我们都知道如果想要在Python的代码中输入中文,必须在import前加上
# -*- coding: UTF-8 -*-,这样我们就可以在代码中输入中文了。
当你用notepad++或者editplus写代码时。
在
windows平台下,如果输出在命令行,经常会出现乱码或者decode错误
例如
str='你好'
print str
这时通常会出现下图这种情况
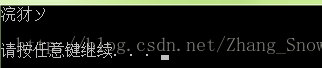
文字出现了乱码,是什么原因呢?
你说那我这样写呢
mes='你好'
print u'%s' %(mes)
你会发现如果是print u'你好' # 这样写没问题
但是上面的通常会出现下图的情况

UnicodeDecodeError:ascii 编码器不能解码 字节 0xe4 在位置0: 序号不在0到127里
为什么呢?
win+R,cmd回车打开命令行,输入chcp

936是我的window7中命令行的编码解码格式
你可以修改默认的格式,通过
首先输入chcp 格式代码,然后在命令行窗体上右键
点击属性

选中新出现的字体,确定就可以了。
chcp的格式代码请参考
http://baike.baidu.com/link?url=KGvaBROIaiuRnK35fqTiqje_gPTYGUm2k1J_eaQVApt4SIE3HU58yCMizEGw5JjRLWU7PaJA6XPOSS74e_B8qK百度百科内容
例如chcp 95001就是utf-8
回到之前的话题,为什么Python在命令行会输出异常呢?
首先我们分析以下输出过程中编码解码的过程
print str
这里str是字符串引用,要想输出对应的内容,先找到对应的值,它在内存里面以字节码存储,然后将值解码成对应的字符串,再编码成你的命令行对应的格式的字节(如gbk)bytes。然后命令行会将你的字节码根据命令行的格式转化成字符串显示出来。
注意:编码成字节格式可以省略,因为Python会自动完成找到你命令行解码编码格式,然后转换成对应的字节码这个过程,使用的也是'ignore'。
decode()用于将bytes解码成指定格式字符串,encode()将字符串按指定格式编码成bytes,encode()还有第二个参数它能帮助你解决那么无法表达的字符串,'ignore'用来抛弃任何不能被编码的字符串,'replace'用来用?代替那些字符串。
好了,让我们在回头看看如何解决开头的问题
str='你好'
print str.decode('utf-8')
#print str.decode('utf-8').encode('gbk','ignore') #第二个参数是你命令行的格式
针对第二个问题,
mes='你好'
#有以下两种,可以写u也可以不写
print '%s' %(mes.decode('utf-8'))
#print '%s' %(mes.decode('utf-8').encode('gbk','ignore'))
---------------------------------------------------------------
print u'%s' %(mes.decode('utf-8'))
注意这时如果你这样写
print u'%s' %(mes.decode('utf-8').encode('gbk','ignore')),如下图
这句就可以看出u的作用了,u的作用是将后面的字符串转换成unicode对应的字节存储在内存中
也就相当于执行了
mes.decode('utf-8')这

个过程,当你直接print u'你好'时,u会把'你好'编码成uniocde对应的字节再输出,
这时也就等价于print '你好'.decode('utf-8'),因此输出正确。
但是当你print u'%s' %(mes)时,Python的会将''里的空字符串转变为unicode字节,再用默认的ascii解码器解码mes的内容。
mes='snow'
print u'你好%s' %(mes)# 这样可以正常运行
也就是说u不能自动替变量解码
如果你一定要用u的话,可以使用下面的方法
print u'你好%s' %(mes.decode('utf-8'))