典型回答
Java提供了不同层面的线程安全支持。在传统集合框架内部,除了Hashtable等同步容器,还提供了所谓的同步包装器(Synchronized Wrapper),可以调用Collections工具类提供的包装方法,来获取一个同步的包装容器,例如Collections.synchronizedMap()。但是它们都是利用非常粗粒度的同步方式,在高并发情况下的性能比较低下。
另外,更加普遍的选择是利用并发包(java.util.concurrent)提供的线程安全容器类:
- 各种并发容器,比如ConcurrentHashMap、CopyOnWriteArrayList。
- 各种线程安全队列(Queue/Deque),比如ArrayBlockingQueue、SynchronousQueue。
- 各种有序容器的线程安全版本等。
具体保证线程安全的方式,包括有从简单的synchronized方式,到基于更加精细化的,比如基于分离锁实现的ConcurrentHashMap等并发实现等。具体选择要看开发的场景需求,总体来说,并发包内提供的容器通用场景,远远优于早期的简单同步实现。
知识扩展
1、为什么需要ConcurrentHashMap?
首先,Hashtable本身比较低效,因为它的实现基本就是将put、get、size等方法简单粗暴地加上“synchronized”。这就导致了所有并发操作都要竞争同一把锁,一个线程在进行同步操作时,其它线程只能等待,大大降低了并发操作的性能。
上一讲已经提到HashMap不是线程安全的,并发情况或导致类似CPU占用100%等一些问题。
那么能不能利用Collections提供的同步包装器来解决问题呢?以下代码片段摘自Collections:
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
// ...
public int size() {
synchronized (mutex) {return m.size();}
}
}
我们发现同步包装器指示利用输入Map构造了另一个同步版本,所有操作虽然不再声明成为synchronized方法,但是还是利用了“this”作为互斥的mutex,没有真正意义上的改进!
所以,Hashtable或者同步包装版本都只适合在非高度并发的场景下。
2、ConcurrentHashMap分析
再来看看ConcurrentHashMap是如何设计实现的,为什么它能大大提供并发效率。
首先需要强调,ConcurrentHashMap的设计实现其实一直在演化,比如在Java 8中就发生了非常大的变化。
早期的ConcurrentHashMap其实现是基于:
- 分离锁,也就是将内部进行分段(Segment),里面则是HashEntry的数组。和HashMap类似,哈希相同的条目也是以链表形式存放。
- HashEntry内部使用volatile的value字段来保证可见性,也利用了不可变对象的机制以改进利用sun.misc.Unsafe提供的底层能力,比如volatile access,去直接完成部分操作,以最优化性能。毕竟Unsafe中的很多操作都是JVM intrinsic优化过的。
参考下面这个早期ConcurrentHashMap内部结构示意图,其核心是利用分段设立,在进行并发操作的时候,只需要锁定相应段,这样就有效避免了类似Hashtable整体同步的问题,大大提高了性能。
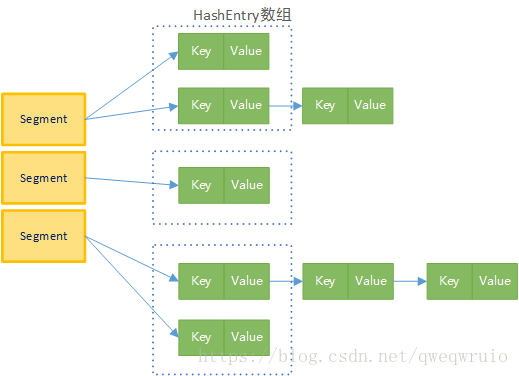
在构造的时候,Segment的数量由所谓的concurrentcyLevel决定,默认是16,也可以在相应构造函数直接指定。注意,Java需要它是2的整数次幂,例如输入15,将会被自动调整到16。
分离锁看似完美,但是在size方法实现时会有副作用。试想,如果不进行同步,简单的计算所有Segment的总值,可能会因为并发put,导致结果不准确;但是直接锁定所有Segment进行计算,就会变得非常昂贵。其实,分离锁也给包括Map初始化等操作带来类似的副作用。
所以,ConcurrentHashMap的实现是通过重试机制(RETRIES_BEFORE_LOCK,指定重复次数2),来试图获得可靠值。如果没有监控到发生变化,就直接返回,否则将获取锁进行操作。
3、Java 8对ConcurrentHashMap的改进
- 总体结构上,它的内部存储变得和上一讲中介绍的HashMap结构非常相似,同样是大的桶数组,然后内部也是一个个链表结果,同步的粒度要更细致一些。
- 其内部仍然有Segment定义,但仅仅是为了保证序列化时的兼容性而已,不再有任何结构上的用处。
- 因为不再使用Segment,初始化操作大大简化,修改为lazy-load形式。这样可以有效避免初始开销,解决了老版本很多人抱怨的这一点。
- 数据存储利用volatile来保证可见性。
- 使用CAS(Compare And Swap)等操作,在特定场景进行无锁并发操作。
- 使用Unsafe、LongAdder之类底层手段,进行极端情况的优化。
【完】