事务管理是Pager模块中最核心的要素,所有对数据库数据的读写操作都在事务中进行。一个数据库需要在多线程的使用环境下保持数据的一致性,虽然操作系统对磁盘的读写操作并不是原子,但是通过事务以及日志的回滚机制使每一个事务的执行都是原子的,所以即使出现系统崩溃或断电,数据库并不会因此而损坏。
在一个事务中,SQLite的Pager模块通过有机地结合文件锁,回滚日志和页缓存来实现数据库的ACID特性。在用户程序并发访问数据库时,可以支持一个写事务和多个读事务,由于SQLite只实现了较粗粒度的文件锁,同一时间最多只能有一个写事务。
事务分为系统事务和用户事务,用户事务需要用BEGIN TRANSACTION和和COMMIT TRANSACTION明确指出事务的开始和结束,没有明确指出时为系统事务,SQLite在每执行一条SQL语句时都会创建一个事务。本文主要讲的是系统事务,系统事务又分为读事务和写事务。
1. 事务状态
在SQLite数据库中,事务分为7个状态,Pager.eState变量存储当前事务的状态,这7个状态的宏定义如下:
#define PAGER_OPEN 0
#define PAGER_READER 1
#define PAGER_WRITER_LOCKED 2
#define PAGER_WRITER_CACHEMOD 3
#define PAGER_WRITER_DBMOD 4
#define PAGER_WRITER_FINISHED 5
#define PAGER_ERROR 6OPEN状态为事务的初始状态,此时没有加任何锁,不能对数据库进行读写操作。在PAGER_READER中,意味着Pager模块已经获得了共享锁,可以开始一个读事务。WRITER_LOCKED状态表示数据库开始一个写事务,此时获取了RESERVED锁,但是并没有对数据库进行写操作,在这个状态下打开了一个回滚日志并往头部写入信息,其他读事务可以正常进行。在WRITER_CACHEMOD状态中,tree模块可以向页缓存里写数据,同时还要先把原始数据备份到日志里,在WRITER_DBMOD中,RESERVED锁被升级为独占锁,此时更新日志头里的记录数,并把日志文件和修改的数据库页面刷新到磁盘里。在WRITER_FINISHED状态里,结束一个写事务,将锁恢复成共享锁或无锁状态。如果出现I/O读写操作错误,此时将跳入ERROR状态,在错误状态下任何对数据库的读写操作都会无效,错误将会返回到b-tree层处理。在源代码的注释中有对这些状态更详细的说明。
各个状态的流程关系如下图
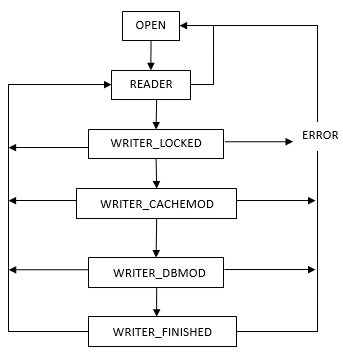
相应的关系转换函数如下
** OPEN -> READER [sqlite3PagerSharedLock]
** READER -> OPEN [pager_unlock]
**
** READER -> WRITER_LOCKED [sqlite3PagerBegin]
** WRITER_LOCKED -> WRITER_CACHEMOD [pager_open_journal]
** WRITER_CACHEMOD -> WRITER_DBMOD [syncJournal]
** WRITER_DBMOD -> WRITER_FINISHED [sqlite3PagerCommitPhaseOne]
** WRITER_*** -> READER [pager_end_transaction]
**
** WRITER_*** -> ERROR [pager_error]
** ERROR -> OPEN [pager_unlock]在一个事务中,文件锁对事务的原子性和隔离性起到了非常重要的作用,锁的状态保存在Pager.Lock里,在读事务时需要先获取共享锁,开始一个写事务时将共享锁升级为保留锁,最后提交时再升级为独占锁,如果需要日志回滚则直接从共享锁升级为独占锁,锁的各种状态转换如下图所示
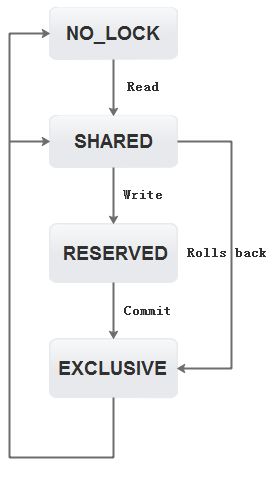
2. 读事务
在开始一个读事务时,需要获取文件共享锁,多个共享锁可以同时存在,共享锁不能和独占锁共存,当其他线程有写事务时,在把修改的数据页提交到磁盘的时候会获取独占锁,此时将不能开始一个读事务。
在开始一个读事务之前,首先要判断有没有热日志存在,如果有热日志存在,表明上一个写事务时存在系统崩溃的情况,数据库可能损坏,需要回滚日志来恢复数据的原始内容。
由于事务的实现有很多繁琐的细节,下面贴出的代码都略去细节,只从主干的逻辑来分析代码的实现过程。
每一个事务由B-Tree模块调用sqlite3BtreeBeginTrans()函数发起,然后由lockBtree()函数获取共享锁和数据库文件的第一页数据,数据库的第一页并不存储数据,而是存储数据库的相关信息。如果没有获取成功,将会持续循环直到成功为止。
while( pBt->pPage1==0 &&SQLITE_OK==(rc = lockBtree(pBt)) );
lockBtree()做的工作主要是以下3部分:
1.获取共享锁
rc = sqlite3PagerSharedLock(pBt->pPager);
2.获取第一页数据
rc =btreeGetPage(pBt, 1, &pPage1, 0);
3.根据第一页数据校验数据库的有效性
在sqlite3PagerSharedLock()除了获取共享锁之外,如果存在热日志,还需要对日志回滚来恢复数据库内容,实现代码如下,省去了变量的定义、各种条件判断和错误处理
int sqlite3PagerSharedLock(Pager *pPager){
//获取共享锁,如果需要在失败后重复尝试
//可以设置xBusyHandler回调函数来等待成功或超时
rc = pager_wait_on_lock(pPager, SHARED_LOCK);
/*判断是否为热日志,做的工作有以下3点
** 1.判断是否存在保留锁,如果存在,说明存在其他写事务,此
** 日志是刚创建的,并非热日志。
** 2.如果数据库文件长度为0,说明是一个这是一个新的数据库
** 文件,不需要回滚,只需删除日志即可
** 3.如果不存在保留锁,读取日志文件的第一个字节,如果不为0
** 此时判定日志文件为热日志
*/
if( pPager->eLock<=SHARED_LOCK ){
rc = hasHotJournal(pPager, &bHotJournal);
}
//如果存在热日志,开始回滚
if( bHotJournal ){
//先获取独占锁
rc = pagerLockDb(pPager, EXCLUSIVE_LOCK);
//打开日志文件
……
//回滚前先同步日志,这里没看懂
//回滚的时候并没有改变日志的内容,似乎不需要
rc = pagerSyncHotJournal(pPager);
//开始回滚
rc = pager_playback(pPager, !pPager->tempFile);
//回滚完毕后,将锁恢复为共享锁
pagerUnlockDb(pPager, SHARED_LOCK);
}
//获取共享锁后,判断数据库是否更改,根据第一页的
//第24字节的File change counter来判断
//如果有更改,将页缓存里的内容丢弃
rc = sqlite3OsRead(pPager->fd, &dbFileVers, sizeof(dbFileVers), 24);
if( memcmp(pPager->dbFileVers, dbFileVers, sizeof(dbFileVers))!=0 ){
pager_reset(pPager);
}
//更改事务状态为PAGER_READER
pPager->eState = PAGER_READER;
pPager->hasHeldSharedLock = 1;
}pager_playback()函数就是把日志里的内容回滚到数据库,首先从日志头里读取记录数,将每一个记录页写回到数据库磁盘文件,简要代码如下
static int pager_playback(Pager *pPager, int isHot){
//读取文件长度
rc = sqlite3OsFileSize(pPager->jfd, &szJ);
while( 1 ){
//读取记录数,存在nRec变量里
rc = readJournalHdr(pPager, isHot, szJ, &nRec, &mxPg);
for(u=0; u<nRec; u++){
//根据journalOff读取日志页,日志页的头部记录了页号
//根据页号把数据页写入到数据库文件的对应位置
rc = pager_playback_one_page(pPager,&pPager->journalOff,0,1,0);
}
}
}在得到共享锁后,就可以调用sqlite3PagerGet()来读取数据页了,这个函数调用了pPager->xGet()接口,如果使用Mmap,注册的是getPageMMap,否则注册的是getPageNormal,getPageNormal的实现如下
static int getPageNormal(
Pager *pPager, /* The pager open on the database file */
Pgno pgno, /* Page number to fetch */
DbPage **ppPage, /* Write a pointer to the page here */
int flags /* PAGER_GET_XXX flags */
){
//从页缓存中获取数据页
pBase = sqlite3PcacheFetch(pPager->pPCache, pgno, 3);
//如果获取失败,释放掉未使用的页
if( pBase==0 ){
rc = sqlite3PcacheFetchStress(pPager->pPCache, pgno, &pBase);
}
//初始化pPg的一些信息
pPg = *ppPage = sqlite3PcacheFetchFinish(pPager->pPCache, pgno, pBase);
//如果pPg->pPager存在,说明页缓存里已经有数据,cache命中
//直接返回cache中的结果即可
if( pPg->pPager && !noContent ){
pPager->aStat[PAGER_STAT_HIT]++;
return SQLITE_OK;
}else{
//如果没有命中,先设置数据页对应的Pager对象
pPg->pPager = pPager;
//如果不需要数据,将数据区初始化为0
if( !isOpen(pPager->fd) || pPager->dbSize<pgno || noContent ){
memset(pPg->pData, 0, pPager->pageSize);
} else{
//否则从磁盘中读取数据
//根据pPg->pgno和pPager->pageSize找到偏移地址
// iFrame用作WAL模式,暂时不管
rc = readDbPage(pPg, iFrame);
}
}
}每读一页数据都要对应地调用sqlite3PagerUnref ()来释放对这一页的引用,如果没有其他事务引用数据页,则将该页添加到LRU链表里,读完数据后调用btreeEndTransaction()来结束一个读事务,如果btree里没有其他事务了,那么调用releasePageNotNull(pPage1)释放数据库的第一页数据,如果pPCache里没有页被引用,调用pager_unlock(pPager)释放共享锁,将事务恢复到OPEN状态
3. 写事务
一个写事务是在一个读事务的基础上进行的,因为开始一个写事务时也要先获取共享锁,读取要修改的数据页到内存,在此基础上再把共享锁升级为保留锁,从而开始一个写事务。
按照第一节描述的事务状态的变化来一步步分析写事务是如何完成的:
1. sqlite3PagerBegin
此时开始一个写事务,获取保留锁,将事务状态升级为WRITER_LOCKED
2. pager_open_journal
此时打开一个日志文件,并向日志头里写入初始化信息,把事务状态升级为WRITER_CACHEMOD,相关代码如下:
if( rc==SQLITE_OK ){
rc = sqlite3JournalOpen (
pVfs, pPager->zJournal, pPager->jfd, flags, nSpill
);
}
if( rc==SQLITE_OK ){
/* TODO: Check if all of these are really required. */
pPager->nRec = 0;
pPager->journalOff = 0;
pPager->setMaster = 0;
pPager->journalHdr = 0;
rc = writeJournalHdr(pPager);
}
pPager->eState = PAGER_WRITER_CACHEMOD;3. sqlite3PagerWrite
将要写的页加入到页缓存的dirty链表里面,把页的flag设为可写
pPg->flags |= PGHDR_WRITEABLE;
如果页号小于数据库长度,将页写入到日志文件
if( pPg->pgno<=pPager->dbOrigSize ){
rc = pagerAddPageToRollbackJournal(pPg);
if( rc!=SQLITE_OK ){
return rc;
}
}
static SQLITE_NOINLINE int pagerAddPageToRollbackJournal(PgHdr *pPg){
i64 iOff = pPager->journalOff;
//写入页号
rc = write32bits(pPager->jfd, iOff, pPg->pgno);
if( rc!=SQLITE_OK ) return rc;
//写入数据页内容
rc = sqlite3OsWrite(pPager->jfd, pData2, pPager->pageSize, iOff+4);
if( rc!=SQLITE_OK ) return rc;
//写入校验字节
rc = write32bits(pPager->jfd, iOff+pPager->pageSize+4, cksum);
//修改写日志的偏移地址
pPager->journalOff += 8 + pPager->pageSize;
//增加记录数
pPager->nRec++;
}如果页号大于数据库长度,此时要向数据库尾部添加新页,将flag置为PGHDR_NEED_SYNC,并变更数据库长度
pPg->flags |= PGHDR_NEED_SYNC;
if( pPager->dbSize<pPg->pgno ){
pPager->dbSize = pPg->pgno;
}此后b-tree层就可以对页缓存里的数据进行修改了。
4.sqlite3PagerCommitPhaseOne
当b-tree层已经对页缓存修改数据完毕,需要把修改提交到数据库,此时需要把锁升级为独占锁,在这段时间内不能开始新的读事务,如果还有正在进行的读事务先等其处理完毕。
提交事务时先调用pager_incr_changecounter()对文件的change counter加1,接着调用syncJournal()对日志刷盘,关于日志的部分已经在之前的文章已经讲过了,日志刷盘后会把事务状态更新为WRITER_DBMOD。
然后把所有的脏页都刷新到磁盘,关键代码如下
rc = pager_write_pagelist(pPager,sqlite3PcacheDirtyList(pPager->pPCache));
static int pager_write_pagelist(Pager *pPager, PgHdr *pList){
//遍历脏页链表写入数据
while( rc==SQLITE_OK && pList ){
Pgno pgno = pList->pgno;
i64 offset = (pgno-1)*(i64)pPager->pageSize;
rc = sqlite3OsWrite(pPager->fd, pData, pPager->pageSize, offset);
pList = pList->pDirty;
}
}写完后清理所有的脏页,把事务状态更新为WRITER_FINISHED
sqlite3PcacheCleanAll(pPager->pPCache);5.sqlite3PagerCommitPhaseTwo
此时数据库已经更新完毕,最后调用pager_end_transaction()结束整个写事务,把事务状态恢复到PAGER_READER,并删除日志文件,如果数据库文件长度变短,需要截断多余的文件内容,另外现在锁的状态还是独占锁,需要将锁降级为共享锁。
以上5点就是整个数据库写事务的过程,通过日志和文件锁实现了事务的原子提交特性。
4.参考资料
Atomic Commit In SQLite
http://www.sqlite.org/atomiccommit.html
SQLite的原子提交原理
https://blog.csdn.net/javensun/article/details/8515690
SQLite3源码学习(24) Pager模块之事务锁的实现1
https://blog.csdn.net/pfysw/article/details/80100236
SQLite3源码学习(26) Pager模块之日志管理
https://blog.csdn.net/pfysw/article/details/80191235
SQLite3源码学习(8)Pager模块概述及初始化
https://blog.csdn.net/pfysw/article/details/79121815
SQLite入门与分析(四)---Page Cache之事务处理(1)
http://www.cnblogs.com/hustcat/archive/2009/02/26/1398558.html
SQLite入门与分析(四)---Page Cache之事务处理(2)
http://www.cnblogs.com/hustcat/category/175618.html
SQLite入门与分析(四)---Page Cache之事务处理(3)
http://www.cnblogs.com/hustcat/archive/2009/02/26/1398826.html
SQLite学习笔记(七)&&事务处理