目录
二、NMS非极大值抑制(Non-Maximum Suppression)
三、Selective Search原则(Sliding Window→Selective Search)
-
一、IOU交并比
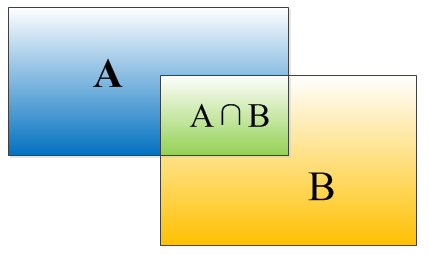
公式:IOU=(A∩B)/(A∪B)
-
二、NMS非极大值抑制(Non-Maximum Suppression)
①什么是NMS
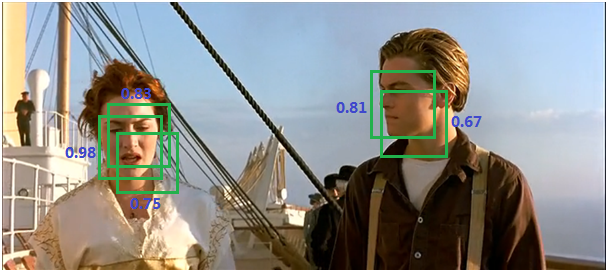
↓

缺点:当两个ground truth的目标的确重叠度很高时,NMS会将具有较低置信度的框去掉(置信度改成0)

②NMS loss
如果对每类分别进行NMS,那么当检测结果中包含两个被分到不同类别的目标且其IoU较大时,会得到不可接受的结果。
一种改进方式便是在损失函数中加入一部分NMS损失。NMS损失可以定义为与分类损失相同:Lnms=Lcls(p,u)=−logpuLnms=Lcls(p,u)=−logpu,即真实列别u对应的log损失,p是C个类别的预测概率。实际相当于增加分类误差。
参考论文《Rotated Region Based CNN for Ship Detection》(IEEE2017会议论文)的Multi-task for NMS部分。
③Soft-NMS
论文:《Improving Object Detection With One Line of Code》
Github项目:https://github.com/bharatsingh430/soft-nms
本文提出了一种新的软权重非最大抑制算法。它通过提供一个基于检测框重叠程度和检测分数的函数来实现。作者在传统贪心NMS算法的基础上提出了两种改进函数并对其在两个现有检测数据集上进行了验证。通过分析,基于检测框重叠程度和检测分数的软权重函数可以有效提升物体检测的准确率。

改进方法在于将置信度改为IoU的函数:f(IoU),具有较低的值而不至于从排序列表中删去.
-
线性函数
si={si,si(1−iou(M,bi)),iou(M,bi)<Ntiou(M,bi)≥Ntsi={si,iou(M,bi)<Ntsi(1−iou(M,bi)),iou(M,bi)≥Nt
函数值不连续,在某一点的值发生跳跃. -
高斯函数
si=sie−iou(M,bi)2σ,∀bi∉Dsi=sie−iou(M,bi)2σ,∀bi∉D
时间复杂度同传统的greedy-NMS,为O(N2)O(N2).
在基于proposal方法的模型结果上应用比较好,检测效果提升。

来源于:https://www.cnblogs.com/makefile/p/nms.html
-
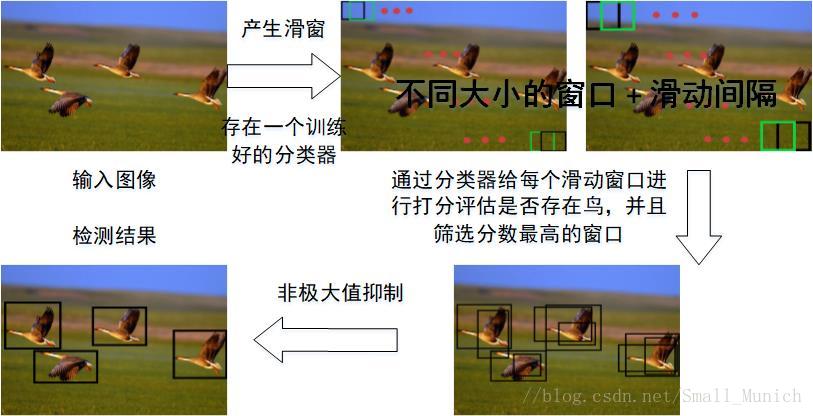
三、Selective Search原则(Sliding Window→Selective Search)
两种方法流程图对比:
Sliding Window
Selective Search
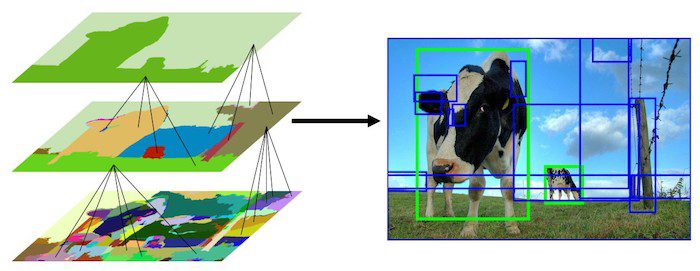
论文链接:http://koen.me/research/pub/uijlings-ijcv2013-draft.pdf
来源于:https://blog.csdn.net/small_munich/article/details/79595257 目标检测之Selective Search原理简述
四、region proposals
通过Selective Search生成region proposals(如上图框中所示)
五、SVM分类器
①什么是SVM分类器
②hard negative mining method
What is hard negative mining? And how is it helpful in doing that while training classifiers?
Answer:
Let's say I give you a bunch of images that contain one or more people, and I give you bounding boxes for each one. Your classifier will need both positive training examples (person) and negative training examples (not person).
For each person, you create a positive training example by looking inside that bounding box. But how do you create useful negative examples?
A good way to start is to generate a bunch of random bounding boxes, and for each that doesn't overlap with any of your positives, keep that new box as a negative.
Ok, so you have positives and negatives, so you train a classifier, and to test it out, you run it on your training images again with a sliding window. But it turns out that your classifier isn't very good, because it throws a bunch of false positives (people detected where there aren't actually people).
A hard negative is when you take that falsely detected patch, and explicitly create a negative example out of that patch, and add that negative to your training set. When you retrain your classifier, it should perform better with this extra knowledge, and not make as many false positives.
来源于:https://www.reddit.com/r/computervision/comments/2ggc5l/what_is_hard_negative_mining_and_how_is_it/
R-CNN关于hard negative mining的部分引用了两篇论文:
[17] P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models. TPAMI, 2010.
[37] K. Sung and T. Poggio. Example-based learning for viewbased human face detection. Technical Report A.I. Memo No. 1521, Massachussets Institute of Technology, 1994. 4
Bootstrapping methods train a model with an initial subset of negative examples, and then collect negative examples that are incorrectly classified by this initial model to form a set of hard negatives. A new model is trained with the hard negative examples, and the process may be repeated a few times.
we use the following “bootstrap” strategy that incrementally selects only those “nonface” patterns with high utility value:
1) Start with a small set of “nonface” examples in the training database.
2) Train the MLP classifier with the current database of examples.
3) Run the face detector on a sequence of random images. Collect all the “nonface” patterns that the current system wrongly classifies as “faces” (see Fig. 5b).Add these “nonface” patterns to the training database as new negative examples.
4) Return to Step 2.
在bootstrapping方法中,我们先用初始的正负样本(一般是正样本+与正样本同规模的负样本的一个子集)训练分类器,然后再用训练出的分类器对样本进行分类,把其中错误分类的那些样本(hard negative)放入负样本集合,再继续训练分类器,如此反复,直到达到停止条件(比如分类器性能不再提升).
we expect these new examples to help steer the classifier away from its current mistakes.
hard negative就是每次把那些顽固的棘手的错误,再送回去继续练,练到你的成绩不再提升为止.这一个过程就叫做'hard negative mining'.
来源于:https://www.zhihu.com/question/46292829
③SVM分类器正负样本的标准
对每个类都训练一个线性的SVM分类器,训练SVM需要正负样本文件,以完全包含该分类的为正样本,完全不包含的该分类region proposal为负样本,对于部分包含该分类物体的region proposal,则计算每一个region proposal与标准框的IOU值,IOU小于0.3的作为负样本,其他的全都丢弃。由于训练样本比较大,作者使用了standard hard negative mining method来训练分类器。作者在补充材料中讨论了为什么fine-tuning和训练SVM时所用的正负样本标准不一样,以及为什么不直接用卷积神经网络的输出来分类而要单独训练SVM来分类,作者提到,刚开始时只是用了ImageNet预训练了CNN,并用提取的特征训练了SVMs,此时用正负样本标记方法就是前面所述的0.3,(作者测试了IOU阈值各种方案数值0,0.1,0.2,0.3,0.4,0.5。最后我们通过训练发现,如果选择IOU阈值为0.3效果最好(选择为0精度下降了4个百分点,选择0.5精度下降了5个百分点),即当重叠度小于0.3的时候,我们就把它标注为负样本。)后来刚开始使用fine-tuning时,也使用了这个方法,但是发现结果很差,于是通过调试选择了0.5这个方法,作者认为这样可以加大样本的数量,从而避免过拟合。然而,IoU大于0.5为正样本会导致网络定位准确度的下降,故使用了SVM来做检测,全部使用ground-truth样本作为正样本,且使用非正样本的,且IoU大于0.3的“hard negatives”,提高了定位的准确度。
六、fine-tuning
①什么是fine-tuning
采用selective search 搜索出来的候选框,然后处理到指定大小图片,继续对上面预训练的cnn模型进行fine-tuning训练。假设要检测的物体类别有N类,那么我们就需要把上面预训练阶段的CNN模型的最后一层给替换掉,替换成N+1个输出的神经元(加1,表示还有一个背景),然后这一层直接采用参数随机初始化的方法,其它网络层的参数不变;接着就可以开始继续SGD训练了。开始的时候,SGD学习率选择0.001,在每次训练的时候,我们batch size大小选择128,其中32个是正样本、96个是负样本
②与不进行fine-tuning的对比
首先,反正CNN都是用于提取特征,那么我直接用Alexnet做特征提取,省去fine-tuning阶段可以吗?这个是可以的,你可以不需重新训练CNN,直接采用Alexnet模型,提取出p5、或者f6、f7的特征,作为特征向量,然后进行训练svm,只不过这样精度会比较低。那么问题又来了,没有fine-tuning的时候,要选择哪一层的特征作为cnn提取到的特征呢?我们有可以选择p5、f6、f7,这三层的神经元个数分别是9216、4096、4096。从p5到p6这层的参数个数是:4096*9216 ,从f6到f7的参数是4096*4096。那么具体是选择p5、还是f6,又或者是f7呢?
文献paper给我们证明了一个理论,如果你不进行fine-tuning,也就是你直接把Alexnet模型当做万金油使用,类似于HOG、SIFT一样做特征提取,不针对特定的任务。然后把提取的特征用于分类,结果发现p5的精度竟然跟f6、f7差不多,而且f6提取到的特征还比f7的精度略高;如果你进行fine-tuning了,那么f7、f6的提取到的特征最会训练的svm分类器的精度就会飙涨。
据此我们明白了一个道理,如果不针对特定任务进行fine-tuning,而是把CNN当做特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。打个比方:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征了。
还有另外一个疑问:CNN训练的时候,本来就是对bounding box的物体进行识别分类训练,是一个端到端的任务,在训练的时候最后一层softmax就是分类层,那么为什么作者闲着没事干要先用CNN做特征提取(提取fc7层数据),然后再把提取的特征用于训练svm分类器?这个是因为svm训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用svm精度还低。
事情是这样的,cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Bounding box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);
然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm。一旦CNN f7层特征被提取出来,那么我们将为每个物体累训练一个svm分类器。当我们用CNN提取2000个候选框,可以得到2000*4096这样的特征向量矩阵,然后我们只需要把这样的一个矩阵与svm权值矩阵4096*N点乘(N为分类类别数目,因为我们训练的N个svm,每个svm包好了4096个W),就可以得到结果了。
来源于:https://blog.csdn.net/hjimce/article/details/50187029
七、BoundingBox回归(分类网络、回归网络)
①为什么要做BoudingBox?

对红色框进行微调,使定位更准确
②回归、微调的对象

对于窗口一般使用四维向量( x,y w,h ) 来表示, 分别表示窗口的中心点坐标和宽高。 图中, 红色的框 P 代表原始的Proposal, 绿色的框 G 代表目标的 Ground Truth, 我们的目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口。
③BoudingBox Regression

注意: 只有当 Proposal 和 Ground Truth 比较接近时(线性问题),我们才能将其作为训练样本训练我们的线性回归模型, 否则会导致训练的回归模型不 work(当 Proposal跟 GT 离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理)。而我们要让预测GT与标定GT 之间的差值最小,得到损失函数:

