背景
前面一篇总结了Serializable的序列化与反序列化,现在接着总结XML。主要内容:XML基本的序列化与反序列化方法、一些注意事项、以及自定义了一个XML注解框架(简洁代码,解放双手)。
XML的序列化与反序列化
先与Serializable进行简单的对比:
- Serializable存储的文件,打开后无法正常查看,安全性高。xml文件可通过文本编辑器查看与编辑,可读性高(浏览器会格式化xml文件,更方便查看),安全性低;
- Serializable文件通过了签名,只能在自己的程序中反序列化,或RMI(Remote Method Invocation,远程调用)来解析。xml文件,只要打开后知道标签结构,谁都可以解析出来,跨平台性好;
- 上面一篇提到过,xml文件有很多成双成对的tag标签,所以会导致xml文件所需的存储空间更大(Json较xml最大的优势也就是,没有那么多冗余的tag标签)
下面要对PersonBean的List集合进行序列化与反序列化。
一个标准的JavaBean——PersonBean.java
public class PersonBean {
private int id;
private String name;
private boolean isMale;
private String interest;
public PersonBean() {
}
public PersonBean(int id, String name, boolean isMale, String interest) {
this.id = id;
this.name = name;
this.isMale = isMale;
this.interest = interest;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public boolean isMale() {
return isMale;
}
public void setIsMale(boolean isMale) {
this.isMale = isMale;
}
public String getInterest() {
return interest;
}
public void setInterest(String interest) {
this.interest = interest;
}
@Override
public String toString() {
return name + '[' + id + ", " + isMale + ", " + interest + ']';
}
}List集合中三个PersonBean对象:
PersonBean person1 = new PersonBean(101, "张三", true, "<游戏>CS、红警</游戏>,运动<篮球、游泳、健身>");
PersonBean person2 = new PersonBean(102, "小丽", false, "");
PersonBean person3 = new PersonBean(103, "乔布斯", true, "<编程>IOS、Android、Linux</编程>,运动<健身、登山、游泳>");序列化后,persons.xml内容:
<?xml version='1.0' encoding='UTF-8' ?><!--********注释:人员信息********--><Persons date="2016-07-24 22:09:56"><person id="101"><name>张三</name><isMale>true</isMale><interest><游戏>CS、红警</游戏>,运动<篮球、游泳、健身></interest></person><person id="102"><name>小丽</name><isMale>false</isMale><interest></interest></person><person id="103"><name>乔布斯</name><isMale>true</isMale><interest><编程>IOS、Android、Linux</编程>,运动<健身、登山、游泳></interest></person></Persons>浏览器查看结果:(注意与上面xml中interest为”“的内容比较)

序列化
使用系统自带的进行XmlSerializer进行序列化,把集合转变成xml文件,没啥好说的,直接上代码:
import android.util.Xml;
import org.xmlpull.v1.XmlSerializer;
...
private void serialize(List<PersonBean> personList, File file) {
FileOutputStream fileOS = null;
XmlSerializer serializer = Xml.newSerializer();
StringWriter writer = new StringWriter();
try {
fileOS = new FileOutputStream(file);
serializer.setOutput(writer);
// 第二参数,表示是否定义了外部的DTD文件。
// true -xml中为yes,没有定义,默认值;
// false-xml中为no,表示定义了
// null -xml中不显示
// serializer.startDocument("UTF-8", true);
serializer.startDocument("UTF-8", null);
serializer.comment("********注释:人员信息********");
serializer.startTag("", "Persons");
serializer.attribute("", "date", new SimpleDateFormat("yyyy-MM-dd HH:mm:ss", Locale.CHINESE).format(new Date()));
for (PersonBean person : personList) {
serializer.startTag("", "person");
serializer.attribute("", "id", String.valueOf(person.getId()));
serializer.startTag("", "name");
serializer.text(person.getName());
serializer.endTag("", "name");
serializer.startTag("", "isMale");
serializer.text(String.valueOf(person.isMale()));
serializer.endTag("", "isMale");
serializer.startTag("", "interest");
serializer.text( person.getInterest());
serializer.endTag("", "interest");
serializer.endTag("", "person");
}
serializer.endTag("", "Persons");
serializer.endDocument();
fileOS.write(writer.toString().getBytes("UTF-8"));
toast("xml序列化成功"); // -------吐司,可删,下同-------
} catch (IOException e) {
e.printStackTrace();
toast("xml序列化失败,原因:" + e.getMessage()); // --------------
}finally {
if (fileOS != null) {
try {
fileOS.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}反序列化
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserException;
...
private List<PersonBean> unserialize(File file) {
List<PersonBean> list = new ArrayList<>(0);
FileInputStream fileIS = null;
try {
fileIS = new FileInputStream(file);
XmlPullParser xpp = Xml.newPullParser();
xpp.setInput(fileIS, "UTF-8");
int eventType = xpp.getEventType();
PersonBean person = null;
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_TAG:
String tagName = xpp.getName();
if ("person".equals(tagName)) {
person = new PersonBean();
int id = Integer.parseInt(xpp.getAttributeValue("", "id"));
person.setId(id);
} else if ("name".equals(tagName)) {
person.setName(xpp.nextText());
} else if ("isMale".equals(tagName)) {
person.setIsMale(new Boolean(xpp.nextText()));
} else if ("interest".equals(tagName)) {
person.setInterest(xpp.nextText());
}
break;
case XmlPullParser.END_TAG:
if ("person".equals(xpp.getName())) {
list.add(person);
}
break;
}
eventType = xpp.next();
}
toast("解析完毕");
} catch (XmlPullParserException | IOException e) {
e.printStackTrace();
toast("解析失败,原因:" + e.getMessage());
}finally {
if (fileIS != null) {
try {
fileIS.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return list;
}结果打印到界面上,没问题

注意事项
反序列化中next()、getName()、getText()、nextText()的理解
next():进入到下一个待解析事件,返回事件的类型。
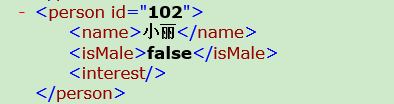
以上图为例,假设next()进入到了<person id="102">,next()下去,事件依次是:<name> 小丽 </name> <isMale> false </isMale> <interest> </interest> </person>getName():返回标签的名称,不包含”/”及attribute属性值。
如果是非标签,则返回null。如果上面的解析事件<person id="102">返回person,小丽返回null,</name>返回name。
注:标签代表当前的事件类型eventType是XmlPullParser.START_TAG或XmlPullParser.END_TAG;TEXT代表eventType是XmlPullParser.TextgetText():返回非标签,即TEXT的内容值。如果是标签,返回null。
nextText():下一个Text的内容值,但不是一直找下去。如果下一个事件不是TEXT,是END_TAG,则返回”“。
它的实现代码就是酱紫的(参考:API之家):if(getEventType() != START_TAG) { throw new XmlPullParserException( "parser must be on START_TAG to read next text", this, null); } int eventType = next(); if(eventType == TEXT) { String result = getText(); eventType = next(); if(eventType != END_TAG) { throw new XmlPullParserException( "event TEXT it must be immediately followed by END_TAG", this, null); } return result; } else if(eventType == END_TAG) { return ""; } else { throw new XmlPullParserException( "parser must be on START_TAG or TEXT to read text", this, null); }如:上面的小丽的
<interest></interest>,当前事件在<interest>上,如果用xpp.next(); String text = xpp.getText();text得到的是null(空对象,非字符串”null”),因为getText()是针对
</interest>标签了,所以返回null。这肯定不是我们想要的,当然我们可以用判断来处理。显然麻烦,而nextText()返回的就是”“,That is what I want。当然,如果在确定都有值的情况下,那修改成如下这样,要比nextText()少了些判断,运行效率会高一点点点:
xpp.next(); person.setInterest(xpp.getText()); xpp.next();Bean中对象字段为null的处理
假设,万一,上面的PersonBean对象一不小心中传入了一个空对象null,如name或interest被设置成了null,在序列化时要报空指针异常。
如果为了代码代码的健壮性,还是有必要做处理的。个人提供两种方法:- 在Bean的字段定义时赋默认初值,并在构造方法和setter中进行非null判断。
- 用一个固定值表示null,如字符串”null”,在序列化与反序列化时进行null和”null”的判断。
序列化:serializer.text(person.getInterest() == null ? "null" : person.getInterest());
反序列化:person.setInterest("null".equals(xpp.getText()) ? null : xpp.getText());
CDATA数据的处理
上面特意用了跟标签一样的字符串作为信息输入。如:"<游戏>CS、红警</游戏>,运动<篮球、游泳、健身>"。在序列化的时候使用的是serializer.text(),此方法会自动把尖括号变成转义字符,
"<"转"<",">"转">",在上面的xml文件内容中就可以看到了很多这些转义字符。而在浏览器中,会自动换成原字符,让你看起来舒服。而我们的getText()也会识别转义字符,并自动转换成原字符(nextText()内部用的也是getText())。小曲:如果你把浏览器中的内容复制到xml文件中,然后去解析,肯定报错。
解决小曲问题。就要使用另一个方法cdsect()来序列化,它会把内容用
<![CDATA[和]]>包裹起来,表示character data,不用xml解析器解析的文本数据。serializer.cdsect(person.getInterest());比较一下:
text()的xml文件内容及浏览器格式化:<interest><游戏>CS、红警</游戏>,运动<篮球、游泳、健身></interest>
cdsect()的xml文件内容及浏览器格式化:<interest><![CDATA[<游戏>CS、红警</游戏>,运动<篮球、游泳、健身>]]></interest>
CDATA的反序列化:
经测试,使用原来的nextText()可以直接解析出来。也可以使用看上去更专业一点的nextToken()和getText(),这里,空字符串的CDATA也能解析出来。xpp.nextToken(); person.setInterest(xpp.getText());
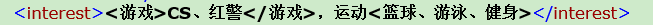

自定义XML注解框架XmlUtils
前一篇提出来说可以用注解+反射来简化代码,ButterKnife也家喻户晓的注解框架,它们的原理都差不多,很简单:
- 给类和字段添加注解,注解信息用来表示标签名。无注解的字段不序列化
- 通过反射获取字段值
XmlUtils注解框架
XmlUtils注解框架共三个类:类注解、字段注解、工具类。
工具类包含四个主要方法,实现四大功能:Bean对象 ←→ xml文件流,List集合 ←→ xml文件流
XmlClassInject.java
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* Created by Ralap on 2016/7/24.
*/
@Retention(RetentionPolicy.RUNTIME) // 生命周期:运行时
@Target(ElementType.TYPE) // 作用的目标:类
public @interface XmlClassInject {
String value();
}XmlFiledInject.java
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* Created by Ralap on 2016/7/24.
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface XmlFiledInject {
String value();
}XmlUtils.java
import android.util.Xml;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlSerializer;
import java.io.InputStream;
import java.io.StringWriter;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
/**
1. Created by Ralap on 2016/7/24.
*/
public class XmlUtils {
/**
* Bean对象序列化成xml对应的字节数组
*/
public static <T> byte[] serialize_bean2Xml(final T bean) throws Exception{
StringWriter writer = new StringWriter();
XmlSerializer serializer = Xml.newSerializer();
// 获取类上的注解信息
Class clazz = bean.getClass();
XmlClassInject classAnno = (XmlClassInject) clazz.getAnnotation(XmlClassInject.class);
if (null == classAnno) {
throw new Exception("Bean类上无@XmlClassInject注解名称");
}
String beanName = classAnno.value();
serializer.setOutput(writer);
serializer.startDocument("UTF-8", true);
serializer.startTag("", beanName);
// 获取字段上的注解信息
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
XmlFiledInject fieldAnno = field.getAnnotation(XmlFiledInject.class);
if (null == fieldAnno) {
continue;
}
String tagName = fieldAnno.value();
serializer.startTag("", tagName);
field.setAccessible(true);
serializer.text(String.valueOf(field.get(bean)));
serializer.endTag("", tagName);
}
serializer.endTag("", beanName);
serializer.endDocument();
return writer.toString().getBytes("UTF-8");
}
/**
* List集合对象转换成xml序列化中的一部分。如List中bean的序列化
*/
public static <T> byte[] serialize_list2Xml(final List<T> list) throws Exception{
StringWriter writer = new StringWriter();
XmlSerializer serializer = Xml.newSerializer();
// 获取类上的注解信息
Class clazz = list.get(0).getClass();
XmlClassInject classAnno = (XmlClassInject) clazz.getAnnotation(XmlClassInject.class);
if (null == classAnno) {
throw new Exception("Bean类上无@XmlClassInject注解名称");
}
String beanName = classAnno.value();
// 获取字段上的注解信息,并暴力反射字段
Field[] fields = clazz.getDeclaredFields();
List<String> tagNames = new ArrayList<>(fields.length);
for (Field field : fields) {
XmlFiledInject fieldAnno = field.getAnnotation(XmlFiledInject.class);
if (null == fieldAnno) {
tagNames.add(null);
} else {
tagNames.add(fieldAnno.value());
field.setAccessible(true);
}
}
serializer.setOutput(writer);
serializer.startDocument("UTF-8", true);
serializer.startTag("", beanName + "List");
for (T bean : list) {
serializer.startTag("", beanName);
for (int i = 0; i < fields.length; i++) {
String name = tagNames.get(i);
if (null != name) {
serializer.startTag("", name);
Field field = fields[i];
serializer.text(field.get(bean).toString());
serializer.endTag("", name);
}
}
serializer.endTag("", beanName);
}
serializer.endTag("", beanName + "List");
serializer.endDocument();
return writer.toString().getBytes("UTF-8");
}
/**
* 把xml输入流反序列化成Bean对象
*/
public static <T> T unserialize_xml2Bean(final InputStream xmlIn, final Class clazz) throws Exception {
T bean = null;
XmlPullParser xpp = Xml.newPullParser();
xpp.setInput(xmlIn, "UTF-8");
XmlClassInject classAnno = (XmlClassInject) clazz.getAnnotation(XmlClassInject.class);
if (null == classAnno) {
throw new Exception("Bean类上无@XmlClassInject注解名称");
}
String beanName = classAnno.value();
Field[] fields = clazz.getDeclaredFields();
List<String> tagNames = new ArrayList<>(fields.length);
for (Field field : fields) {
XmlFiledInject fieldAnno = field.getAnnotation(XmlFiledInject.class);
if (null == fieldAnno) {
tagNames.add(null);
} else {
tagNames.add(fieldAnno.value());
}
field.setAccessible(true);
}
int eventType = xpp.getEventType();
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_TAG:
int index = tagNames.indexOf(xpp.getName());
if (index > -1) {
Field field = fields[index];
field.set(bean, convertString(xpp.nextText(), field.getType()));
}else if (beanName.equals(xpp.getName())) {
bean = (T) clazz.newInstance();
}
break;
case XmlPullParser.START_DOCUMENT:
case XmlPullParser.END_TAG:
default: break;
}
eventType = xpp.next();
}
return bean;
}
/**
* 把xml输入流反序列化成Bean对象
*/
public static <T> List<T> unserialize_xml2List(final InputStream xmlIn, final Class clazz) throws Exception {
List<T> list = null;
T bean = null;
XmlPullParser xpp = Xml.newPullParser();
xpp.setInput(xmlIn, "UTF-8");
XmlClassInject classAnno = (XmlClassInject) clazz.getAnnotation(XmlClassInject.class);
if (null == classAnno) {
throw new Exception("Bean类上无@XmlClassInject注解名称");
}
String beanName = classAnno.value();
Field[] fields = clazz.getDeclaredFields();
List<String> tagNames = new ArrayList<>(fields.length);
for (Field field : fields) {
XmlFiledInject fieldAnno = field.getAnnotation(XmlFiledInject.class);
if (null == fieldAnno) {
tagNames.add(null);
} else {
tagNames.add(fieldAnno.value());
field.setAccessible(true);
}
}
int eventType = xpp.getEventType();
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_TAG:
int index = tagNames.indexOf(xpp.getName());
if (index > -1) {
Field field = fields[index];
field.set(bean, convertString(xpp.nextText(), field.getType()));
}else if (beanName.equals(xpp.getName())) {
bean = (T) clazz.newInstance();
}
break;
case XmlPullParser.START_DOCUMENT:
list = new ArrayList();
case XmlPullParser.END_TAG:
if (beanName.equals(xpp.getName())) {
list.add(bean);
}
default: break;
}
eventType = xpp.next();
}
return list;
}
/**
* 把字符串转换成指定类的值,即数据类型的转换
*/
private static Object convertString(String value, Class clazz) {
if (clazz == String.class) {
return value;
}else if (clazz == boolean.class || clazz == Boolean.class) {
return Boolean.parseBoolean(value);
}else if (clazz == byte.class || clazz == Byte.class) {
return new Byte(value);
}else if (clazz == short.class || clazz == short.class) {
return Short.valueOf(value);
}else if (clazz == int.class || clazz == Integer.class) {
return Integer.valueOf(value);
}else if (clazz == long.class || clazz == Long.class) {
return Long.valueOf(value);
}else if (clazz == float.class || clazz == Float.class) {
return Float.valueOf(value);
}else if (clazz == double.class || clazz == Double.class) {
return Double.valueOf(value);
}else if (clazz == char.class || clazz == Character.class) {
return value.charAt(0);
} else {
return null;
}
}
}XmlUtils的使用
- 给Bean类添加注解
- 调用XmlUtils内的序列化与反序列化方法
JavaBean中添加注解:
@XmlClassInject("Human")
public class HumanBean {
@XmlFiledInject("Id") private int id;
@XmlFiledInject("Name") private String name;
private boolean isMale;
@XmlFiledInject("兴趣") private String interest;
...
}调用:
// 测试数据
HumanBean human1 = new HumanBean(201, "张三", true, "<游戏>魔兽</游戏>,运动<篮球、足球>");
HumanBean human2 = new HumanBean(202, "小丽", false, "");
HumanBean human3 = new HumanBean(203, "乔布斯", true, "<语言>Java、C、C++</编程>,运动<健身、登山>");
mMan = new HumanBean(2007, "贝爷", true, "<武器>AK47、95、AWP<武器>,运动<探险、登山、游泳>");
mHumanList = new ArrayList<>();
mHumanList.add(human1);
mHumanList.add(human2);
mHumanList.add(human3);
...
// 序列化
try {
// list -> xml
new FileOutputStream(xmlFile).write(XmlUtils.serialize_list2Xml(mHumanList));
// bean -> xml
new FileOutputStream(humanFile).write(XmlUtils.serialize_bean2Xml(mMan));
} catch (Exception e) {
e.printStackTrace();
}
...
// 反序列化
List<HumanBean> xmlHumans = null;
HumanBean hb = null;
try {
// xml -> list
xmlHumans = XmlUtils.unserialize_xml2List(new FileInputStream(xmlFile), HumanBean.class);
// xml -> bean
hb = XmlUtils.unserialize_xml2Bean(new FileInputStream(humanFile), HumanBean.class);
} catch (Exception e) {
e.printStackTrace();
}集合序列化后的xml显示:

反序列化后的结果展示:

上面的HumanBean中没有对isMale进行注解,所以序列化后xml没有,反序列化后值为默认值false。
此XmlUtils是粗略写的,基本简单的够用了。但有很多地方有待完善,如这里只能注解9种数据类型(8种基本数据类型+String引用数据类型)……