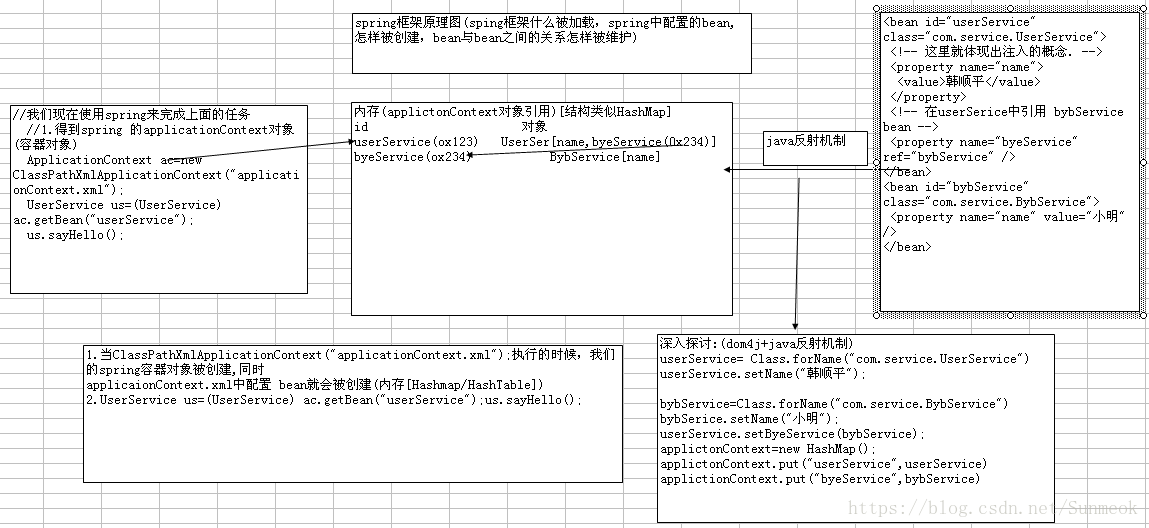
Spring的ioc和di:
转自:http://jinnianshilongnian.iteye.com/blog/1413846
1.1、IoC是什么
Ioc—Inversion of Control,即“控制反转”,不是什么技术,而是一种设计思想。在Java开发中,Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。如何理解好Ioc呢?理解好Ioc的关键是要明确“谁控制谁,控制什么,为何是反转(有反转就应该有正转了),哪些方面反转了”,那我们来深入分析一下:
●谁控制谁,控制什么:传统Java SE程序设计,我们直接在对象内部通过new进行创建对象,是程序主动去创建依赖对象;而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对 象的创建;谁控制谁?当然是IoC 容器控制了对象;控制什么?那就是主要控制了外部资源获取(不只是对象包括比如文件等)。
●为何是反转,哪些方面反转了:有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。
用图例说明一下,传统程序设计如图2-1,都是主动去创建相关对象然后再组合起来:

图1-1 传统应用程序示意图
当有了IoC/DI的容器后,在客户端类中不再主动去创建这些对象了,如图2-2所示:
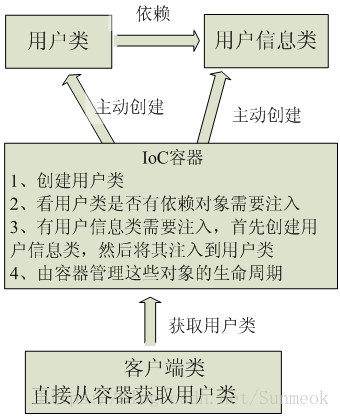
图1-2有IoC/DI容器后程序结构示意图
1.2、IoC能做什么
IoC 不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合、更优良的程序。传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试;有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是 松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
其实IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了。
IoC很好的体现了面向对象设计法则之一—— 好莱坞法则:“别找我们,我们找你”;即由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
1.3、IoC和DI
DI—Dependency Injection,即“依赖注入”:组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。
理解DI的关键是:“谁依赖谁,为什么需要依赖,谁注入谁,注入了什么”,那我们来深入分析一下:
●谁依赖于谁:当然是应用程序依赖于IoC容器;
●为什么需要依赖:应用程序需要IoC容器来提供对象需要的外部资源;
●谁注入谁:很明显是IoC容器注入应用程序某个对象,应用程序依赖的对象;
●注入了什么:就是注入某个对象所需要的外部资源(包括对象、资源、常量数据)。
IoC和DI由什么关系呢?其实它们是同一个概念的不同角度描述,由于控制反转概念比较含糊(可能只是理解为容器控制对象这一个层面,很难让人想到谁来维护对象关系),所以2004年大师级人物Martin Fowler又给出了一个新的名字:“依赖注入”,相对IoC 而言,“依赖注入”明确描述了“被注入对象依赖IoC容器配置依赖对象”。
看过很多对Spring的Ioc理解的文章,好多人对Ioc和DI的解释都晦涩难懂,反正就是一种说不清,道不明的感觉,读完之后依然是一头雾水,感觉就是开涛这位技术牛人写得特别通俗易懂,他清楚地解释了IoC(控制反转) 和DI(依赖注入)中的每一个字,读完之后给人一种豁然开朗的感觉。我相信对于初学Spring框架的人对Ioc的理解应该是有很大帮助的。
二、分享Bromon的blog上对IoC与DI浅显易懂的讲解
2.1、IoC(控制反转)
首先想说说IoC(Inversion of Control,控制反转)。这是spring的核心,贯穿始终。所谓IoC,对于spring框架来说,就是由spring来负责控制对象的生命周期和对象间的关系。这是什么意思呢,举个简单的例子,我们是如何找女朋友的?常见的情况是,我们到处去看哪里有长得漂亮身材又好的mm,然后打听她们的兴趣爱好、qq号、电话号、ip号、iq号………,想办法认识她们,投其所好送其所要,然后嘿嘿……这个过程是复杂深奥的,我们必须自己设计和面对每个环节。传统的程序开发也是如此,在一个对象中,如果要使用另外的对象,就必须得到它(自己new一个,或者从JNDI中查询一个),使用完之后还要将对象销毁(比如Connection等),对象始终会和其他的接口或类藕合起来。
那么IoC是如何做的呢?有点像通过婚介找女朋友,在我和女朋友之间引入了一个第三者:婚姻介绍所。婚介管理了很多男男女女的资料,我可以向婚介提出一个列表,告诉它我想找个什么样的女朋友,比如长得像李嘉欣,身材像林熙雷,唱歌像周杰伦,速度像卡洛斯,技术像齐达内之类的,然后婚介就会按照我们的要求,提供一个mm,我们只需要去和她谈恋爱、结婚就行了。简单明了,如果婚介给我们的人选不符合要求,我们就会抛出异常。整个过程不再由我自己控制,而是有婚介这样一个类似容器的机构来控制。Spring所倡导的开发方式就是如此,所有的类都会在spring容器中登记,告诉spring你是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
2.2、DI(依赖注入)
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,依赖注入)来实现的。比如对象A需要操作数据库,以前我们总是要在A中自己编写代码来获得一个Connection对象,有了 spring我们就只需要告诉spring,A中需要一个Connection,至于这个Connection怎么构造,何时构造,A不需要知道。在系统运行时,spring会在适当的时候制造一个Connection,然后像打针一样,注射到A当中,这样就完成了对各个对象之间关系的控制。A需要依赖 Connection才能正常运行,而这个Connection是由spring注入到A中的,依赖注入的名字就这么来的。那么DI是如何实现的呢? Java 1.3之后一个重要特征是反射(reflection),它允许程序在运行的时候动态的生成对象、执行对象的方法、改变对象的属性,spring就是通过反射来实现注入的。
理解了IoC和DI的概念后,一切都将变得简单明了,剩下的工作只是在spring的框架中堆积木而已。
三、我对IoC(控制反转)和DI(依赖注入)的理解
在平时的java应用开发中,我们要实现某一个功能或者说是完成某个业务逻辑时至少需要两个或以上的对象来协作完成,在没有使用Spring的时候,每个对象在需要使用他的合作对象时,自己均要使用像new object() 这样的语法来将合作对象创建出来,这个合作对象是由自己主动创建出来的,创建合作对象的主动权在自己手上,自己需要哪个合作对象,就主动去创建,创建合作对象的主动权和创建时机是由自己把控的,而这样就会使得对象间的耦合度高了,A对象需要使用合作对象B来共同完成一件事,A要使用B,那么A就对B产生了依赖,也就是A和B之间存在一种耦合关系,并且是紧密耦合在一起,而使用了Spring之后就不一样了,创建合作对象B的工作是由Spring来做的,Spring创建好B对象,然后存储到一个容器里面,当A对象需要使用B对象时,Spring就从存放对象的那个容器里面取出A要使用的那个B对象,然后交给A对象使用,至于Spring是如何创建那个对象,以及什么时候创建好对象的,A对象不需要关心这些细节问题(你是什么时候生的,怎么生出来的我可不关心,能帮我干活就行),A得到Spring给我们的对象之后,两个人一起协作完成要完成的工作即可。
所以控制反转IoC(Inversion of Control)是说创建对象的控制权进行转移,以前创建对象的主动权和创建时机是由自己把控的,而现在这种权力转移到第三方,比如转移交给了IoC容器,它就是一个专门用来创建对象的工厂,你要什么对象,它就给你什么对象,有了 IoC容器,依赖关系就变了,原先的依赖关系就没了,它们都依赖IoC容器了,通过IoC容器来建立它们之间的关系。
这是我对Spring的IoC(控制反转)的理解。DI(依赖注入)其实就是IOC的另外一种说法,DI是由Martin Fowler 在2004年初的一篇论文中首次提出的。他总结:控制的什么被反转了?就是:获得依赖对象的方式反转了。
四、小结
对于Spring Ioc这个核心概念,我相信每一个学习Spring的人都会有自己的理解。这种概念上的理解没有绝对的标准答案,仁者见仁智者见智。如果有理解不到位或者理解错的地方,欢迎广大园友指正!
Spring的bean的作用域:
singleton:在这个spring容器中建立一次这个bean的对象,则会一直存在,即使新建也不会改变。
验证方法:getBean()方法调用两次,且调用同一对象。结果两个地址相同。
prototype:每次定义bean都会新建一个对象实例
验证方法:getBean()方法调用两次,且调用同一对象。结果两个地址不同。
request:用于web中,每个request用一个对象实例
session:用于web中,每个session用一个对象实例‘
globalSession:作用和session类似,只是使用portlet的时候使用。(portlet是个web组件)
Spring的注入方式:
java又三种注入方式:
构造器注入:通过xml文件来确定,书写方法如下。
<bean id="construct" class="it.construct.ConstructBean">
<!--index从零开始,决定它的参数位置,type是它的参数类型-->
<constructor-arg index="0" type="java.lang.String" value="余飞"></constructor-arg>
<constructor-arg index="1" type="int" value="04152015"/>
<!--选择构造函数是根据它的设置了几个构造参数参数,就是 <constructor-arg />语句-->
</bean>通过构造器注入,主要是通过在xml文件中设置参数的位置和类型来确定,并通过构造器赋值(自定义构造器要完成赋值操作),不需要get和set方法
set注入:通过xml文件:
<bean id="dog" class="spring.Dog">
<property name="id" value="15" />
</bean>
通过在bean中设置id属性等,需要书写set和get方法,才能完成赋值
注解注入:
需要在xml开启注解,扫描特定的包完成注解服务
常用注解:
@Component
@Component
是所有受Spring 管理组件的通用形式,@Component注解可以放在类的头上,@Component不推荐使用。
@Controller
@Controller对应表现层的Bean,如果指定value【@Controller(value="UserAction")】或者【@Controller("UserAction")】,则使用value作为bean的名字。
@ Service
@Service对应的是业务层Bean,和Controller的用法一样
@ Repository
@Repository对应数据访问层Bean,和Controller的用法一样
@Autowired
@Autowired顾名思义,就是自动装配,其作用是为了消除代码Java代码里面的getter/setter与bean属性中的property。当然,getter看个人需求,如果私有属性需要对外提供的话,应当予以保留。
@Autowired默认按类型匹配的方式,在容器查找匹配的Bean,当有且仅有一个匹配的Bean时,Spring将其注入@Autowired标注的变量中。
@Resource
@Resource注解与@Autowired注解作用非常相似
(1)、@Resource后面没有任何内容,默认通过name属性去匹配bean,找不到再按type去匹配
(2)、指定了name或者type则根据指定的类型去匹配bean
(3)、指定了name和type则根据指定的name和type去匹配bean,任何一个不匹配都将报错
@Resource(name="tiger") 匹配名字 @Resource(type=Monkey.class)匹配类型,要加.class-
@Autowired和@Resource两个注解的区别:
-
(1)、@Autowired默认按照byType方式进行bean匹配,@Resource默认按照byName方式进行bean匹配
-
(2)、@Autowired是Spring的注解,@Resource是J2EE的注解,这个看一下导入注解的时候这两个注解的包名就一清二楚了
Spring的自动装配
https://blog.csdn.net/sunmeok/article/details/80210731
spring的分散装配
https://blog.csdn.net/sunmeok/article/details/80219342
bean的生命周期:

作者:MOBIN-F
链接:https://www.zhihu.com/question/38597960/answer/77600561
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1.Spring对Bean进行实例化(相当于程序中的new Xx())
2.Spring将值和Bean的引用注入进Bean对应的属性中
3.如果Bean实现了BeanNameAware接口,Spring将Bean的ID传递给setBeanName()方法
(实现BeanNameAware清主要是为了通过Bean的引用来获得Bean的ID,一般业务中是很少有用到Bean的ID的)
4.如果Bean实现了BeanFactoryAware接口,Spring将调用setBeanDactory(BeanFactory bf)方法并把BeanFactory容器实例作为参数传入。
(实现BeanFactoryAware 主要目的是为了获取Spring容器,如Bean通过Spring容器发布事件等)
5.如果Bean实现了ApplicationContextAwaer接口,Spring容器将调用setApplicationContext(ApplicationContext ctx)方法,把y应用上下文作为参数传入.
(作用与BeanFactory类似都是为了获取Spring容器,不同的是Spring容器在调用setApplicationContext方法时会把它自己作为setApplicationContext 的参数传入,而Spring容器在调用setBeanDactory前需要程序员自己指定(注入)setBeanFactory里的参数BeanFactory ,ApplicationContext是BeanFactory的子接口,有更多的实现方法)
6.如果Bean实现了BeanPostProcess接口,Spring将调用它们的postProcessBeforeInitialization(预初始化)方法
(作用是在Bean实例创建成功后对进行增强处理,如对Bean进行修改,增加某个功能)
7.如果Bean实现了InitializingBean接口,Spring将调用它们的afterPropertiesSet方法,作用与在配置文件中对Bean使用init-method声明初始化的作用一样,都是在Bean的全部属性设置成功后执行的初始化方法。它与前置处理不同,由于该函数并不会把当前bean对象传进来,因此在这一步没办法处理对象本身,只能增加一些额外的逻辑。
8.如果Bean实现了BeanPostProcess接口,Spring将调用它们的postProcessAfterInitialization(后初始化)方法
(作用与6的一样,只不过6是在Bean初始化前执行的,而这个是在Bean初始化后执行的,时机不同 )
9.经过以上的工作后,Bean将一直驻留在应用上下文中给应用使用,直到应用上下文被销毁
10.如果Bean实现了DispostbleBean接口,Spring将调用它的destory方法,作用与在配置文件中对Bean使用destory-method属性的作用一样,都是在Bean实例销毁前执行的方法。
spring的aop编程:
即面向切面编程,可以说是OOP(Object Oriented Programming,面向对象编程)的补充和完善,利用java动态代理技术实现
它利用一种称为"横切"的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其命名为"Aspect",即切面。所谓"切面",简单说就是那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块之间的耦合度,并有利于未来的可操作性和可维护性。
几个常用关键词:
- 切面(Aspect):简单的理解就是把那些与核心业务无关的代码提取出来,进行封装成一个或几个模块用来处理那些附加的功能代码。
- 连接点(JoinPoint):能被添加通知代码的地点
- 切入点(CutPoint):再连接点被实现了具体的拦截方法就叫切入点
- 通知(Advice):在切面的某个特定的连接点(Joinpoint)上执行的动作
- 织入(Weaving): 组装通知到代理对象中来创建一个被通知对象。这可以在编译时 完成(例如使用AspectJ编译器),也可以在运行时完成。Spring和其他纯Java AOP框架一样, 在运行时完成织入。
按步骤来看,我们有一个接口,它有好几个实现类,我们现在要给这个接口的一些实现类里添加它们共有的方法,那么我们一个类一个类添加就会很麻烦,我们通过把这些操作单独封装起来,然后通过配置放入它们的需要操作的地方。
我们把这些封装起来的操作就称为切面
我们假设要把这个操作放到某个地方去,这个地方就成为连接点,如果在这个点实际执行动作了那么就成为切入点
spring定义了许多操作类型,如前置通知,后置通知,就是确定在方法的前面、后面执行之类的,这其实就是给不同的连接点起名字,这就是通知
首先我们要改变的是接口实现的类。那么我们直接对接口进行一系列操作就行了,我们把通知织入到被代理对象(就是接口),让它实现相应的功能即可。
我们可以通过两种方式完成aop。
AspectJ 意思就是Java的Aspect,Java的AOP。
写起来特别简单
首先在xml文件中配置两个对象:
user为被增强对象,myUser为增强对象

接下来设置aop代理

在execution语句中就是设置切点的位置
里面的语句格式如下:
第一个参数:*设置返回值范围的方法。
第二个参数:com表示包范围()
第三个参数:User表示类文件范围(第一个参数有空格)
第四个参数:add表示方法范围
第五个参数:(..)匹配了一个接受任意数量参数的方法(零或者更多)。
()匹配了一个不接受任何参数的方法,
(..)匹配了一个接受任意数量参数的方法(零或者更多)。
(*)匹配了一个接受一个任何类型的参数的方法。
(*,String)匹配了一个接受两个参数的方法,第一个可以是任意类型, 第二个则必须是String类型。
-
任意公共方法的执行:
execution(public * *(..)) -
任何一个名字以“set”开始的方法的执行:
execution(* set*(..)) -
AccountService接口定义的任意方法的执行:execution(* com.xyz.service.AccountService.*(..)) -
在service包中定义的任意方法的执行:
execution(* com.xyz.service.*.*(..)) -
在service包或其子包中定义的任意方法的执行:
execution(* com.xyz.service..*.*(..)) -
在service包中的任意连接点(在Spring AOP中只是方法执行):
within(com.xyz.service.*) -
在service包或其子包中的任意连接点(在Spring AOP中只是方法执行):
within(com.xyz.service..*) -
实现了
AccountService接口的代理对象的任意连接点 (在Spring AOP中只是方法执行):this(com.xyz.service.AccountService)
接下来看下注解方式实现aop编程,操作更为简单、
第一步相同,先配置bean文件
第二步:

第三步:
在被增强的类上设置@Aspect
被织入的方法上设置
@Before(value ="execution(* anno.User.*(..))")
Spring的事务:
传播行为
事务的第一个方面是传播行为(propagation behavior)。当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。Spring定义了七种传播行为:
| 传播行为 | 含义 |
|---|---|
| PROPAGATION_REQUIRED | 表示当前方法必须运行在事务中。如果当前事务存在,方法将会在该事务中运行。否则,会启动一个新的事务 |
| PROPAGATION_SUPPORTS | 表示当前方法不需要事务上下文,但是如果存在当前事务的话,那么该方法会在这个事务中运行 |
| PROPAGATION_MANDATORY | 表示该方法必须在事务中运行,如果当前事务不存在,则会抛出一个异常 |
| PROPAGATION_REQUIRED_NEW | 表示当前方法必须运行在它自己的事务中。一个新的事务将被启动。如果存在当前事务,在该方法执行期间,当前事务会被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NOT_SUPPORTED | 表示该方法不应该运行在事务中。如果存在当前事务,在该方法运行期间,当前事务将被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NEVER | 表示当前方法不应该运行在事务上下文中。如果当前正有一个事务在运行,则会抛出异常 |
| PROPAGATION_NESTED | 表示如果当前已经存在一个事务,那么该方法将会在嵌套事务中运行。嵌套的事务可以独立于当前事务进行单独地提交或回滚。如果当前事务不存在,那么其行为与PROPAGATION_REQUIRED一样。注意各厂商对这种传播行为的支持是有所差异的。可以参考资源管理器的文档来确认它们是否支持嵌套事务 |
注:以下具体讲解传播行为的内容参考自Spring事务机制详解
(1)PROPAGATION_REQUIRED 如果存在一个事务,则支持当前事务。如果没有事务则开启一个新的事务。
//事务属性 PROPAGATION_REQUIRED
methodA{
……
methodB();
……
}//事务属性 PROPAGATION_REQUIRED
methodB{
……
}使用spring声明式事务,spring使用AOP来支持声明式事务,会根据事务属性,自动在方法调用之前决定是否开启一个事务,并在方法执行之后决定事务提交或回滚事务。
单独调用methodB方法:
main{
metodB();
} 相当于
Main{
Connection con=null;
try{
con = getConnection();
con.setAutoCommit(false);
//方法调用
methodB();
//提交事务
con.commit();
} Catch(RuntimeException ex) {
//回滚事务
con.rollback();
} finally {
//释放资源
closeCon();
}
} Spring保证在methodB方法中所有的调用都获得到一个相同的连接。在调用methodB时,没有一个存在的事务,所以获得一个新的连接,开启了一个新的事务。
单独调用MethodA时,在MethodA内又会调用MethodB.
执行效果相当于:
main{
Connection con = null;
try{
con = getConnection();
methodA();
con.commit();
} catch(RuntimeException ex) {
con.rollback();
} finally {
closeCon();
}
} 调用MethodA时,环境中没有事务,所以开启一个新的事务.当在MethodA中调用MethodB时,环境中已经有了一个事务,所以methodB就加入当前事务。
(2)PROPAGATION_SUPPORTS 如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行。但是对于事务同步的事务管理器,PROPAGATION_SUPPORTS与不使用事务有少许不同。
//事务属性 PROPAGATION_REQUIRED
methodA(){
methodB();
}
//事务属性 PROPAGATION_SUPPORTS
methodB(){
……
}单纯的调用methodB时,methodB方法是非事务的执行的。当调用methdA时,methodB则加入了methodA的事务中,事务地执行。
(3)PROPAGATION_MANDATORY 如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
//事务属性 PROPAGATION_REQUIRED
methodA(){
methodB();
}
//事务属性 PROPAGATION_MANDATORY
methodB(){
……
}当单独调用methodB时,因为当前没有一个活动的事务,则会抛出异常throw new IllegalTransactionStateException(“Transaction propagation ‘mandatory’ but no existing transaction found”);当调用methodA时,methodB则加入到methodA的事务中,事务地执行。
(4)PROPAGATION_REQUIRES_NEW 总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
//事务属性 PROPAGATION_REQUIRED
methodA(){
doSomeThingA();
methodB();
doSomeThingB();
}
//事务属性 PROPAGATION_REQUIRES_NEW
methodB(){
……
}调用A方法:
main(){
methodA();
}相当于
main(){
TransactionManager tm = null;
try{
//获得一个JTA事务管理器
tm = getTransactionManager();
tm.begin();//开启一个新的事务
Transaction ts1 = tm.getTransaction();
doSomeThing();
tm.suspend();//挂起当前事务
try{
tm.begin();//重新开启第二个事务
Transaction ts2 = tm.getTransaction();
methodB();
ts2.commit();//提交第二个事务
} Catch(RunTimeException ex) {
ts2.rollback();//回滚第二个事务
} finally {
//释放资源
}
//methodB执行完后,恢复第一个事务
tm.resume(ts1);
doSomeThingB();
ts1.commit();//提交第一个事务
} catch(RunTimeException ex) {
ts1.rollback();//回滚第一个事务
} finally {
//释放资源
}
}在这里,我把ts1称为外层事务,ts2称为内层事务。从上面的代码可以看出,ts2与ts1是两个独立的事务,互不相干。Ts2是否成功并不依赖于 ts1。如果methodA方法在调用methodB方法后的doSomeThingB方法失败了,而methodB方法所做的结果依然被提交。而除了 methodB之外的其它代码导致的结果却被回滚了。使用PROPAGATION_REQUIRES_NEW,需要使用 JtaTransactionManager作为事务管理器。
(5)PROPAGATION_NOT_SUPPORTED 总是非事务地执行,并挂起任何存在的事务。使用PROPAGATION_NOT_SUPPORTED,也需要使用JtaTransactionManager作为事务管理器。(代码示例同上,可同理推出)
(6)PROPAGATION_NEVER 总是非事务地执行,如果存在一个活动事务,则抛出异常。
(7)PROPAGATION_NESTED如果一个活动的事务存在,则运行在一个嵌套的事务中. 如果没有活动事务, 则按TransactionDefinition.PROPAGATION_REQUIRED 属性执行。这是一个嵌套事务,使用JDBC 3.0驱动时,仅仅支持DataSourceTransactionManager作为事务管理器。需要JDBC 驱动的java.sql.Savepoint类。有一些JTA的事务管理器实现可能也提供了同样的功能。使用PROPAGATION_NESTED,还需要把PlatformTransactionManager的nestedTransactionAllowed属性设为true;而 nestedTransactionAllowed属性值默认为false。
//事务属性 PROPAGATION_REQUIRED
methodA(){
doSomeThingA();
methodB();
doSomeThingB();
}
//事务属性 PROPAGATION_NESTED
methodB(){
……
}如果单独调用methodB方法,则按REQUIRED属性执行。如果调用methodA方法,相当于下面的效果:
main(){
Connection con = null;
Savepoint savepoint = null;
try{
con = getConnection();
con.setAutoCommit(false);
doSomeThingA();
savepoint = con2.setSavepoint();
try{
methodB();
} catch(RuntimeException ex) {
con.rollback(savepoint);
} finally {
//释放资源
}
doSomeThingB();
con.commit();
} catch(RuntimeException ex) {
con.rollback();
} finally {
//释放资源
}
}当methodB方法调用之前,调用setSavepoint方法,保存当前的状态到savepoint。如果methodB方法调用失败,则恢复到之前保存的状态。但是需要注意的是,这时的事务并没有进行提交,如果后续的代码(doSomeThingB()方法)调用失败,则回滚包括methodB方法的所有操作。
嵌套事务一个非常重要的概念就是内层事务依赖于外层事务。外层事务失败时,会回滚内层事务所做的动作。而内层事务操作失败并不会引起外层事务的回滚。
PROPAGATION_NESTED 与PROPAGATION_REQUIRES_NEW的区别:它们非常类似,都像一个嵌套事务,如果不存在一个活动的事务,都会开启一个新的事务。使用 PROPAGATION_REQUIRES_NEW时,内层事务与外层事务就像两个独立的事务一样,一旦内层事务进行了提交后,外层事务不能对其进行回滚。两个事务互不影响。两个事务不是一个真正的嵌套事务。同时它需要JTA事务管理器的支持。
使用PROPAGATION_NESTED时,外层事务的回滚可以引起内层事务的回滚。而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。DataSourceTransactionManager使用savepoint支持PROPAGATION_NESTED时,需要JDBC 3.0以上驱动及1.4以上的JDK版本支持。其它的JTA TrasactionManager实现可能有不同的支持方式。
PROPAGATION_REQUIRES_NEW 启动一个新的, 不依赖于环境的 “内部” 事务. 这个事务将被完全 commited 或 rolled back 而不依赖于外部事务, 它拥有自己的隔离范围, 自己的锁, 等等. 当内部事务开始执行时, 外部事务将被挂起, 内务事务结束时, 外部事务将继续执行。
另一方面, PROPAGATION_NESTED 开始一个 “嵌套的” 事务, 它是已经存在事务的一个真正的子事务. 潜套事务开始执行时, 它将取得一个 savepoint. 如果这个嵌套事务失败, 我们将回滚到此 savepoint. 潜套事务是外部事务的一部分, 只有外部事务结束后它才会被提交。
由此可见, PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED 的最大区别在于, PROPAGATION_REQUIRES_NEW 完全是一个新的事务, 而 PROPAGATION_NESTED 则是外部事务的子事务, 如果外部事务 commit, 嵌套事务也会被 commit, 这个规则同样适用于 roll back.
PROPAGATION_REQUIRED应该是我们首先的事务传播行为。它能够满足我们大多数的事务需求。
2.2.2 隔离级别
事务的第二个维度就是隔离级别(isolation level)。隔离级别定义了一个事务可能受其他并发事务影响的程度。
(1)并发事务引起的问题
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务。并发虽然是必须的,但可能会导致一下的问题。
- 脏读(Dirty reads)——脏读发生在一个事务读取了另一个事务改写但尚未提交的数据时。如果改写在稍后被回滚了,那么第一个事务获取的数据就是无效的。
- 不可重复读(Nonrepeatable read)——不可重复读发生在一个事务执行相同的查询两次或两次以上,但是每次都得到不同的数据时。这通常是因为另一个并发事务在两次查询期间进行了更新。
- 幻读(Phantom read)——幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录。
不可重复读与幻读的区别
不可重复读的重点是修改:
同样的条件, 你读取过的数据, 再次读取出来发现值不一样了
例如:在事务1中,Mary 读取了自己的工资为1000,操作并没有完成
con1 = getConnection();
select salary from employee empId ="Mary"; 在事务2中,这时财务人员修改了Mary的工资为2000,并提交了事务.
con2 = getConnection();
update employee set salary = 2000;
con2.commit(); 在事务1中,Mary 再次读取自己的工资时,工资变为了2000
//con1
select salary from employee empId ="Mary"; 在一个事务中前后两次读取的结果并不一致,导致了不可重复读。
幻读的重点在于新增或者删除:
同样的条件, 第1次和第2次读出来的记录数不一样
例如:目前工资为1000的员工有10人。事务1,读取所有工资为1000的员工。
con1 = getConnection();
Select * from employee where salary =1000; 共读取10条记录
这时另一个事务向employee表插入了一条员工记录,工资也为1000
con2 = getConnection();
Insert into employee(empId,salary) values("Lili",1000);
con2.commit(); 事务1再次读取所有工资为1000的员工
//con1
select * from employee where salary =1000; 共读取到了11条记录,这就产生了幻像读。
从总的结果来看, 似乎不可重复读和幻读都表现为两次读取的结果不一致。但如果你从控制的角度来看, 两者的区别就比较大。
对于前者, 只需要锁住满足条件的记录。
对于后者, 要锁住满足条件及其相近的记录。
(2)隔离级别
| 隔离级别 | 含义 |
|---|---|
| ISOLATION_DEFAULT | 使用后端数据库默认的隔离级别 |
| ISOLATION_READ_UNCOMMITTED | 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读 |
| ISOLATION_READ_COMMITTED | 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生 |
| ISOLATION_REPEATABLE_READ | 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生 |
| ISOLATION_SERIALIZABLE | 最高的隔离级别,完全服从ACID的隔离级别,确保阻止脏读、不可重复读以及幻读,也是最慢的事务隔离级别,因为它通常是通过完全锁定事务相关的数据库表来实现的 |
2.2.3 只读
事务的第三个特性是它是否为只读事务。如果事务只对后端的数据库进行该操作,数据库可以利用事务的只读特性来进行一些特定的优化。通过将事务设置为只读,你就可以给数据库一个机会,让它应用它认为合适的优化措施。
2.2.4 事务超时
为了使应用程序很好地运行,事务不能运行太长的时间。因为事务可能涉及对后端数据库的锁定,所以长时间的事务会不必要的占用数据库资源。事务超时就是事务的一个定时器,在特定时间内事务如果没有执行完毕,那么就会自动回滚,而不是一直等待其结束。
2.2.5 回滚规则
事务五边形的最后一个方面是一组规则,这些规则定义了哪些异常会导致事务回滚而哪些不会。默认情况下,事务只有遇到运行期异常时才会回滚,而在遇到检查型异常时不会回滚(这一行为与EJB的回滚行为是一致的)
但是你可以声明事务在遇到特定的检查型异常时像遇到运行期异常那样回滚。同样,你还可以声明事务遇到特定的异常不回滚,即使这些异常是运行期异常。
2.3 事务状态
上面讲到的调用PlatformTransactionManager接口的getTransaction()的方法得到的是TransactionStatus接口的一个实现,这个接口的内容如下:
public interface TransactionStatus{
boolean isNewTransaction(); // 是否是新的事物
boolean hasSavepoint(); // 是否有恢复点
void setRollbackOnly(); // 设置为只回滚
boolean isRollbackOnly(); // 是否为只回滚
boolean isCompleted; // 是否已完成
} 可以发现这个接口描述的是一些处理事务提供简单的控制事务执行和查询事务状态的方法,在回滚或提交的时候需要应用对应的事务状态。
3 编程式事务
3.1 编程式和声明式事务的区别
Spring提供了对编程式事务和声明式事务的支持,编程式事务允许用户在代码中精确定义事务的边界,而声明式事务(基于AOP)有助于用户将操作与事务规则进行解耦。
简单地说,编程式事务侵入到了业务代码里面,但是提供了更加详细的事务管理;而声明式事务由于基于AOP,所以既能起到事务管理的作用,又可以不影响业务代码的具体实现。