区块链的定义
区块链,直观的可以理解为下图,就是用链将区块一个个连接起来,最后形成了区块链。区块链的概念起源于中本聪的比特币白皮书,因此本文对区块链的解释,都是以比特币中的区块链为例。

自区块链诞生以来,它就是去中心化的分布式数据库的代名词,它的去中心化在于区块链网络中不存在主节点,每个节点都是平等的,谁都可以往区块链网络中添加新的区块,区块链中产生的数据不受任何一个节点的控制,所有在区块链网络中的节点都统一地保存着一份区块链节点,区块链虽然是分布式数据库,但通过其特定的方法和手段维持着区块链中数据的统一,后续为有更为详尽的介绍。
按照定义,区块链是一种按照时间顺序将数据区块以顺序相连的方式组合成的一种链式数据结构, 并以密码学方式保证的难以篡改和伪造的分布式账本。区块链是一个分布式的数据库,但是这个数据库与其他数据库相比,一旦被写入到区块链中,就难以篡改。为什么说区块链中的数据难以篡改,这是因为区块链特殊的数据组织方式。
哈希指针
区块链使用链表形式组织,与一般的链表不同,区块链中的链表指针采用哈希指针(Hash Pointer)。哈希指针与一般的指针区别在于,哈希指针中不仅存有下一个区块的位置,还存有指向的区块的哈希值。如下图所示
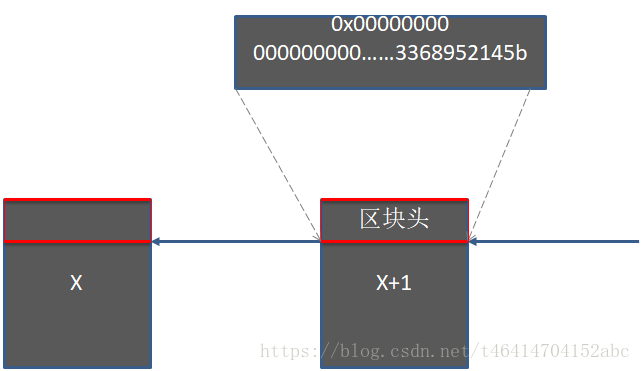
正如上图所示,第X+1号区块指向第X号区块,区块中的红框区域代表区块头,X+1号区块的区块头中保存了指向X号区块的哈希指针,其中0x00000000表示下一个X区块的位置,而000000000……3368952145b表示了第X号区块的区块头的哈希值。按照区块链的这种组织方式,假若我们对第X号区块中内容(区块头或者区块中的交易数据)进行了修改,X号区块的区块头的哈希值就会改变,X+1号中指向X号的哈希值也得跟着修改,这就修改了X+1号区块的内容,于是我们还需要修改X+2号区块(图中没有标出)中的内容……。区块链中的数据,一旦某个区块被修改,就会“改一块,而动全身”,改了某个区块,那么这个区块后的所有区块内容都要修改。
区块的难以篡改性
从最新的一个区块开始修改,修改之后继续修改后续区块的哈希值,这不就可以修改区块了吗?这样的过程确实不是那么难,如果区块链中仅仅是对区块头的内容进行哈希而不做别的要求,那么修改这么多区块的内容是一件很简单的事情。然而实际上,在中本聪提出区块链的时候,设定了区块链中每个区块中保存的哈希指针的哈希值,都必须满足特定的条件,即比特币中要求每个区块的区块头的哈希值的最高位的9个字节必须是0。比特币所在的区块链中采用SHA256算法,SHA256能将任意的输入转换为长度为256bit(32字节)的输出,整个SHA256算法的输出空间为
。
那么修改一个区块链的内容,随后将区块头输入到SHA256算法中,使得到的哈希值最高位的9个字节全部是0,这个过程的难度多大呢?
前面提到整个SHA256的输出空间为
,而哈希值最高位9个字节全部为0,那么比特币中,合法的哈希值有
,j假设区块中的内容随机设定,随后的哈希值在合法输出区间内的概率为
,而且目前没有好的方法来寻找某个x使得SHA256(x)<=y,只能通过随机测试的方法,改完一个区块还需要修改下一个区块,这样的方法其工作量非常大,而且在修改的同时,网络中又有新的的区块添加到区块链中,这就要求我们对区块的修改速度要高于目前挖矿的速度,这所需要的工作量非常巨大,修改这么多的区块几乎是不可能的事情,这就保证了区块链的内容的难以篡改性。或许有人会想,我只改变区块的内容而不改变区块头的内容,这样就不会引起区块头哈希值的改变了吗?实际上区块头中有一个字段叫做merkle root,它来自于区块中所有交易的哈希值,任何对交易的修改就会引起merkle root值得改变,因此对区块中交易的改变最后还是会引起区块头的改变。
区块头(Block Header)
区块链中的一个区块,其结构如下图所示。
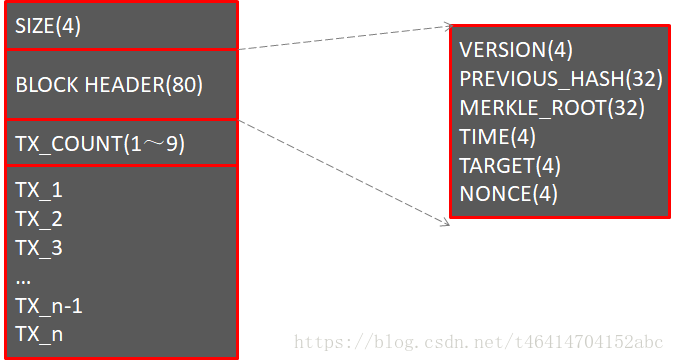
区块中每个变量的名称和含义如下表所示。
| 字段 | 大小(字节) | 解释 |
|---|---|---|
| SIZE | 4 | 区块的大小 |
| BLOCK HEADER | 80 | 区块的区块头 |
| TX_COUNT | 可变类型,(1~9) | 区块中的交易数 |
| TX_i | 可变类型,>=250 | 区块中的第i笔交易数 |
区块头中每个变量的名称和含义如下表所示。
| 字段 | 大小(字节) | 解释 |
|---|---|---|
| VERSION | 4 | 打包这个区块的节点所运行的区块链客户端版本 |
| PREVIOUS_HASH | 32 | 前一区块的区块头的哈希值 |
| MERKLE_ROOT | 32 | 区块中所有交易计算得到的默克尔树的哈希值 |
| TIME | 4 | 区块产生的近似时间(精确到秒的UNIX时间戳) |
| TARGET | 4 | 挖矿难度目标 |
| NONCE | 4 | 随机数 |
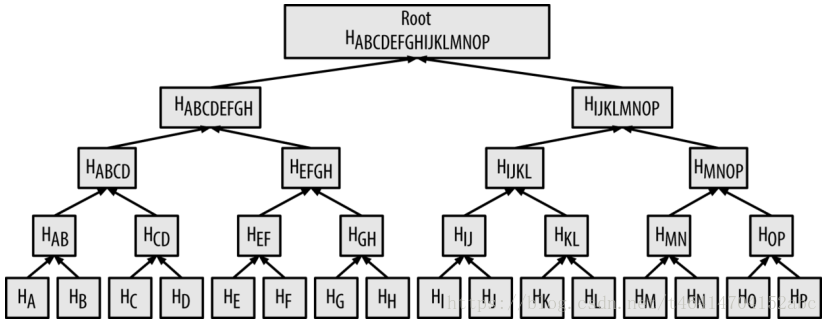
Merkele Tree(默克尔树)
在区块头中有一个重要的字段,叫做merkle Root,指的是区块中所有交易形成的默克尔树的根节点值。Merkle树是一种哈希二叉树,它是一种用作快速归纳和校验大规模数据完整性的数据结构。一个Merkle树的结构主要是如下结构(来自精通比比特币):
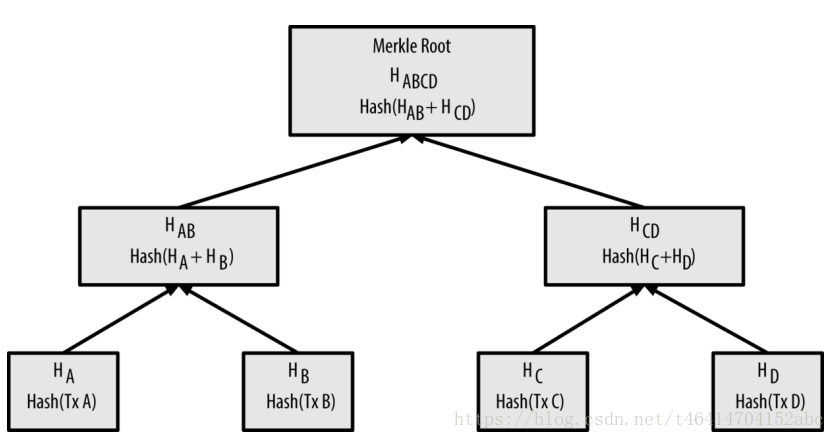
假设在一个区块中包含4笔交易,分别是TxA,TxB、TxC、TxD,用这4笔交易内容如何构造merkle树呢?前面已经提到了merkle中存储的是哈西值,在比特币中存储的是经过SHA256算法哈希后的结果,其全称为Secure Hash Algorithm,将任意长度的数据输入到这个算法中,经过计算之后得到长度为256bits的输出,即32字节长度的数据。在比特币构建merkle 树的时候,对每一笔交易的内容进行2次哈希,称之为double-Hash256.在上图中叶子节点HA中的内容是:
一次类推,分别的到了HB、HC、和HD,将相邻的交易形成的哈希值合并在一起继续进行 double-Hash256算法。
继续按照这种方法,最终构建了Merkle 树的merkle root值 ,merkle root长度为32字节。每个挖矿的矿工利用自己的区块中交易构建merkle 树,最终将得到的树根值放入到区块的merkle root字段中。
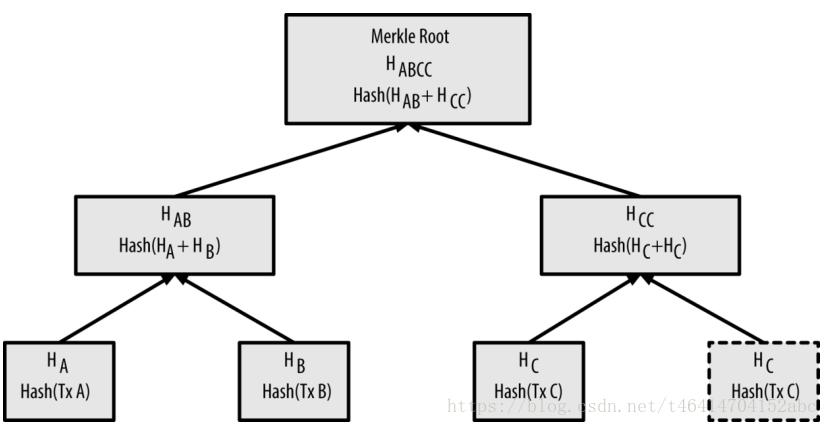
看到这里可以发现merkle树根节点的计算,必须是偶数个交易构成,但是如果只有奇数个交易的话,该怎么办呢?在比特币网络中,将最后一个交易复制一次,自己和自己的复制合在一起进行double-SHA256算法。如下图所示(精通比特币)。
一个区块中可以包含很多笔交易,不同的区块可能包含数量不等的交易,但是通过构建merkle树后都可以得到长度为32字节的merkle root值。下图中,16笔交易构成了一个merkle树。虽然这些节点大小不一致,但是其中每个节点的大小实际上是相等的,都是32个字节(内容来自精通比特币,这本书真的很好)。
merkle树的作用
比特币的区块链中为什么要引入merkle树呢?merkle的引入是为了支持简单支付验证(Simple Payment Validation, SPV)。
区块链是一个分布式的数据库,而对于一些使用比特币的用户来说,讲道理根本不需要保存区块链的所有区块数据,因为这些区块数据本身很大,而且如果实在移动端,这些区块会占用大量的存储,不方便比特币的使用和发展。因此保存区块链的一些节点中,有一些节点只保存区块中的区块头,形成区块头链。原本保存一个区块可能需要1M的存储,但是只保存区块头只需要不超过100字节的大小,内存占用减少了10倍。区块链中保存完整的区块信息的节点称之为全节点,而只保存区块头信息的节点成为轻节点,一般的比特币钱包是轻节点,只需要保存区块头信息即可。
我们假设区块链中没有merkle树这一结构,A是一家汽车销售商,B是一个顾客,A给B转账10BTC来购买一辆汽车,这笔交易只有被矿工打包到区块链上时,B还需要查找在区块链中是否有这样的一笔交易,此时B需要查找最近的几个区块,遍历这些区块中的交易,从中找出A转给B 10个BTC的交易,查找到了这笔交易之后,B让A把车开走。而对于B来说,每次从最近的区块中查找对应的一笔交易是否存在是一件耗时的事情。如果有n笔交易,检索的复杂度为O(n)。而有了merkle树,如B可以向就近的保存了区块链全部节点的服务器发送验证请求,服务器会将包含A转账10BTC的交易发送给B,另外发送一个merkle 树路径,用以验证这笔转账交易包括在区块中。一个merkle路径如下图所示。
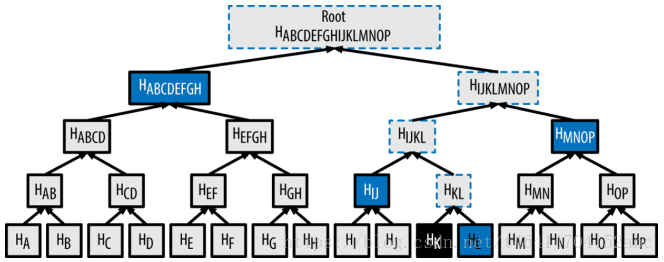
服务器发送给B的merkle路径如上图中的蓝色区域所示。B收到之后分别用这笔交易 和 进行double-SHA256算法得到 ,再对 和 进行double-SHA256算法得到 ,以此类推,最终得到生成的merkle root值,然后比较收到的区块头中的merkle root值和计算得到的merkle root值是否相等,如果相等,就可以表明A给B转账的交易已经写入区块中,也就完成了交易的验证。这样的验证只需要 的复杂度,相比于原来遍历交易的做法,这种方法更加简单,所以称之为简单支付验证。