分析目的
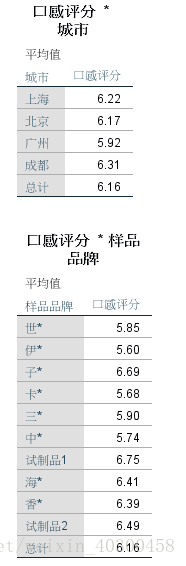
- 在10中种样品中,最受欢迎的是哪几种
- 消费者的口味在不同城市有什么不同
- 分析城市和品牌是否存在交互作用
交叉表

不同因素下均值描述
步骤:分析——比较均值——均值
条图显示不同品牌的口味评分均值(带误差线)

扫描二维码关注公众号,回复:
2481418 查看本文章

不同品牌评分分析
避免城市因素的干扰(可能存在交互项),对每个城市的样本分别进行分析
按城市分割文件
步骤:数据——拆分文件——选择城市作为分组依据
单因素方差分析
由于品牌的值为字符串变量,无法在比较均值——单因素ANONA分析中显示,因此采用一般线性模型——单因素即可

由上图可知,p<0.05,拒绝原假设:没有差异。推出在成都不同品牌间的评分是有显著性差异的(其他城市与上表类似,不再赘述)。
两两比较到底是哪几种品牌有明显的差异
S-N-K检验

不同子集的个体是有显著差异的,例如子集1中的"三*"和子集2中的"试制品2"
不同两两比较的检验选择:

单因素方差分析需要满足方差齐性检验

P>0.05,接受原假设,认为方差是相等的,满足方差齐性
建立包含交互效应的饱和模型的方差分析
步骤:分析——一般线性模型——单因素
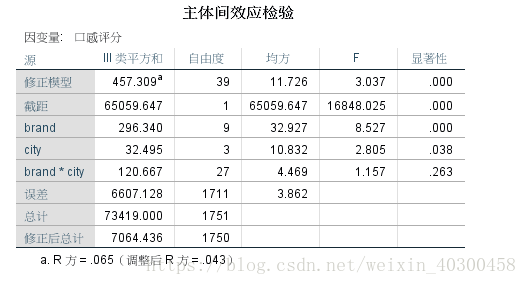
交互项的的p值>0.05,表明交互相关不显著。
剔除交互项,建立主效应的方差分析模型
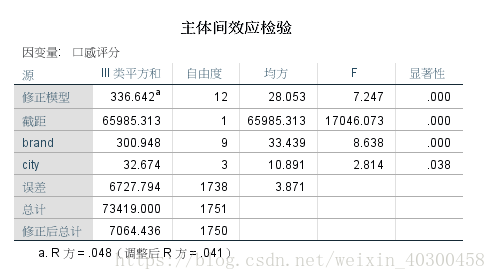
因为交互项的影响不显著,因此可以直接选择city和brand两两比较

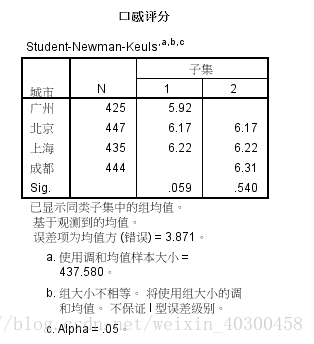
由上图可知,广州的评分比成都评分小好多,其他城市两两差异不明显;10种样品种,试制品1的评分最好,且香*、海*、子*、试制品1、试制品2的评分五明显差异。
python实现
交叉表
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use("ggplot")
data = pd.read_csv(r"C:\Users\Administrator\Desktop\city&brand.csv",encoding = "utf-8")
data.groupby(["city","brand"]).count().unstack() result
brand E F G H I J K L M N
city
1 40 40 37 45 37 51 48 48 43 46
2 44 41 42 44 36 47 42 46 53 52
3 33 43 46 51 57 36 48 38 36 37
4 45 38 44 38 43 48 44 44 55 45不同城市、品牌的评分均值
data.groupby(["city"]).result.mean()
city
1 6.222989
2 6.165548
3 5.920000
4 6.306306
Name: result, dtype: float64
data.groupby(["brand"]).result.mean()
brand
E 5.845679
F 5.598765
G 6.692308
H 5.679775
I 5.895954
J 5.736264
K 6.747253
L 6.409091
M 6.385027
N 6.494444
Name: result, dtype: float64
不同品牌的评分均值柱状图
brand_std = data.groupby(["brand"]).result.mean().std()
data_brand = data.groupby(["brand"]).result.mean()
data_brand.plot(kind = "bar",yerr = brand_std,error_kw ={'ecolor':"k","elinewidth":1,"capsize":4})
选取成都做单因素方差分析
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
data_chengdu = data[data["city"]==4]
model = ols("result ~ brand",data_chengdu).fit()
anovat = anova_lm(model)
print(anovat) df sum_sq mean_sq F PR(>F)
brand 9.0 129.160998 14.351222 4.205042 0.000031
Residual 434.0 1481.181344 3.412860 NaN NaN和spss的方差分析结果一样。
s-n-k检验没有在python相应的库中找到。。。。。。。。
建立包含交互效应的饱和模型(在python里,分类变量的值必须为字符串格式,后面改了过来,检验才正确)
tra_dict = {1:"上海",2:"北京",3:"广州",4:"成都"}
data.city = data.city.map(tra_dict)
formula = 'result ~ brand + city + brand:city'
anova_results = anova_lm(ols(formula,data).fit())
print(anova_results)
df sum_sq mean_sq F PR(>F)
brand 9.0 303.967975 33.774219 8.746265 6.030751e-13
city 3.0 32.674024 10.891341 2.820452 3.769134e-02
brand:city 27.0 120.666503 4.469130 1.157338 2.633372e-01
Residual 1711.0 6607.127820 3.861559 NaN NaN除了sum_sq有些差别外,其他值都是和spss检验一样的。
剔除交互项
formula = 'result ~ brand + city '
anova_results = anova_lm(ols(formula,data).fit())
print(anova_results)
df sum_sq mean_sq F PR(>F)
brand 9.0 303.967975 33.774219 8.724939 6.486587e-13
city 3.0 32.674024 10.891341 2.813575 3.803745e-02
Residual 1738.0 6727.794323 3.870998 NaN NaN完。