Mysql的一级缓存:
一级缓存基于sqlSession默认开启,在操作数据库时需要构造SqlSession对象,在对象中有一个HashMap用于存储缓存数据。不同的SqlSession之间的缓存数据区域是互相不影响的。
一级缓存的作用域是SqlSession范围的,当在同一个sqlSession中执行两次相同的sql语句时,第一次执行完毕会将数据库中查询的数据写到缓存(内存),
第二次查询时会从缓存中获取数据,不再去底层数据库查询,从而提高查询效率。
二级缓存是mapper级别的缓存。使用二级缓存时,多个SqlSession使用同一个Mapper的sql语句去操作数据库,得到的数据会存在二级缓存区域,它同样是使用HashMap进行数据存储。相比一级缓存SqlSession,二级缓存的范围更大,多个Sqlsession可以共用二级缓存,二级缓存是跨SqlSession的。
二级缓存的作用域是mapper的同一个namespace。不同的sqlSession两次执行相同的namespace下的sql语句,且向sql中传递的参数也相同,即最终执行相同的sql语句,则第一次执行完毕会将数据库中查询的数据写到缓存,第二次查询会从缓存中获取数据,不再去底层数据库查询,从而提高效率。
(1) 在核心配置文件SqlMapConfig.xml中settings标签中加入下面开启总缓存(默认就是开启的)
<setting name="cacheEnabled" value="true"/>
(2)在UserMapper.xml中开启二缓存(开启之后对象需要实现序列化接口:Serializable 为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一定在内存。)
<cache/>
注意:开启二级缓存后对应的pojo需要实现序列化,因为二级缓存不只在内存
当进行了commit也就是增删改操作时,两个缓存都会刷新,但是二级缓存可以设置不刷新,但是会造成脏读。
延迟加载:
当需要查询两个表的连接内容,但是可能第二个表并不一定需要,我们则可以指定第二个表进行延迟加载,就是需要才加载,通过associate和collection实现
一对多,一对一:
一对一使用association,将结果映射到单个对象
一对多使用collection,将结果映射至集合
注意,如果两个表中的名称有一致的,那么必须定义别名使名称不相同,否则会有不可预估的错误
<mapper namespace="com.lcb.mapping.userMapper">
<!--association 一对一关联查询 -->
<select id="getClass" parameterType="int" resultMap="ClassesResultMap">
select * from class c,teacher t where c.teacher_id=t.t_id and c.c_id=#{id}
</select>
<resultMap type="com.lcb.user.Classes" id="ClassesResultMap">
<!-- 实体类的字段名和数据表的字段名映射 -->
<id property="id" column="c_id"/>
<result property="name" column="c_name"/>
<association property="teacher" javaType="com.lcb.user.Teacher">
<id property="id" column="t_id"/>
<result property="name" column="t_name"/>
</association>
</resultMap>
<!--collection 一对多关联查询 -->
<select id="getClass2" parameterType="int" resultMap="ClassesResultMap2">
select * from class c,teacher t,student s where c.teacher_id=t.t_id and c.c_id=s.class_id and c.c_id=#{id}
</select>
<resultMap type="com.lcb.user.Classes" id="ClassesResultMap2">
<id property="id" column="c_id"/>
<result property="name" column="c_name"/>
<association property="teacher" javaType="com.lcb.user.Teacher">
<id property="id" column="t_id"/>
<result property="name" column="t_name"/>
</association>
<collection property="student" ofType="com.lcb.user.Student">
<id property="id" column="s_id"/>
<result property="name" column="s_name"/>
</collection>
</resultMap>
</mapper> sql动态语句:
#{}和${}的区别
#{}表示一个占位符:
1、#将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号
2、#在很大程度上可以防止sql注入
3、例如#{id}:#{}中的id表示输入的参数名称,如果输入参数是简单类型,那么#{}中的参数可以任意。
1、${}将传入的数据直接显示生成在sql中。
2、如果使用${},而你传入的是字符串,比如中文、英文。就必须这样:'${}',不然会报(Unknown column 'TT' in 'where clause')的错误,当然传入数字没问题。
3、${value}: ${}中value表示输入的参数名称,如果输入的参数是简单类型,那么${}中的值只能是value
4、${}存在sql注入的风险,慎用!但是在特殊场景下必须使用${},比如order by 语句后面要跟动态列,就得使用${colname}
模糊查询like语句该怎么写?
第1种:在Java代码中添加sql通配符。
string wildcardname = “%smi%”;
list<name> names = mapper.selectlike(wildcardname);
<select id=”selectlike”>
select * from foo where bar like #{value}
</select>第2种:在sql语句中拼接通配符,会引起sql注入
string wildcardname = “smi”;
list<name> names = mapper.selectlike(wildcardname);
<select id=”selectlike”>
select * from foo where bar like "%"#{value}"%"
</select>第三种:通过$
select * from foo where bar like "%${要存的} %"当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
第1种:用resultType的话, 通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致 。
<select id=”selectorder” parametertype=”int” resultetype=”me.gacl.domain.order”>
select order_id id, order_no orderno ,order_price price form orders where order_id=#{id};
</select>
第2种: 通过<resultMap>来映射字段名和实体类属性名的一一对应的关系
<select id="getOrder" parameterType="int" resultMap="orderresultmap">
select * from orders where order_id=#{id}
</select>
<resultMap type=”me.gacl.domain.order” id=”orderresultmap”>
<!–用id属性来映射主键字段–>
<id property=”id” column=”order_id”>
<!–用result属性来映射非主键字段,property为实体类属性名,column为数据表中的属性–>
<result property = “orderno” column =”order_no”/>
<result property=”price” column=”order_price” />
</reslutMap>4、通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。在Mybatis中,每一个<select>、<insert>、<update>、<delete>标签,都会被解析为一个MappedStatement对象。
Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。如何传入多个参数:
1.在xml中的select语句中,每个参数按照mapper文件的方法参数顺序,依次将查询条件写为#{arg0},#{arg1}等

2.通过注解的方式实现

这样设置后在xml文件中将参数改为注解中设置的属性名称就好了。
3.通过一个map实现
我们把属性名存入key,把要存的值存入value,设置这个方法接受一个map类型就可以了,我们就可以根据key的值传value

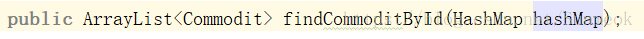

4.新建一个类,把要查询的字段在里面建立,通过传入这个类就可以完成。新的类的字段名要和#{}内的名字相同

其实第三种和第四种大同小异。
Mybatis动态sql是做什么的?都有哪些动态sql?能简述一下动态sql的执行原理不?
Mybatis动态sql可以让我们在Xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能。
Mybatis提供了9种动态sql标签:trim|where|set|foreach|if|choose|when|otherwise|bind。
Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式?
第一种用<resultMap>,将列名和属性名经过设置一一对应,
第二种通过<resultType>,只有将属性名和列名的名称设为一致才可以,可以通过给列名定义别名
有了列名与属性名的映射关系后,Mybatis通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。
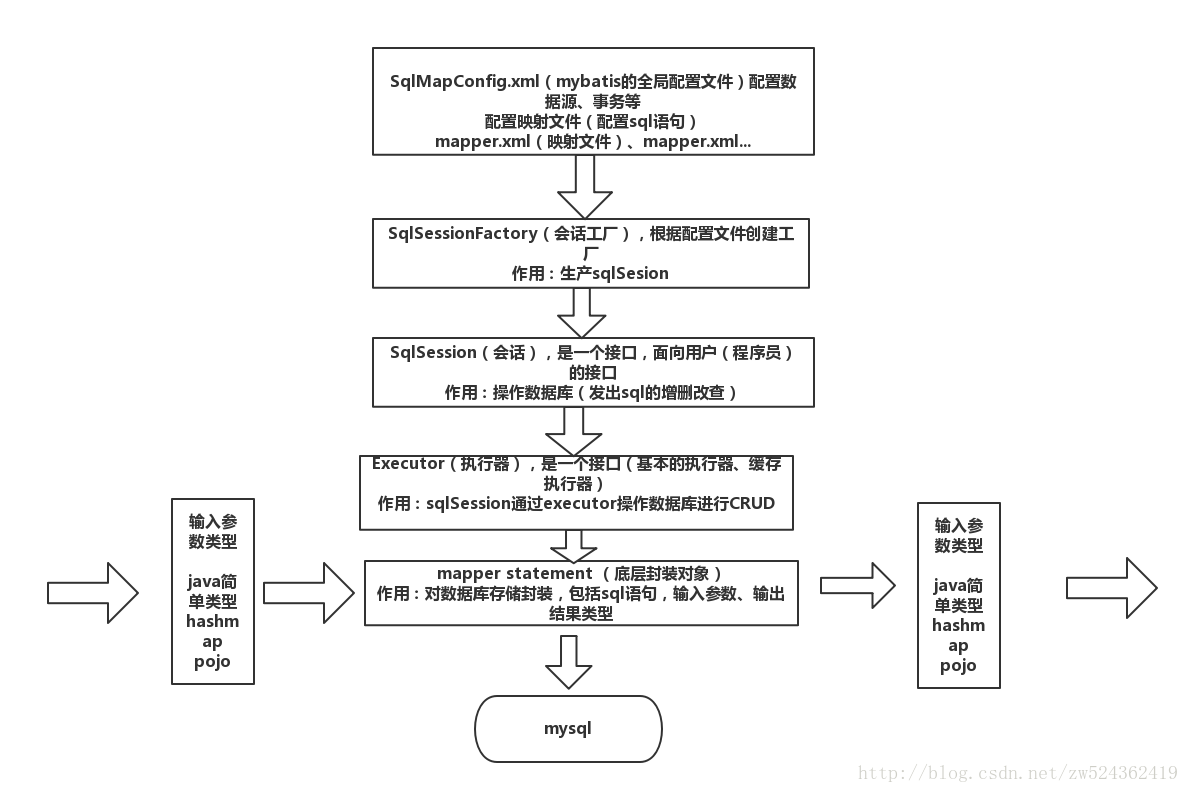
mybaits分页:
将分页的详情当做参数传进去。