15.有如下C语言程序段:
for(int k = 0; k < 1000; k++)
{
a[k] = a[k]+32;
}若数组a以及变量k均为int型,int型数据占4B,数据Cache采用直接映射 方式,数据区大小是1KB,块大小是16B,该程序段执行前Cache为空,则该程序段执行过程中,访问数组a的Cache的缺失率是:C
A. 1.25%
B. 2.5%
C. 12.5%
D. 25%
详解: a[k]的访问步骤是:先访问cache,cache缺失,之后从主存中取出一个块调入cache,这个块中的后几个数据都是命中的,本题中一个数据占4B,一个块大小是16B,这说明一个块中有4个数据,关键是后面还有一次写,这说明一次循环要八次访问cache,其中只有第一次是缺失的,后面七次都是命中的,所以缺失率是12.5%;
16 某存储器容量为64KB, 控字节编址, 地址4000H-5FFFH为ROM 区, 其余为RAM区.
若采用8K•4位的SRAM芯片进行设计, 则需要该芯片的数量是C
A. 7 B. 8 C. 14 D. 16
详解:.先求得rom区范围 5FFFH - 4000H = 1FFFH,因为1位可存0-1两种形式,H表示16进制,4位2进制为1位16进制,所以总的存储大小为 *
*
*
=
B(按字节编址) = 8KB, RAM区大小: 64KB - 8KB = 56KB ,所以芯片数则为 7 * 2 = 14
17.某指令格式如下所示。
| OP | M | I | D |
其中M为寻址方式,I为变址寄存器编号,D为形式地址。若采用先变址后间址的寻址方式,则操作数的有效地址是(C )。
A.I+D
B.(I)+D
C.((I)+D)
D.((I))+D
寻址方式:寻址方式
18.某计算机主存空间是4GB,字长是32位,按照字节编址。采用32位定长指令格式,若指令按照字边界对齐存放,则程序计数器PC和指令寄存器IR的位数至少分别是:B
A. 30, 30
B. 30, 32
C. 32, 30
D. 32, 32

分析:指令字长32位,毫无疑问,直接推导IR是32位。而4GB=232B4GB=232B主存空间,按B编址,则需要32位地址线。也即MAR需要32位。但是PC就不是!因为这里有一个条件,指令按照字边界对齐!
也即是说PC只用能够标识出不同的指令即可。于是计算指令有多少条:4GB/32bit=2304GB/32bit=230条。
所以,PC只需要有30位即可。
19.在无转发机制的五段基本流水线(取指、译码/读寄存器、运算、访存、写回寄存器)中,下列指令序列存在数据冒险的指令对是( B )。
I1:add R1,R2,R3;(R2)+(R3)→R1
I2:add R5,R2,R4;(R2)+(R4)→R5
I3:add R4,R5,R3;(R5)+(R3)→R4
I4:add R5,R2,R6;(R2)+(R6)→R5
A.I1和I2
B.I2和I3
C.I2和I4
D.I3和I4
详解:取指(IF)、译码(ID)、执行(EX)、访存(MEM)、写回寄存器堆(WB) 1和2明显排除 2和3可以考虑 2和4考虑 3和4排除
因为2和3有写读冲突,所以选 B ,转发机制就是为了解决冲突的,题目说无
20.单周期处理器中所有指令的指令周期为一个时钟周期。下列关于单周期处理器的叙述中,错误的是( A )。
A.可以采用单总线结构数据通路
B.处理器时钟频率较低
C.在指令执行过程中控制信号不变
D.每条指令的CPI为1
详解:本题不是很会,CPI:每条计算机指令执行所需的时钟周期 单周期时钟频率低是常识,关于A我看网上是这样的:
多数指令都需要两个过以上操作数,而且都需要在单周期内完成
21.下列关千总线设计的叙述中.错误的是 (A)
A 并行总线传输比串行总线传输速度快
B 采用信号线复用技术可减少信号线数量
C 采用突发传输方式可提高总线数据传输率
D 采用分离事务通信方式可提高总线利用率
详解:早期I/O速率都不高的情况下,并行速度快得多,效率更高,费时更少,优于串行。
随着信息技术的飞速发展。现在已经是高速串行的时代。
在高速状态下:并行口的几根数据线之间存在串扰,而并行口需要信号同时发送同时接收,任何一根数据线的延迟都会引起问题。而串行只有一根数据线,不存在信号线之间的串扰,而且串行还可以采用低压差分信号(一种振幅相等,相位相同,极性相反代表0和1的信号),可以大大提高它的抗干扰性,所以可以实现更高的传输速率,尽管并行可以一次传多个数据位,但是时钟远远低于串行。
突发传输:一般也称为数据突发,其在通信领域中一般指在短时间内进行相对高带宽的数据传输,即连续进行数据传输的方式
22.异常是指令执行过程中在处理器内部发生的特殊事件, 中断是来自处理器外部的请求事件
下列关千中断或异常情况的叙述中.错误的是 A
A. 访存时缺页属于中断
B. "整数除以O"属于异常
C. "DMA传送结束“属于中断
D."存储保护错“属于异常
异常 :是源自CPU执行指令内部的事件。如:非法操作码,地址越界,算术溢出,虚存系统的缺页,陷入指令等引起的事件。内部异常不可被屏蔽,一旦出现立马处理
中断 :来自CPU执行指令以外的事件。如:I/O中断,时钟中断等。
23 下列关于批处理系统的叙述中,正确的是 2和3
1. 批处理系统允许多个用户与计算机直接交互 (错误,没有交互)
2. 批处理系统分为单道批处理系统和多道批处理系统
3 中断技术使得多道批处理系统的IO设备可与CPU并行工作
批处理 分时,批处理
24.某单CPU系统中有输入和输出设备各1台. 现有3个并发执行的作业, 每个作业的输入、
计算和输出时间均分别为2ms、3ms和4ms, 且都按输入、计算和愉出的顺序执行.则执行完3
个作业需要的时间最少是 B
A. ISms B. 17ms C. 22ms D. 27ms
详解 : 2+ 3 + 4+ 4+ 4 = 17
25.系统中有3个不同的临界资源R1、R2和R3,被4个进程p1、p2、p3及p4共享。各进程对资源的需求为:
p1申请R1和R2,p2申请R2和R3,p3申请R1和R3,p4申请R2。若系统出现死锁,则处于死锁状态的进程数至少是( C)。
A.1
B.2
C.3
D.4
详解:要么没有死锁,要么这里最少就是3个处于死锁
临界资源:一次仅允许一个进程使用的资源称为临界资源
26.某系统采用改进型CLOCK置换算法,页表项中字段A为访问位,M为修改位。
A=0表示页最近没有被访问,A=1表示页最近被访问过。M=0表示页没有被修改过,M=1表示页被修改过。
按(A,M)所有可能的取值,将页分为四类:(0,0)、(1,0)、(0,1)和(1,1),则该算法淘汰页的次序为 A
A.(0,0),(0,1),(1,0),(1,1)
B.(0,0),(1,0),(0,1),(1,1)
C.(0,0),(0,1),(1,1),(1,0)
D.(0,0),(1,1),(0,1),(1,0)
简单CLOCK和改进型CLOCK区别:改进型多了一个修改位,简单只有一个访问位
27.使用TSL指令实现进程互斥的伪代码如下: B
do
{
...
while(Test_And_Set_Lock(&lock)); //特别注意分号,以及传递的参数是引用参数
//临界区
lock = False;
//剩余区
}while(True)
下列与该实现机制相关的叙述中,正确的是:
A. 退出临界区的进程负责唤醒阻塞态进程
B. 等待进入临界区的进程不会主动放弃CPU
C. 上述伪代码满足“让权等待”的同步准则
D. while(Test_And_Set_Lock(&lock))语句应在关中断状态下执行
详解:自旋锁 :自旋锁--Test and Set Clock机制分析
28.某进程的段表内容如下所示。
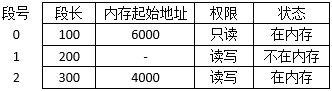
当访问段号为2、段内地址为400的逻辑地址时,进行地址转换的结果是(D )。
A.段缺失异常
B.得到内存地址4400
C.越权异常
D.越界异常
详解:因为能找到段号,所以A排除, 当访问的地址大于段长时便产生越界中断,选D
29.
某进程访问页面的序列如下:
...,1,3,4,5,6,0,3,2,3,2,→t时刻←,0,4,0,3,2,9,1,......,1,3,4,5,6,0,3,2,3,2,→t时刻←,0,4,0,3,2,9,1,...若工作集窗口大小是6,则在t时刻的工作集为:A
A. {6,0,3,2}
B. {2,3,0,4}
C. {0,4,3,2,9}
D. {4,5,6,0,3,2}
详解:实际就是打洞的纸片往右移动,所以是603232 但是32是叠加的
30. 进程P1和进程P2均包含并发执行的线程,部分伪代码描述如下:
//进程P1
int x = 0;
Thread1()
{
int a;
a = 1;
x+=1;
}
Thread2()
{
int a;
a = 2;
x += 2;
}
//进程P2
int x = 0
Thread3()
{
int a;
a = x;
x += 3;
}
Thread4()
{
int b;
b = x;
x += 4;
}下列选项中,需要互斥执行的操作是:(C)
A. a = 1与a = 2
B. a = x与b = x
C. x += 1与x += 2
D. x += 1与x += 3
详解:基本操作。。。
参考:进程并发与互斥性问题小结
31.关于SPOOLing技术的叙述,错误的是:D
A. 需要外存的支持
B. 需要多道程序设计技术的支持
C. 可以让多个作业共享一台独占设备
D. 由用户作业控制设备与输入/输出井之间的数据传送。
分析:输入井,输出井就是在磁盘(外存)开辟的存储空间,因此需要外存的支持,A项正确。
要用输入输出进程模拟IO的输入输出控制,单道程序环境下无法满足这一点,因此我们说SPOOLing需要多道程序的支持。B项对。
C项不用说,这就是设计的目的。
D项是错误的,因为输入输出进程是系统体用的,不是用户作业控制设备,系统提供了输入输出的进程模拟控制。
32.关于管程的叙述中,错误的是:A
A. 管程只能用于实现进程的互斥
B. 管程是由编程语言支持的进程同步机制
C. 任何时刻只有一个进程在管程中执行
D. 管程中定义的变量只能被管程内的过程访问
33 - 4 1的 图
这里是同一个图,只是下面这个图比较完整

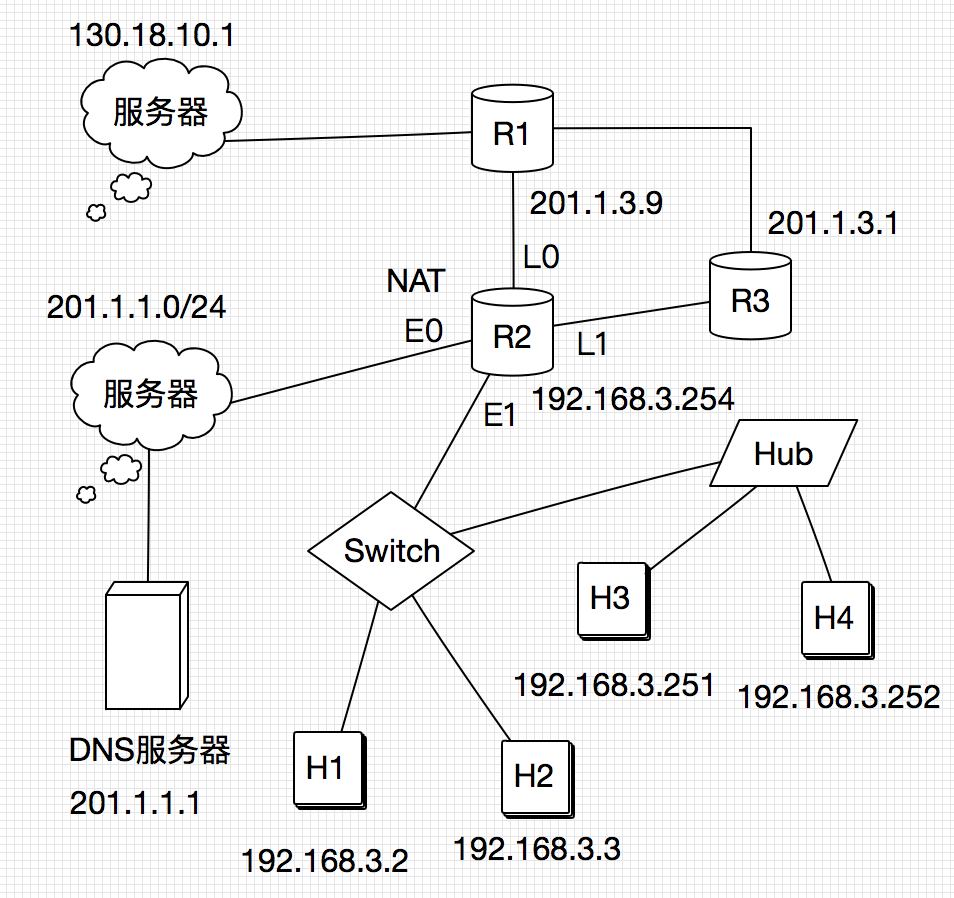
33.在OSI参考栈型中. RI 、switch、Hub实现的最高功能层分别是 C
A. 2 、2 、1 B. 2 、2 、2 c. 3 、2 、1 D. 3 、2 、2
详解:R1就是路由器,这里比较难的就是集线器在那一层,比较模糊是物理层还是数据链路层,只能记了,就是物理层
34.若连接R2和R3链路的频率带宽为8kHz,信噪比为30dB,该链路实际数据传输速率约为理论最大数据传输速率的50%,则该链路的实际数据传输速率约是(C )。
A.8kbps
B.20kbps
C.40kbps
D.80kbps
“带宽”有两个意思,
一是信号自身最高频率减最低频率的差值(单位是“Hz”),香农定理C=Wlog2(1+S/N)中的W是带 宽,单位是"Hz";
二是信息传输速率的最大值(单位是“bps”),比如现在市场上说的2M带宽就是2Mbps的意思。
具体区别要看语境。
详解:看到信噪比,就要用到香农定理C=Wlog2(1+S/N),信噪比r换算分贝数:30dB=10lg(r) ====》 r=1000
则理论 C(Rmax)=8K*log(1+1000)=8k*10=80k (说明 2的10次方等于1024) 实际 = 80 * 50% = 40Kbps
35.若主机H2向主机H4发送一个数据帧,主机H4向主机H2立即发送一个确认帧,则除H4外,从物理层上能够收到该确认帧的主机还有:D
A. 仅H2
B. 仅H3
C. 仅H1,H2
D. 仅H2,H3
分析:只是单纯考察数据链路层帧的传送时的过程。当H2向H4传递时,将会把MAC地址告诉Switch,这样当H4发回确认帧时,可以直接一对一传到H2.但是这里要注意,H4经过Hub发回确认帧时,H3也会偷听到。即,Hub是广播的方式,包括H4自己也会听到,只不过这里说除了H4,那么H2,H3可以收到该确认帧。 难点:集线器广播
36.若Hub再生比特流过程中,会产生1.535us延时,信号传播速度为200m/us,不考虑以太网帧的前导码,则H3与H4之间理论上可以相距的最远距离是(B )
A.200m
B.205m
C.359m
D.512m
最小帧长=争用期∗数据传输速率
这部分理解得不是很透彻,有时间在研究
37.假设R1、R2、R3采用RIP协议交换路由信息,且均已收敛。若R3检测到网络201.1.2.0/25不可达,并向R2通告一次新的距离向量,
则R2更新后,其到达该网络的距离是( B )。
A.2
B.3
C.16
D.17
个人理解:有两个可能3或者16, 3的情况是R3没有告诉R1不可达,所以R1中还是2,当R2更新路由后,从R1中知道到201节点距离为2,所以 + 1 = 3.还有一种可能就是R3也告诉R1不可达了,所以 =16. 最后想法:均已收敛,我判定就是在收敛的时候,R3还是可达201节点的,但是在下一个30秒之前,R3检测到了不可达201,但是还是没有发送给R1,所以R2从R1中知道还是2,所以才会加+1 = 3
38.假设连接R1、R2和R3之间的点对点链路使用201.1.3.x/30地址,当H3访问Web服务器S时,
R2转发出去的封装HTTP请求报文的IP分组的源IP地址和目的IP地址分别是( D)。
A.192.168.3. 251,130.18.10.1
B.192.168.3. 251,201.1. 3.9
C.201.1. 3.8,130.18.10.1
D.201.1. 3.10,130.18.10.1
/30 的作用(即子网掩码,注意1的个数可以不连续)
解:192.168.3.X这个属于局域网本地地址,201.1.3.X才属于网络地址,所以排除A,B、至于为什么选D,因为1的个数为2,根据 8 4 2 1,如果选C就只是1个1,201.1.3.x/29的话就是选C
39.假设H1与H2的默认网关和子网掩码均分别配置为192.168.3. 1和255.255.255.128,
H3与H4的默认网关和子网掩码均分别配置为192.168.3. 254和255.255.255.128,则下列现象中可能发生的是( c )。
A.H1不能与H2进行正常IP通信
B.H2与H4均不能访问Internet
C.H1不能与H3进行正常IP通信
D.H3不能与H4进行正常IP通信
解:关于A,H1与H2是链接在交换机上的,所以可以进行正常通讯,关于B,H2,H4都有通过集线器,或者交换机连接到路由器,
所以都能访问Internet,关于D,H3与H4链接到同一集线器,是属于内局域网通讯,肯定可以通讯,所以排除法选C
H1 : 192.168.3.2 H3:192.168.3.251 的本地地址
因为H1和H3不是链接到同一交换机或者集线器的,所以要把本地地址转为网络地址
网络地址 = 本地地址 + 子网掩码 算出来
以下先把本地地址换为2进制,
128 64 32 16 8 4 2 1
H1 0 0 0 0 0 0 1 0
H3 1 1 1 1 1 011 255 - 4 即4号位为0,其余全为1
因为子网掩码都一样,很明显他们网络地址是不一样的,所以不能够通讯,这里计算就略了,所以C可能发生。
40.假设所有域名服务器均采用迭代查询方式进行域名解析。当H4访问规范域名为www.abc.xyz.com的网站时,
域名服务器201.1. 1.1在完成该域名解析过程中,可能发出DNS查询的最少和最多次数分别是( )。
A.0,3
B.1,3
C.0,4
D.1,4
解:如果在域名服务器中有缓存过的解析地址,则查询次数为0次,如果一直没有,因为有4级域名,所以最多缺失4次,需要访问4次根域名服务器
41.假设图中的H3访问Web服务器S时,S为新建的TCP连接分配了20KB(K=1024)的接收缓存,最大段长MSS=1KB,平均往返时间RTT=200ms。H3建立连接时的初始序号为100,且持续以MSS大小的段向S发送数据,拥塞窗口初始阈值为32KB;S对收到的每个段进行确认,并通告新的接收窗口。假定TCP连接建立完成后,S端的TCP接收缓存仅有数据存入而无数据取出。请回答下列问题。
(1)在TCP连接建立过程中,H3收到的S发送过来的第二次握手TCP段的SYN和ACK标志位的值分别是多少?确认序号是多少?
(2)H3收到的第8个确认段所通告的接收窗口是多少?此时H3的拥塞窗口变为多少?H3的发送窗口变为多少?
(3)当H3的发送窗口等于0时,下一个待发送的数据段序号是多少?H3从发送第1个数据段到发送窗口等于0时刻为止,平均数据传输速率是多少(忽略段的传输延时)?
(4)若H3与S之间通信已经结束,在t时刻H3请求断开该连接,则从t时刻起,S释放该连接的最短时间是多少?
解答:
(1)第二次握手TCP段的SYN=1,(1分)ACK=1;(1分)确认序号是101。(1分)
(2)题目规定S对收到的每个段(MSS大小的段)进行确认,并通告新的接收窗口,而且TCP接收缓存仅有数据存入而无数据取出。
H3收到的第8个确认段所通告的接收窗口是20-8=12KB;(1分)在慢开始算法里,发送方H3先设置拥塞窗口cwnd=1KB,
接下来每收到一个对新报文段的确认就使发送方的拥塞窗口加1KB。H3共收到8个确认段,所以此时H3的拥塞窗口变为1+8=9KB;(1分)发送窗口=min{拥塞窗口,接收窗口},所以H3的发送窗口变为min{9,12}=9KB。(1分)
(3)TCP是用字节作为窗口和序号的单位。当H3的发送窗口等于0KB时,也就是接收窗口等于0KB时,
下一个待发送段的序号是20K+101=20×1024+101=20581;(疑问:tcp经历了3次握手,第一次seq = 100. 第二次握手 seq = 101 , 第三次握手 = 102,为什么这里不是加103,难道我该死记硬背理解为发送数据的时候,以第1次seq为准,然后加1吗)(1分)H3从发送第1个段到发送窗口等于0KB时刻为止,经过五个传输轮次,(1.窗口拥塞为1 2.窗口拥塞为2, 3.窗口拥塞为4 4.窗口拥塞为8 5.拥塞窗口5,慢开始)
每个传输轮次的时间就是往返RTT,因此平均数据传输速率是20KB/(5×200ms)=20KB/s=20.48kbps。(1分)
(4)通信结束后,H3向S发送连接释放报文段。S收到H3的连接释放报文段后,马上发出确认报文段。此时S已经没有数据需要传输,于是它也马上发出连接释放报文段。H3在收到S的连接释放报文段后,发出确认报文段。S在收到这份确认后就释放TCP连接。因此从t时刻起,S释放该连接的最短时间是:H3的连接释放报文段传送到S的时间+S的连接释放报文段传送到H3的时间+H3的确认报文段传送到S的时间=1.5×200ms=300ms。(1分)
(虽然是4次挥手,但是第二,第三次挥手都是从同一端,同时发出的)
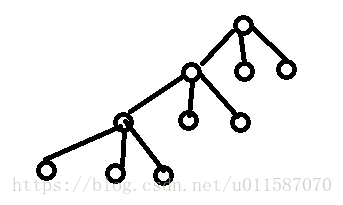
42.如果一棵非空k(k≥2)叉树T中每个非叶子结点都有k个孩子,则称T为正则k叉树,请
回答下列问题并给出推导过程
(1)若T有m个非叶结点. 则T中的叶结点有多少个?
(2)若T的高度为h(单结点的树h=1). 则T的结点数最多为多少个?最少为多少个?.
(答案要点)
(I)根据定义,正则K叉树中仅含有两类结点: 叶结点(个数记为)和度为K的分支结点(个数
记为),树T中的结点总数n =
+
=
+ m , 树中所含的边数e = n -1 , 这些边均为m个度为K的结点
发出的,即 e = m x k , 整理得: + m = m x k + l, 故
= (k- 1) x m + l . (3分)
(2)高度为h的正则K叉树T中,含最多结点的树形为:除第h层外,第1 到第 h- 1 层的结点都是
度为K的分支结点,而第h层均为叶结点,即树是“满”树,此时第j ()层结点数为
,节点总数
为:


当K =3 ,最少如图:
43.已知由n(n≥2)个正整数构成的集合A={ak|0≤k<n},将其划分为两个不相交的子集A1和A2,元素个数分别是n1和n2,A1和A2中元素之和分别为S1和S2。
设计一个尽可能高效的划分算法,满足|n1-n2|最小且|S1-S2|最大。要求:
(1)给出算法的基本设计思想。
(2)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。
(3)说明你所设计算法的平均时间复杂度和空间复杂度。



44.假定CPU主频为50MHz,CPI为4。设备D采用异步串行通信方式向主机传送7位ASCII字符,通信规程中有1位奇校验位和1位停止位,从D接收启动命令到字符送入I/O端口需要0.5ms。请回答下列问题,要求说明理由。
(1)每传送一个字符,在异步串行通信线上共需传输多少位?在设备D持续工作过程中,每秒钟最多可向I/O端口送入多少个字符?
(2)设备D采用中断方式进行输入/输出,示意图如下:

I/O端口每收到一个字符申请一次中断,中断响应需10个时钟周期,中断服务程序共有20条指令,其中第15条指令启动D工作。若CPU需从D读取1000个字符,则完成这一任务所需时间大约是多少个时钟周期?CPU用于完成这一任务的时间大约是多少个时钟周期?在中断响应阶段CPU进行了哪些操作?
解答:
(1)每传送一个ASCII字符,需要传输的位数有1位起始位、7位数据位(ASCII字符占7位)、1位奇校验位和1位停止位,故总位数为1+7+1+1=10。(2分) --这里题目有点奸诈,没有提到起始位,以后默认传输数据都有起始位
I/O端口每秒钟最多可接收1000/0.5=2000个字符。(1分) 1s = 1000ms
【评分说明】对于第一问,若考生回答总位数为9,则给1分。
(2)一个字符传送时间包括:设备D将字符送I/O端口的时间、中断响应时间和中断服务程序前15条指令的执行时间。时钟周期为1/(50MHz)=20ns,设备D将字符送I/O端口的时间为0.5ms/20ns=2.5×104个时钟周期。一个字符的传送时间大约为2.5×104+10+15×4=25070个时钟周期。完成1000个字符传送所需时间大约为1000×25070=25070000个时钟周期。(3分)
时钟周期 = 1 / 主频 CPI为4 :一条指令需要4个时钟周期
CPU用于该任务的时间大约为1000×(10+20×4)= 9×104个时钟周期。(1分) 和前一问是有明显区别的,这个没有读取,是完成,前面是读取。
在中断响应阶段,CPU主要进行以下操作:关中断、保护断点和程序状态、识别中断源。(2分)
【评分说明】
①位于第一问,若答案是25070020,则同样给分;若答案是25000000或25000020,则给2分。如果没有给出分布计算步骤,但算式和结果正确,同样给分。
②对于第三问,只要回答关中断和保护断点,就给2分,其他答案酌情给分。
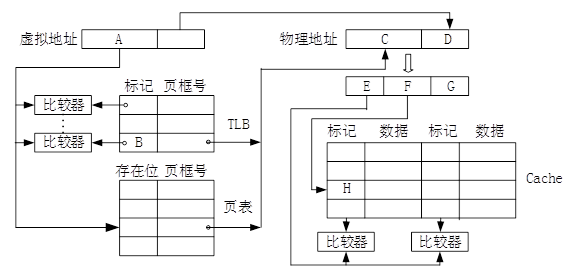
45.某计算机采用页式虚拟存储管理方式,按字节编址,虚拟地址为32位,物理地址为24位,页大小为8KB;TLB采用全相联映射;Cache数据区大小为64KB,按2路组相联方式组织,主存块大小为64B。存储访问过程的示意图如下。
请回答下列问题。
(1)图中字段A~G的位数各是多少?TLB标记字段B中存放的是什么信息?
(2)将块号为4099的主存块装入到Cache中时,所映射的Cache组号是多少?对应的H字段内容是什么?
(3)Cache缺失处理的时间开销大还是缺页处理的时间开销大?为什么?
(4)为什么Cache可以采用直写(Write Through)策略,而修改页面内容时总是采用回写(Write Back)策略?
解答:
(1)页大小为8KB,页内偏移地址为13位,故A=B=32-13=19;D=13;C=24-13=11;主存块大小为64B,
故G=6。2路组相联,每组数据区容量有64B×2=128B,共有64KB/128B=512组,故F=9;E=24-G-F=24-6-9=9。
因而A=19,B=19,C=11,D=13,E=9,F=9,G=6。(各1分,共7分)
(
因为是按字节编址B 3 + 10 = 13位)
(A = B = 有多少虚拟的页号,即页号的取值范围 D为页内偏移,即物理地址一块的大小)
(C为物理地址的页框号)
TLB中标记字段B的内容是虚页号,表示该TLB项对应哪个虚页的页表项。(1分)
(2)块号4099=00 0001 0000 0000 0011B,因此,所映射的Cache组号为0 0000 0011B=3,(1分)对应的H字段内容为0 0000 1000B。(1分)
(3)Cache缺失带来的开销小,而处理缺页的开销大。(1分)因为缺页处理需要访问磁盘,而Cache缺失只要访问主存。(1分)
【评分说明】对于(3)中第2问,若考生回答因为缺页需要软件实现而Cache缺失用硬件实现,则同样给分。
(4)因为采用直写策略时需要同时写快速存储器和慢速存储器,而写磁盘比写主存慢很多,所以,在Cache-主存层次,Cache可以采用直写策略,而在主存-外存(磁盘)层次,修改页面内容时总是采用回写策略。(2分)