直接切入正题了,至于安装之类的文章,随便搜索一下也很多了。。不再赘述了
1. 找个你开心的地方,新建一个文件夹,进入这个文件夹
初始化一个代码仓库:
git init添加文件到仓库分为2步:
git add <file>
git commit -m <message>查看当前代码仓库的状态:
git status如果git status告诉我们有内容被修改了,那么查看当前仓库被修改的详情信息:
git diff2. 时光机器
git中表示当前版本的是HEAD指向的版本,所以,我们可以在版本中自由来回穿梭,使用命令
# 绝对回退方式,commit_id是使用sha1生成的不重复的字符串,以十六进制表示
# 回退的commit_id不用写全,写前面几位就可以,git会自动查找
git reset --hard <commit_id>
# 相对版本回退方式
git reset --hard HEAD^ # 回退到上一个版本
git reset --hard HEAD^^ # 回退到上上个版本
# 此时要回到上100个版本呢?
git reset --hard HEAD~100在使用时光机器之前,可以使用
git log查看提交历史, 以确定要回到哪个版本
重返未来,使用命令查看命令历史,以便确定要回到哪个版本
git reflog3. 工作区和版本库
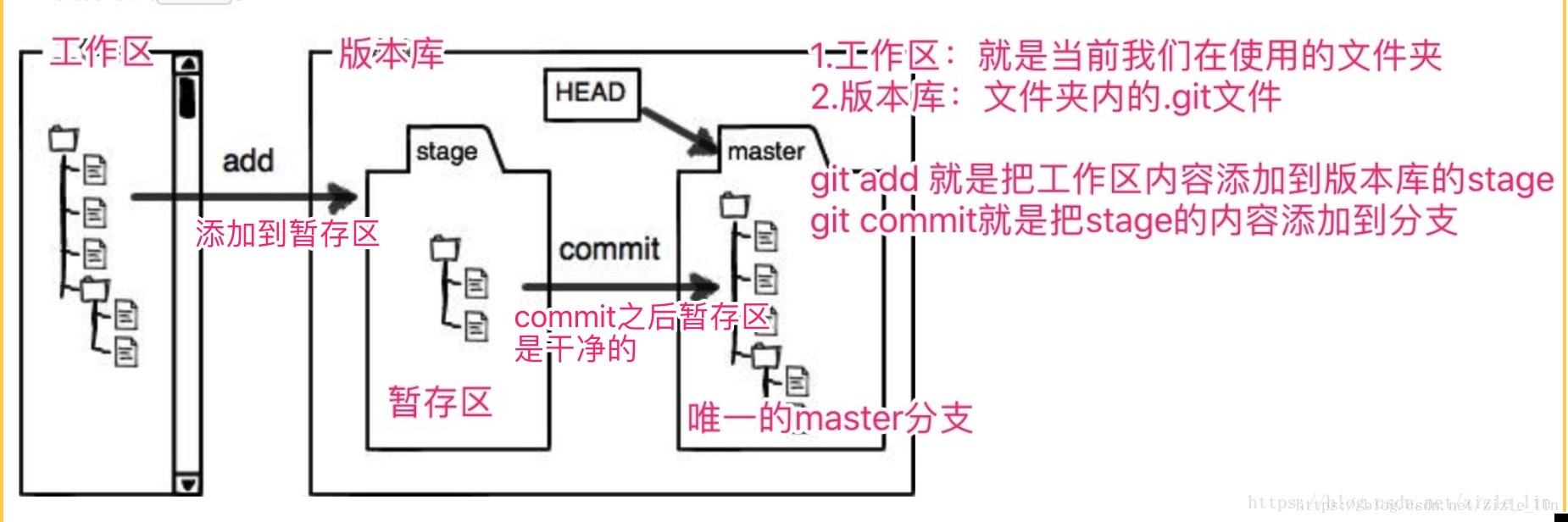
现有以下场景:
a. 改乱了工作区的文件,想丢弃修改使用
git checkout -- <file>
# 这个命令实质是用版本库的版本替换工作区的版本,无论是修改,还是删除,都可以还原。b. 你把改乱的文件添加到暂存区了,想放弃使用
git reset HEAD <file>这时回到了a的情况,我想你知道该怎么办了。。
c. 你把乱糟糟的文件添加到版本库了,这时可以使用2时光机器。
d. 你想删除掉一个看着不舒服的文件使用命令
git rm <file>
# 如果一个文件已经被提交到版本库,那么永远不用担心误删,但是,只能恢复文件到最新版本,你将会丢失最近一次提交后你修改的内容。4. git杀手级功能之----远程仓库:
Git是分布式版本控制系统,同一个Git仓库,可以分布到不同的机器上。怎么分布呢?最早,肯定只有一台机器有一个原始版本库,此后,别的机器可以“克隆”这个原始版本库,而且每台机器的版本库其实都是一样的,并没有主次之分。
实际情况往往是这样,找一台电脑充当服务器的角色,每天24小时开机,其他每个人都从这个“服务器”仓库克隆一份到自己的电脑上,并且各自把各自的提交推送到服务器仓库里,也从服务器仓库中拉取别人的提交。
5. 使用ssh连接github远程仓库
查看你当前机器用户主目录下是否有.ssh文件夹,有就直接使用,没有就使用命令生成
ssh-keygen -t rsa -C "[email protected]"在github设置公钥,实现仅可以添加公钥的电脑往仓库里推送代码

在github上创建一个远程仓库,这里也不再赘述了,同步本地仓库到远程仓库
#关联远程仓库:
git remote add origin git@server-name:path/repo-name.git
即
git remote add origin [email protected]:<github账户名>/<本地仓库文件夹名>.git
# 接着就可以将本地文件推送了
git push -u origin master
# 由于远程库是空的,我们第一次推送master分支时,加上了-u参数,Git不但会把本地的master分支内容推送的远程新的master分支,还会把本地的master分支和远程的master分支关联起来,在以后的推送或者拉取时就可以简化命令。
# 此后,每次本地提交后,只要有必要,就可以使用命令git push origin master推送最新修改当然,最理想的方式是先远程创建好仓库,本地克隆使用命令
# 两种方式进行克隆
# 使用https
git clone https://github.com/<github用户名>/<仓库名>.git
# 使用ssh
git clone [email protected]:<github用户名>/<仓库名>.git这么优秀的git,命令肯定不用全部我们自己写啊,我们在本地选择一处自己喜欢的位置,在本地写上git clone后面直接复制即可,进入你的github每一个仓库都有路径

使用ssh速度更快哦!
克隆下来,查看远程仓库信息,使用命令
git remote -v