1.查看所有数据库:
show dbs
2.选择数据库:
use test
3.查看数据库中有哪些集合:
show collections
如下图:

查询
1.查看集合中有哪些数据,其中abc为集合名称:

2.为查询添加过滤条件a=2:

3.指定查询结果集中包含的字段,如下查询仅包含字段a/b,注意,此处除了_id字段外,其他字段要么全是1,要么全是0:
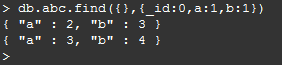
4.综合示例:
db.kpiRecord.find( { cellCode:"48BF74_12020000051TST0001", startTime: { $gte: new ISODate("2018-06-01T00:00:00Z") }, startTime: { $lt: new ISODate("2018-06-01T01:00:00Z") } }, { _id:0, cellCode:1, startTime:1, kpiNameLalalalala0000:1 } )
如下图:

插入
1.添加一条记录:
db.abc.insertOne({"123" : "123-val", "a" : 34, "b" : 36})
如下图:

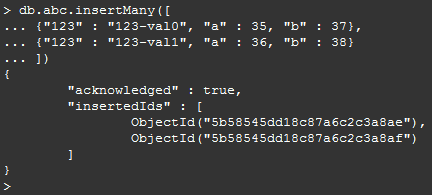
2.添加多条记录:
db.abc.insertMany([ {"123" : "123-val0", "a" : 35, "b" : 37}, {"123" : "123-val1", "a" : 36, "b" : 38} ])
如下图:
更新
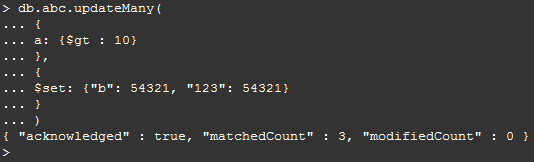
按筛选条件更新数据:
db.abc.updateMany( { a: {$gt : 10} }, { $set: {"b": 54321, "123": 54321} } )
如下图:
删除
1.根据条件删除集合中的数据:
db.abc.deleteMany({ a : {$gte : 36} })
如下图:

2.删除集合,其中abc为集合名称:

聚合
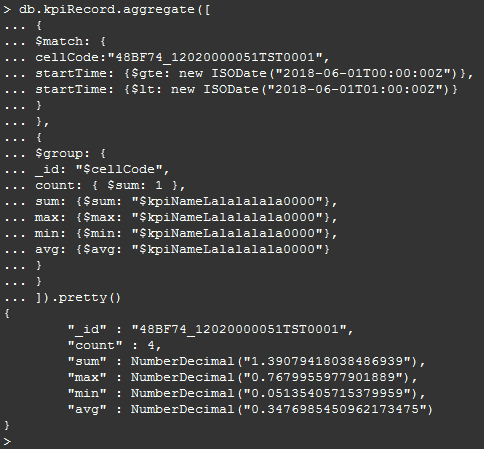
先根据cellCode字段和startTime字段进行筛选,再根据cellCode进行聚合,计算出总和、最大值、最小值、平均值,其中pretty()方法只是为了以更整齐的方式显示结果:
db.kpiRecord.aggregate([ { $match: { cellCode:"48BF74_12020000051TST0001", startTime: {$gte: new ISODate("2018-06-01T00:00:00Z")}, startTime: {$lt: new ISODate("2018-06-01T01:00:00Z")} } }, { $group: { _id: "$cellCode", count: { $sum: 1 }, sum: {$sum: "$kpiNameLalalalala0000"}, max: {$max: "$kpiNameLalalalala0000"}, min: {$min: "$kpiNameLalalalala0000"}, avg: {$avg: "$kpiNameLalalalala0000"} } } ]).pretty()
如下图:
限制条件:
(1).结果集document大小限制:结果集中,每一个document的大小不得超过16M。注意仅是限制结果集,处理过程中,document的大小是可以超过这个限制的。
(2).内存限制:Stages所能使用的内存不能超过100M。对于一些数据量较大的聚合计算,100M不够用,这时,需要指定allowDiskUse属性,从而允许MongoDB向临时文件中写数据。注意,对于$graphLookup操作符,allowDiskUse不生效。
另外,这里介绍的聚合方式是pipeline,最基本的聚合方式,MongoDB还有更复杂但也更强大的聚合方式,如Map-reduce,具体可查阅官方文档。