本文转载自http://blog.csdn.net/elmo66/article/details/53735591,仅用作个人学习;如需转载请联系原创作者;如需删除,请见谅并联系本人。
词表示:
高维数据可以转换为连续的实数real valued概念向量,从而有效地从数据中捕获其潜在关系。例如,肺炎pneumonia和支气管炎bronchitis显然比肺炎和肥胖obesity更相关。在one-hot coding中,像这种不同代码之间的关系不能表示。
| one-hot coding扩展: 考虑一个词表V,里面的每一个词 wi都有一个编号 i∈{1,...,|V|},那么词 wi的one-hot表示就是一个维度为|V|的向量,其中第i个元素值非零,其余元素全为0。例如: w2=[0,1,0,...,0]T w3=[0,0,1,...,0]T 可以看到,这种表示不能反映词与词之间的语义关系,因为任意两个词的one-hot representation都是正交的;而且,这种表示的维度很高。 |
基于distributional hypothesis的词表示模型:
具有相似上下文的词,应该具有相似的语义。这个假说被称为distributional hypothesis。词的distributed representation(分布式表示)就是一种表示能够刻画语义之间的相似度并且维度较低的稠密向量表示,例如:
高兴=[0.2,1.6,−0.6,0.7,0.3]T
开心=[0.3,1.4,−0.5,0.9,0.2]T
这样,便可通过计算向量的余弦相似度,来反映出词的语义相似度。
一般基于矩阵。词与词的关系,将现有模型分为两大类:一类是syntagmatic models,一类是paradigmatic models。
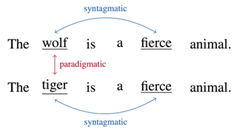
(一)syntagmatic models
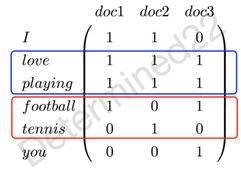
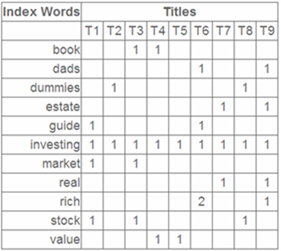
syntagmatic models关注的是词与词的组合关系(combinatorial relations),强调的是相似的词会共现于同一个语境(text region),比如在上图中,"wolf"和"fierce"就属于组合关系。为了建模组合关系,可以使用词-文档共现矩阵(co-occurrence matrix):矩阵的行指标代表词,列指标代表文档,矩阵的元素可以是词频等。例子,现在有三篇文档——doc1: I love playing football. doc2: I love playing tennis. doc3: You love playing football. 那么现在可以建立一个词-文档共现矩阵,元素值代表词频:
| Latent Semantic Analysis (LSA) 模型扩展: 优点:可以把原文本特征空间降维到一个低维语义空间;减轻一词多义和一义多词问题。 缺点:特别耗时 例子:"被子"和"被褥"是两个完全不同的维度,而"笔记本"(notebook or laptop?)又被表示成相同的维度,因此不能够体现文本中隐含的语义。 奇异值分解: 例子:

SVD |
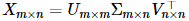
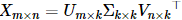 。
。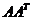 特征向量可求得矩阵U,由
特征向量可求得矩阵U,由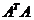 的特征向量可求得矩阵V,两者特征根是一样的,为
的特征向量可求得矩阵V,两者特征根是一样的,为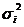 ,它们的开方是对角线上的值。
,它们的开方是对角线上的值。

(二)paradigmatic models
paradigmatic models关注的是词与词的替换关系(substitutional relations),强调的是相似的词拥有相似的上下文(context)而可以不同时出现。在上图中,"wolf"和"tiger"就属于替换关系。词-词共现矩阵(words-by-words co-occurrence matrix):行指标和列指标都是词。
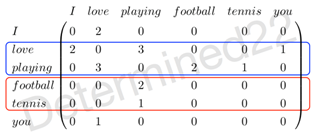
可以看出,"football"和"tennis"这两个较强替换关系的词的词表示是相似的,而"love"和"playing"这两个较强组合关系的词的词表示是不相似的。
神经概率语言模型NPLM:
近年来,基于神经网络来得到词表示的模型备受青睐。这类模型所得到的词的向量表示是分布式表示distributed representation,通常被称为word embedding(词嵌入;词向量)。神经概率语言模型(NPLM, Neural Probabilistic Language Model),通过训练语言模型,同时得到词表示。
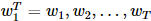
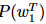

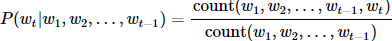
n-gram模型是一种近似策略,作了一个马尔可夫假设:认为目标词wt的条件概率只与其之前的n−1个词有关:
