如mysql中,然后通过sql like语句查询搜索到对应的中文,在一些并发要求并不高、中文已知的情况下是完全可以做到拼音搜索。但是由于项目要求不仅能够搜索出来对应的中文,但是对于高亮显示匹配的中文难度成本就比较高了,此时需要通过中文拼音分词来实现。
经过一番调研,鉴于elasticsearch社区的活跃,及相关拼音分词插件也比较丰富,选用ES作为搜索方案。虽然现在ES版本已经到了6.x了,而且每隔一个月左右都会有新版本发布,由于机器条件等的限制,ES版本越高越吃内存和CPU,所以选择2.4.2版本,稳定、占用内存小、支持集群,满足本次需求,如果空间不够也可多安装几个ES组成集群。
es安装
官网选择2.4.2的linux版本tgz安装包下载上传到linux服务器,解压后在bin中启动,两种启动方式:
1.前台启动./elasticsearch,启动日志显示在前台console,关闭会话则关闭ES
2.后台启动./elasticsearch -d,启动日志打印在logs文件夹下。
此时可通过linux的curl命令来请求ES的http restful接口创建索引、type、增删改查等基本操作,也可通过Post等工具请求ES的Http接口。本文通过head工具进行操作。
安装plugin-head
使用head插件是ES必备的工具,除了可以操作请求restful接口操作ES数据库,还可以用于观察ES的状态等。
通过在bin文件下执行命令./plugin install mobz/elasticsearch-head,ES则自动到github上下载并安装。
通过ip:port/_plugin/head即可访问ES,port默认为9200,如果发现不能访问,则需要在config文件下的elasticsearch.yml修改或添加如下网络配置,然后重启es后再通过ip:port/_plugin/head访问即可(http.port可配置)。
elasticsearch.yml配置,暂未知es的关闭方法,可通过
kill命令关闭es
#网络及端口配置
network.host: 0.0.0.0
http.port: 11192创建索引index
ES的Restful接口语法规则一般是用json来进行数据存储或设置,可通过head插件中的【复合查询】菜单栏进行操作,支持多数HTTP传输模式。
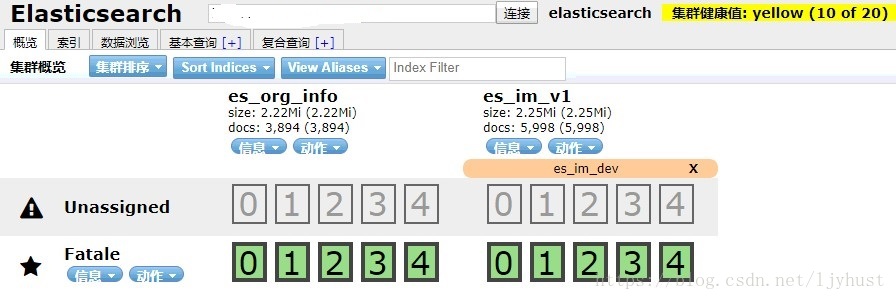
ES中的索引相当于mysql的库,type相当于mysql中的表。
ES创建索引的方式也很简单,通过http PUT接口即可创建一个索引,如下:
http://172.168.1.11:11192/es_dev_v1
//通过对以上接口进行PUT操作,即可创建名为 es_dev_v1 的索引创建完成后如下

创建type,并创建mapping
ES默认是可以不用设置type的mapping的,可以直接通过http存储数据,ES会根据存储的json数据自动创建一个type及对应的字段mapping,如下
http://172.168.1.11:11192/es_dev_v1/temp/12
//传输方式:POST
{
"name":"test",
"address":"America",
"tel":"132134542"
}
//通过POST存储数据,即在es_dev中的temp type(表)中存储了一条id=12的数据,如果id不传,则ES会自动创建一个id用于引用这条数据。添加后的数据及mapping如下,3个字段都默认为String类型

通过访问http://172.168.1.11:11192/es_dev_v1
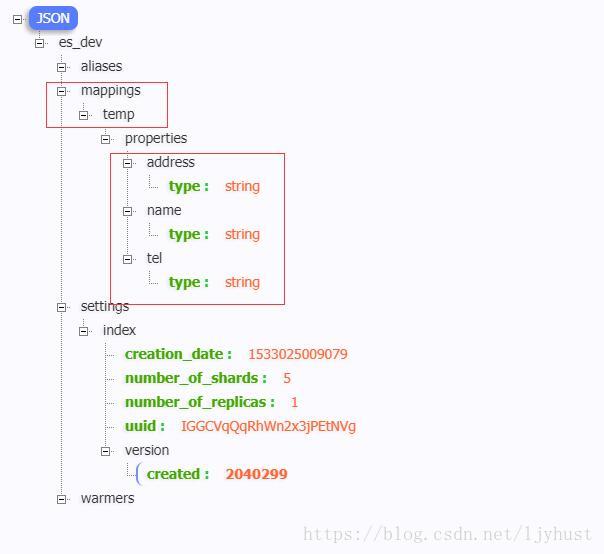
如何修改索引字段类型(即mapping)
ES索引一旦创建,不支持修改索引的mapping,如修改某个字段的类型、分词、搜索规则等,ES的规则是字段类型只能是创建索引的时候就设置好或者由ES自动设置,如果要修改只能重新创建一个索引index,然后重新设置mapping.当然线上生产环境是不允许这么做的。
可以借用别名来切换ES库表,创建一个索引es_dev_v1时,指定它的别名为es_dev,当需要修改mapping时,再创建一个索引es_dev_v2设置新的mapping,然后将数据刷入es_dev_v2,删除es_dev与es_dev_v1的别名关系,重新建立es_dev和es_dev_v2的关联。此时使用es_dev即可访问索引库。
参考:https://blog.csdn.net/lengfeng92/article/details/38230521
使用搜索
网上百度或博客上对于Http或Java客户端搜索有很多的文章讲解得很清楚,本文就不再赘述,再下节拼音搜索会简单搜索。
中文拼音分词工具使用
下载对应版本的拼音搜索插件,解压copy至elasticsearch-2.4.2/plugins/pinyin文件夹下面,其中包括elasticsearch-analysis-pinyin-1.8.2.jar、nlp-lang-1.7.jar、plugin-descriptor.properties文件,重启es服务,如下图

- 创建索引添加拼音分词
给索引es_dev_v3添加拼音分析工具
http://172.168.1.11:11192/es_dev_v3 PUT
{
"index" : {
"analysis" : {
"analyzer" : {
"pinyin_analyzer" : {
"tokenizer" : "my_pinyin"
}
},
"tokenizer" : {
"my_pinyin" : {
"type" : "pinyin",
"keep_separate_first_letter" : false,
"keep_full_pinyin" : true,
"keep_original" : true,
"limit_first_letter_length" : 10,
"lowercase" : true,
"remove_duplicated_term" : true
}
}
}
}
}- 测试分词工具
访问http://172.168.1.11:11192/es_dev_v3/_analyze?text=刘德华&analyzer=pinyin_analyzer,返回拼音分词结果如下,可看出elasticsearch-analysis-pinyin支持拼音分词和首字母缩写
{
"tokens": [
{
"token": "liu",
"start_offset": 0,
"end_offset": 1,
"type": "word",
"position": 0
},
{
"token": "de",
"start_offset": 1,
"end_offset": 2,
"type": "word",
"position": 1
},
{
"token": "hua",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 2
},
{
"token": "刘德华",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 3
},
{
"token": "ldh",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 4
}
]
}- 配置mapping
mapping添加如下设置,表示user表中的userName字段采用拼音分词搜索功能,而userPhone字段则不进行分词。ES默认对所有String类型的字段进行分词,意味着搜索是一个一个词去匹配搜索的,如果不需要分词,则设置为not_analyzed即可,此时则只支持精确匹配该字段搜索。
http://172.168.1.11:11192/es_dev_v3/user/_mapping POST
{
"user": {
"properties": {
"userName": {
"type": "string",
"fields": {
"pinyin": {
"type": "string",
"store": false,
"term_vector": "with_offsets",
"analyzer": "pinyin_analyzer",
"boost": 10
}
}
},
"userAddress": {
"type":"string",
"similarity": "classic"
},
"userPhone": {
"type":"string",
"index": "not_analyzed"
}
}
}
}- 搜索
以下均用match_phrase短语搜索匹配,其它搜索如term、match_all等感兴趣的同学可以在网上搜下其它技术博客研究下。
1.通过POST接口上传demo数据

2.userName搜索
POST请求接口 http://172.168.1.11:11192/es_dev_v3/user/_search
{
"query": {
"match_phrase": {
"userName": "张"
}
},
"highlight": {
"fields": {
"userName": {}
}
}
}
返回结果
{
"took": 126,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.19178301,
"hits": [
{
"_index": "es_dev_v3",
"_type": "user",
"_id": "1",
"_score": 0.19178301,
"_source": {
"userName": "张三",
"userAddress": "深圳南山",
"userPhone": "1387897454"
},
"highlight": {
"userName": [
"<em>张</em>三"
]
}
}
]
}
}3.userName拼音搜索
POST请求 http://172.168.1.11:11192/es_dev_v3/user/_search
{
"query": {
"match_phrase": {
"userName.pinyin": "zhang"
}
},
"highlight": {
"fields": {
"userName.pinyin": {}
}
}
}
返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.5342641,
"hits": [
{
"_index": "es_dev_v3",
"_type": "user",
"_id": "1",
"_score": 1.5342641,
"_source": {
"userName": "张三",
"userAddress": "深圳南山",
"userPhone": "1387897454"
},
"highlight": {
"userName.pinyin": [
"<em>张</em>三"
]
}
}
]
}
}- 如何修改index设置
http://172.168.1.11:11192/es_im_dev/_close POST 关闭索引
http://172.168.1.11:11192/es_im_dev/_settings PUT
{
"index": {
"analysis": {
"analyzer": {
"pinyin_analyzer": {
"tokenizer": "my_pinyin"
}
},
"tokenizer": {
"my_pinyin": {
"type": "pinyin",
"keep_separate_first_letter": true,
"keep_full_pinyin": true,
"keep_joined_full_pinyin": false,
"keep_original": true,
"limit_first_letter_length": 16,
"lowercase": true,
"remove_duplicated_term": true
}
}
}
}
}
http://172.168.1.11:11192/es_im_dev/_open POST 打开索引ES其它设置
- ES的内存设置
通过/elasticsearch-2.4.2/bin/elasticsearch.in.sh文件可修改ES的内存。
# check in case a user was using this mechanism
if [ "x$ES_CLASSPATH" != "x" ]; then
cat >&2 << EOF
Error: Don't modify the classpath with ES_CLASSPATH. Best is to add
additional elements via the plugin mechanism, or if code must really be
added to the main classpath, add jars to lib/ (unsupported).
EOF
exit 1
fi
ES_CLASSPATH="$ES_HOME/lib/elasticsearch-2.4.2.jar:$ES_HOME/lib/*"
# 内存大小设置
if [ "x$ES_MIN_MEM" = "x" ]; then
ES_MIN_MEM=256m
fi
if [ "x$ES_MAX_MEM" = "x" ]; then
ES_MAX_MEM=1g
fi
if [ "x$ES_HEAP_SIZE" != "x" ]; then
ES_MIN_MEM=$ES_HEAP_SIZE
ES_MAX_MEM=$ES_HEAP_SIZE
fi
# min and max heap sizes should be set to the same value to avoid
# stop-the-world GC pauses during resize, and so that we can lock the
# heap in memory on startup to prevent any of it from being swapped- ES日志设置
ES的日志遵循log4j的设置模式,有多种类型可选择。ES默认日志是每天滚动记录,默认类型(type)为dailyRollingFile的方式,通过修改elasticsearch-2.4.2/config/logging.yml文件可设置日志记录方式为rollingFile,并设置日志记录数量maxBackupIndex及大小maxFileSize即可有效减小日志大小、防止吃满硬盘。
appender:
console:
type: console
layout:
type: consolePattern
conversionPattern: "[%d{ISO8601}][%-5p][%-25c] %m%n"
file:
type: rollingFile
file: ${path.logs}/${cluster.name}.log
maxFileSize: 10000000
maxBackupIndex: 5
layout:
type: pattern
conversionPattern: "[%d{ISO8601}][%-5p][%-25c] %.10000m%n"