前言
几年前,我在刚刚进入大数据领域的时候,很快就了解到Hive所提供的一种另类的SQL。最初使用Hive的命令行提交任务,后来便用上了HiveServer和HiveServer2。半年前第一次注意到Spark的Thrift服务,当时心中就笃定它肯定与HiveServer2有着某种联系,直到在工作中真正使用它。
在使用HiveThriftServer2的过程中,通过故障排查、源码分析和功能优化,HiveThriftServer2的实现及其原理就浮上水面。等我了解了HiveThriftServer2,情不自禁的就会和Tomcat进行一番比较,尤其是在组件的生命周期管理方面。有兴趣的同学可以先阅读下我之前写得《Tomcat7.0源码分析——生命周期管理》一文。Tomcat将内部组件都抽象为容器,而HiveThriftServer2的内部组件都是服务。HiveThriftServer2对服务的抽象不是本来固有的,而是继承自HiveServer2的。根据HiveServer2的设计,所有的服务都需要实现Service接口。
本文将从HiveThriftServer2的Service接口设计、生命周期管理、启动过程分析三个角度深入分析。
一切都是服务
早年间火热的SOA技术,有一个关键的修饰语——“一切都是服务”,今天拿来形容HiveThriftServer2及HiveServer2中的组件抽象却恰如其分。HiveServer2定义了Service接口,其中包含的接口方法见代码清单1。
代码清单1 Service的定义
void init(HiveConf conf);
void start();
void stop();
void register(ServiceStateChangeListener listener);
void unregister(ServiceStateChangeListener listener);
String getName();
HiveConf getHiveConf();
STATE getServiceState();
long getStartTime();
- init:对服务组件进行初始化
- start:启动服务组件
- stop:停止服务组件
- register:注册对服务组件的状态感兴趣的监听器,监听器由ServiceStateChangeListener接口定义。ServiceStateChangeListener只有stateChanged一个方法用来处理服务组件的状态。
- unregister:撤销对服务组件的状态感兴趣的监听器
- getName:获取服务组件的名称
- getHiveConf:获取初始化服务组件时,设置的HiveConf
- getServiceState:获取服务组件的状态。方法返回的枚举类型STATE定义了服务组件所能拥有的所有可能状态,包括:未初始化(NOTINITED)、初始化(INITED)、已启动(STARTED)、已停止(STOPPED)。
- getStartTime:获取服务组件的启动时间。
- state:服务组件的初始状态,默认为NOTINITED。
- name:服务组件的名称。
- startTime:服务组件的启动时间。
- hiveConf:服务组件初始化时设置的hiveConf。
- listeners:用于缓存对服务组件的状态感兴趣的所有ServiceStateChangeListener的列表。
服务初始化
public synchronized void init(HiveConf hiveConf) {
ensureCurrentState(STATE.NOTINITED); //确认服务组件的当前状态是否一致
this.hiveConf = hiveConf;
changeState(STATE.INITED); //将服务组件的状态修改为INITED
LOG.info("Service:" + getName() + " is inited.");
} private void changeState(STATE newState) {
state = newState;
// notify listeners
for (ServiceStateChangeListener l : listeners) {
l.stateChanged(this);
}
}服务启动
public synchronized void start() {
startTime = System.currentTimeMillis();
ensureCurrentState(STATE.INITED);
changeState(STATE.STARTED); //将服务组件的状态修改为STARTED
LOG.info("Service:" + getName() + " is started.");
}服务停止
public synchronized void stop() {
if (state == STATE.STOPPED ||
state == STATE.INITED ||
state == STATE.NOTINITED) {
// already stopped, or else it was never
// started (eg another service failing canceled startup)
return;
}
ensureCurrentState(STATE.STARTED);
changeState(STATE.STOPPED); //将服务组件的状态修改为STOPPED
LOG.info("Service:" + getName() + " is stopped.");
}监听器的注册与注销
AbstractService实现的监听器注册和注销 方法见代码清单6.代码清单6
@Override
public synchronized void register(ServiceStateChangeListener l) {
listeners.add(l);
}
@Override
public synchronized void unregister(ServiceStateChangeListener l) {
listeners.remove(l);
}获取服务信息
AbstractService实现的获取服务信息的方法见代码清单7.代码清单7
@Override
public String getName() {
return name;
}
@Override
public synchronized HiveConf getHiveConf() {
return hiveConf;
}
@Override
public long getStartTime() {
return startTime;
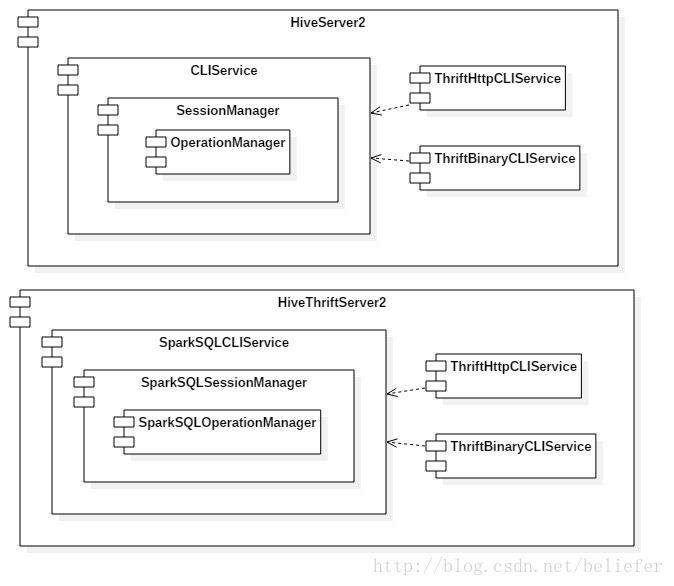
}有了Service的基础定义和AbstractService的基础实现,HiveServer2中的所有服务就有了依托。像OperationManager和ThriftCliService就直接继承了AbstractService。在整个设计中,HiveServer2还提供了一个对AbstractService的行为进行了重写的复合组件(CompositeService)用于表示由多种服务组件组合构成的服务组件。HiveServer2中的所有复合组件,比如CLIService、HiveServer2、SessionManager等都继承自CompositeService。HiveThriftServer2通过反射加继承的方式间接的使用了AbstractService和CompositeService。在介绍复合组件之前,我们先展示整个Service的继承体系,如图1所示。

图1 Service的继承体系
复合服务
从图1可以看出CompositeService直接继承了AbstractService。CompositeService内部定义了一个用于管理所有子Service的列表:
private final List<Service> serviceList = new ArrayList<Service>();CompositeService重写了AbstractService实现的服务初始化、服务启动、服务停止等方法。
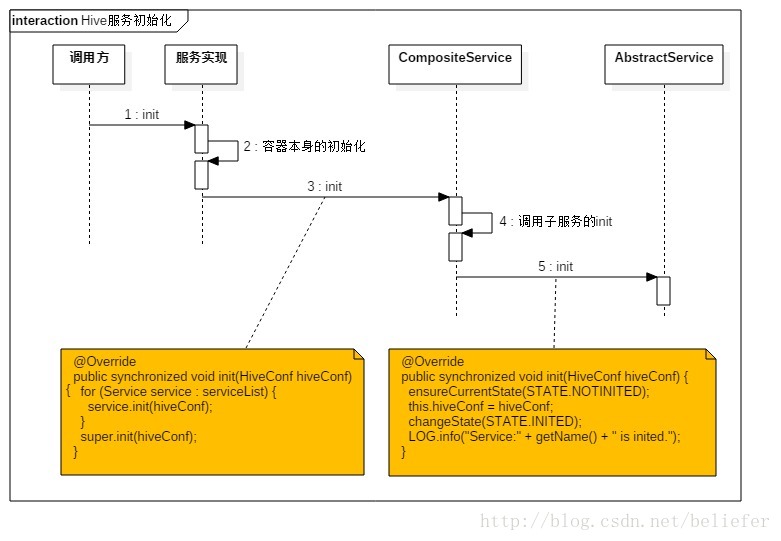
复合服务的初始化
CompositeService重写的初始化方法见代码清单8.
代码清单8
@Override
public synchronized void init(HiveConf hiveConf) {
for (Service service : serviceList) {
service.init(hiveConf);
}
super.init(hiveConf);
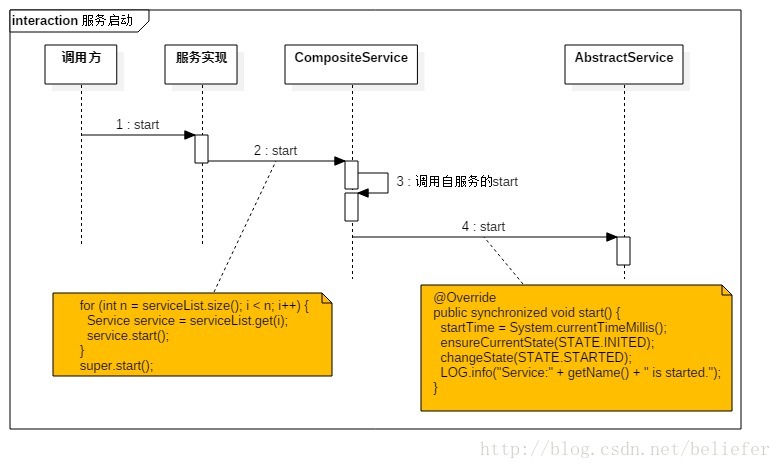
}复合服务的启动
CompositeService重写的启动方法见代码清单9.
代码清单9
@Override
public synchronized void start() {
int i = 0;
try {
for (int n = serviceList.size(); i < n; i++) {
Service service = serviceList.get(i);
service.start();
}
super.start();
} catch (Throwable e) {
LOG.error("Error starting services " + getName(), e);
stop(i);
throw new ServiceException("Failed to Start " + getName(), e);
}
}复合服务的停止
CompositeService重写的停止方法见代码清单10. @Override
public synchronized void stop() {
if (this.getServiceState() == STATE.STOPPED) {
// The base composite-service is already stopped, don't do anything again.
return;
}
if (serviceList.size() > 0) {
stop(serviceList.size() - 1);
}
super.stop();
}图1中所示的 CLIService、HiveServer2、SessionManager由于继承了CompositeService,所以他们都是复合组件。
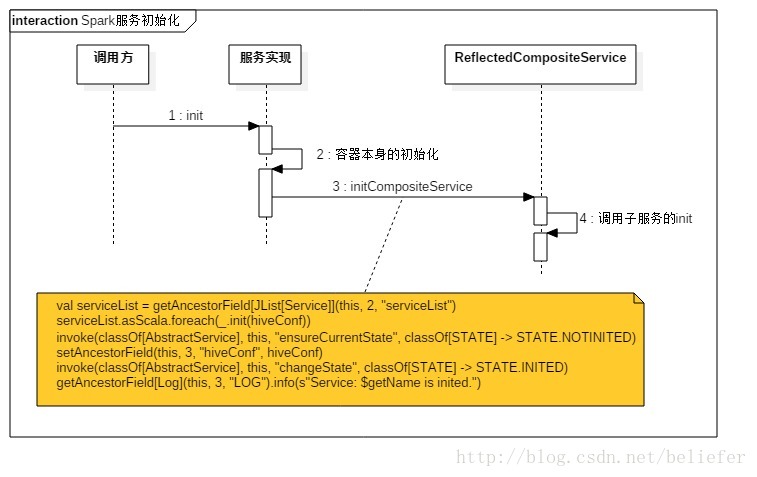
HiveThriftServer2与HiveServer2的区别
private[thriftserver] trait ReflectedCompositeService { this: AbstractService =>
def initCompositeService(hiveConf: HiveConf) {
// Emulating `CompositeService.init(hiveConf)`
val serviceList = getAncestorField[JList[Service]](this, 2, "serviceList")
serviceList.asScala.foreach(_.init(hiveConf))
// Emulating `AbstractService.init(hiveConf)`
invoke(classOf[AbstractService], this, "ensureCurrentState", classOf[STATE] -> STATE.NOTINITED)
setAncestorField(this, 3, "hiveConf", hiveConf)
invoke(classOf[AbstractService], this, "changeState", classOf[STATE] -> STATE.INITED)
getAncestorField[Log](this, 3, "LOG").info(s"Service: $getName is inited.")
}
}初始化、启动、停止
最后再附上本文的姊妹篇——《Spark1.6.0功能扩展——为HiveThriftServer2增加HA》
关于《Spark内核设计的艺术 架构设计与实现》
经过近一年的准备,基于Spark2.1.0版本的《 Spark内核设计的艺术 架构设计与实现 》一书现已出版发行,图书如图: