爬虫:
将数据从网上提取下来并保存的过程,分为三大步
下载源码
把包含数据的源码下载下来,需要学习requests模块的使用,这个过程是爬虫的难点,因为有反爬虫的措施、动态登录验证等
数据提取
从网页源码里面提取出需要的数据,这一步相对,简单只需要学习相关的库的使用,例如BueatifulSoup、re正则
数据保存
将提取到的数据储存下来,例如保存到Mysql数据库,只需要利用Mysql的python驱动模块pymsql连接到数据库,最简单
学习的过程由简到难,数据提取-->数据保存-->下载源码
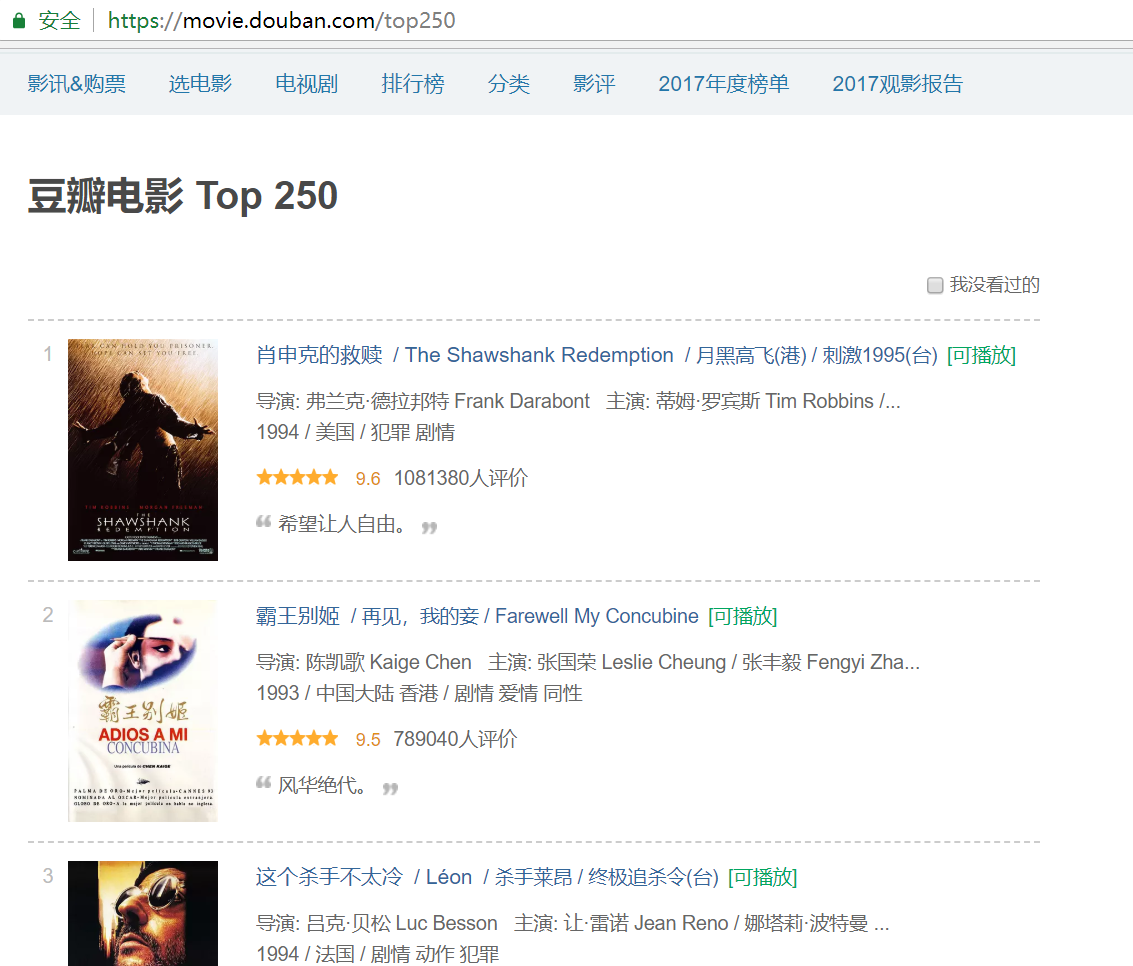
第一个简单例子选择简单的没有反爬措施的网页:豆瓣电影Top250 来获取网站源码
页面:
代码:
# 导入requests模块
import requests
# 获取要爬取的网页的url
url = 'https://movie.douban.com/top250'
# 用get()方法请求下载网页
rsp = requests.get(url)
# text属性返回网页源码的内容
text = rsp.text
# 打印源码
print(text)
通过以上代码,就可获取到包所需要的数据的网页源码