这是Recurrent Neural Network Tutorial的第二部分。
第一部分在这
代码在这个github上
在这一部分中,我们将使用Python从头开始实现完整的Recurrent Neural Network,并使用Theano优化我们的实现,用于在GPU上执行操作的库。完整的代码点击这。我将跳过一些对理解回归神经网络不重要的样板代码,但所有这些代码也在Github上。
语言模型
我们的目标是使用递归神经网络构建语言模型。 这就是这意味着什么。 假设我们有m个单词的句子。 语言模型允许我们预测观察句子(在给定数据集中)的概率为:
比如说,“he went to buy chocolate”的概率是
为什么这有用? 为什么我们要指定观察句子的概率?
首先,这种模型可以用作评分机制。例如,机器翻译系统通常为输入句子生成多个候选者。您可以使用语言模型来选择最可能的句子。直觉上,最可能的句子可能在语法上是正确的。 类似的评分发生在语音识别系统中。
但解决语言模型问题也有很酷的副作用。因为我们可以预测给出前面单词的单词的概率,所以我们能够生成新的文本。这是一个生成模型。 给定现有的单词序列,我们从预测的概率中抽取下一个单词,并重复该过程,直到我们有一个完整的句子。Andrej Karparthy有一篇很棒的文章,展示了语言模型的功能。 他的模型是针对单个字符而不是完整单词进行训练的,并且可以生成从莎士比亚到Linux代码的任何内容。
注意,在上面的等式中,每个单词的概率都取决于所有先前的单词。实际上,由于计算或内存限制,许多模型很难表示这种长期依赖性。它们通常仅限于仅查看前几个单词。 理论上,RNN可以捕获这种长期依赖性,但实际上它更复杂一些。 我们将在稍后的文章中探讨这一点。
训练数据和预处理
为了训练我们的语言模型,我们需要文本来学习。 幸运的是,我们不需要任何标签来训练语言模型,只需要原始文本。我从Google的BigQuery上提供的数据集中下载了15,000条冗长的reddit评论。我们的模型生成的文本听起来像reddit评论者(希望如此)! 但与大多数机器学习项目一样,我们首先需要进行一些预处理,以使我们的数据格式正确。
1.标记文本
我们有原始文本,但我们希望基于每个单词进行预测。 这意味着我们必须将我们的评论标记为句子,将句子标记为单词。我们可以用空格分割每个注释,但这不能正确处理标点符号。句子“he left!”应该是3个标记:“he”,“left”,“!”。 我们将使用NLTK的word_tokenize和sent_tokenize方法,这些方法为我们完成了这部分工作。
2.删除不常用的单词
我们文本中的大多数单词只会出现一两次。 删除这些不经常的单词是个好主意。 拥有庞大的词汇量会使我们的模型训练缓慢(我们将讨论为什么会这样做),并且由于我们没有很多这样的词语的上下文示例,我们将无法学习如何使用它们 无论如何正确。 这与人类的学习方式非常相似。 要真正理解如何恰当地使用单词,我们人类需要在不同的环境中看到它。
在我们的代码中,我们将词汇量限制为vocabulary_size最常见的单词(我设置为8000,但可以随意更改它)。 我们用UNKNOWN_TOKEN替换我们词汇表中未包含的所有单词。例如,如果我们的词汇表中没有包含“nonlinearities”这个词,那么句子“nonlineraties are important in neural networks”变成“UNKNOWN_TOKEN are important in neural networks”。UNKNOWN_TOKEN这个词将成为我们词汇的一部分,我们将像任何其他词一样预测它。 当我们生成新文本时,我们可以再次替换UNKNOWN_TOKEN,例如通过采用不在我们词汇表中的随机采样单词,或者我们可以生成句子,直到我们得到一个不包含未知标记的单词。
3.预先设置特殊的开始和结束标记
我们还想知道哪些单词倾向于开始和结束一个句子。 为此,我们预先添加一个特殊的SENTENCE_START标记,并为每个句子添加一个特殊的SENTENCE_END标记。这允许我们问:鉴于第一个标记是SENTENCE_START,可能的下一个单词(句子的实际第一个单词)是什么?
4.构建训练数据矩阵
我们的递归神经网络的输入是向量,而不是字符串。 因此,我们在单词和索引之间创建映射,index_to_word和word_to_index。例如,单词“friendly”可以在索引2001处。训练示例x可以看起来像[0,179,341,416],其中0对应于SENTENCE_START。相应的标签y为[179,341,416,1]。请记住,我们的目标是预测下一个单词,因此y只是移动了一个位置的x向量,最后一个元素是SENTENCE_END标记。换句话说,对上面的字179的正确预测将是341,即实际的下一个字。
vocabulary_size = 8000
unknown_token = "UNKNOWN_TOKEN"
sentence_start_token = "SENTENCE_START"
sentence_end_token = "SENTENCE_END"
#读取数据并附加SENTENCE_START和SENTENCE_END标记
print("Reading CSV file...")
with open('data/reddit-comments-2015-08.csv', 'rb') as f:
reader = csv.reader(f, skipinitialspace=True)
reader.next()
#将完整的comments拆分成sentences
sentences = itertools.chain(*[nltk.sent_tokenize(x[0].decode('utf-8').lower()) for x in reader])
#追加SENTENCE_START和SENTENCE_END
print("Parsed %d sentences." % (len(sentences)))
#将sentences标记为words
tokenized_sentences = [nltk.word_tokenize(sent) for sent in sentences]
#计算单词频率
word_freq = nltk.FreqDist(itertools.chain(*tokenized_sentences))
print("Found %d unique words tokens." % len(word_freq.items()))
#获取最常用的单词并构建index_to_word和word_to_index向量
vocab = word_freq.most_common(vocabulary_size-1)
index_to_word = [x[0] for x in vocab]
index_to_word.append(unknown_token)
word_to_index = dict([(w,i) for i,w in enumerate(index_to_word)])
print("Using vocabulary size %d." % vocabulary_size)
print("The least frequent word in our vocabulary is '%s' and appeared %d times." % (vocab[-1][0], vocab[-1][1]))
#用未知标记替换我们词汇表中没有的所有单词
for i, sent in enumerate(tokenized_sentences):
tokenized_sentences[i] = [w if w in word_to_index else unknown_token for w in sent]
print("\nExample sentence: '%s'" % sentences[0])
print("\nExample sentence after Pre-processing: '%s'" % tokenized_sentences[0])
#创建训练数据
X_train = np.asarray([[word_to_index[w] for w in sent[:-1]] for sent in tokenized_sentences])
y_train = np.asarray([[word_to_index[w] for w in sent[1:]] for sent in tokenized_sentences])
以下是我们文本中的实际训练示例:
x:
SENTENCE_START what are n't you understanding about this ? !
[0, 51, 27, 16, 10, 856, 53, 25, 34, 69]
y:
what are n't you understanding about this ? ! SENTENCE_END
[51, 27, 16, 10, 856, 53, 25, 34, 69, 1]
构建RNN
有关RNN的一般概述,请参阅本教程的第一部分。
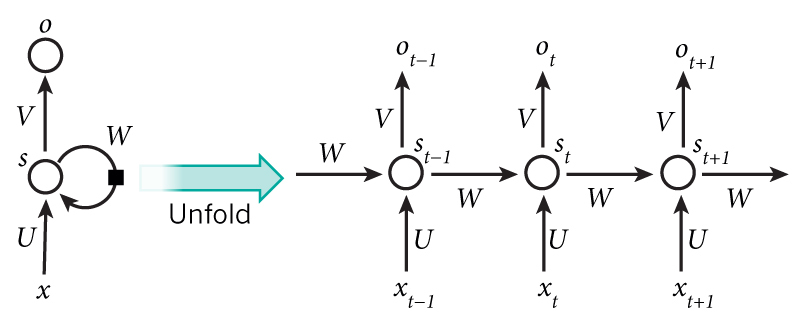
A recurrent neural network and the unfolding in time of the computation involved in its forward computation.
让我们具体一点,看看我们语言模型的RNN是什么样的。输入x将是一系列单词(就像上面打印的示例一样),每个 是一个单词。但还有一件事:由于矩阵乘法如何工作,我们不能简单地使用单词索引(如36)作为输入。相反,我们将每个单词表示为大小为vocabulary_size的单热矢量。例如,具有索引36的单词将是所有0的向量和位置36处的1。因此,每个 将成为一个向量,x将是一个矩阵,每行代表一个单词。 我们将在神经网络代码中执行此转换,而不是在预处理中执行此转换。我们的网络o的输出具有类似的格式。 每个 是vocabulary_size元素的向量,并且每个元素表示该单词是句子中的下一个单词的概率。
让我们从教程的第一部分回顾一下RNN的等式: